| title | emoji | type | topics | published | published_at | publication_name | |
|---|---|---|---|---|---|---|---|
具体例で理解するベイズ更新 |
📚 |
tech |
|
true |
2024-02-25 22:00 |
ukiyocreate_dev |
『ウェブ最適化ではじめる機械学習』なる書籍を読み始めたが、難しくて第一章でつまずいてしまった。数時間考えてようやく曖昧に理解できた気がするので、現時点での自分なりの理解をざっくりと残す。 https://amzn.asia/d/4DmHmxu
という計算式に従って、事後分布を繰り返し更新することで、有用な確率分布を得る手法のこと。 ここで、$\theta$は推論したい未知のパラメータに相当する確率変数を、$D$は実際に観測されたデータを表す。
上記の数式だけではいまいちイメージがつかない方も多いと思うので、具体例を見ながらこの数式の意味を理解してみる。
無作為に抽出した対象者に対して
- ある感染症の検査をおこない、1回陽性という結果が出た場合の感染確率を計算する。
- ある感染症の検査をおこない、2回陽性という結果が出た場合の感染確率を計算する。
具体例の中で出てくるデータはすべて適当に設定したものである。 また、今回の具体例では無作為に検査の対象者を抽出することを想定しているが、実際の社会では「周りの人が感染した」とか「初期症状が出ている」といった理由で検査を受けにいく人が大半なので、今回の具体例を現実に素直に適応することは難しい。
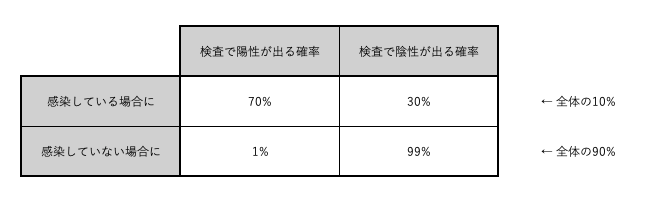
- 世界中でこの感染症に感染している人は10%、感染していない人は90%いる。
- 感染している人の中で、陽性反応が出る人は70%、陰性反応が出る人は30%いる。
- 感染していない人の中で、陽性反応が出る人は1%、陰性反応が出る人は99%いる。
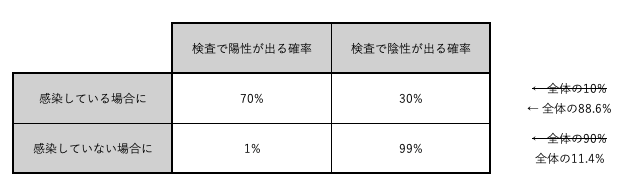
上記の事前に分かっているデータを表にまとめる。
完成した表は以下の画像のようになる。
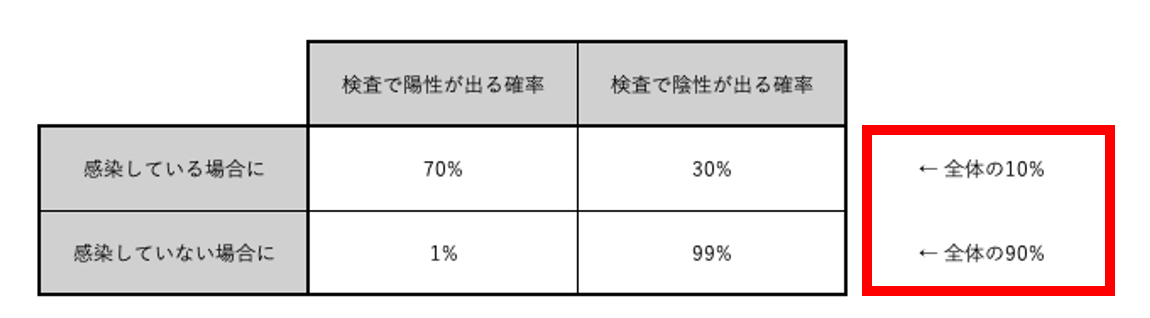
STEP1で作成した表は、感染の有無が確定しているときの検査の結果の条件付き確率を示しているが、実際の世界では検査の結果が分かっているときの感染の有無の条件付き確率の方が有用なことが多い。 そこで、STEP1の表の行と列を入れ替えて、検査の結果が確定しているときの条件付き確率を表にまとめる。
前準備として、STEP1でまとめたそれぞれの条件付き確率を同時確率に変換する。 例えば「感染している場合に検査で陽性が出る条件付き確率」に「感染している確率」をかけることで、「感染している、かつ、検査で陽性が出る同時確率」を求めることができる。
STEP1の表によると、「感染している場合に検査で陽性が出る条件付き確率」は70%、「感染している人の割合」は10%である。
何も情報がない状態では「感染している人の割合」と「対象者の感染している確率」は同じであると考えて良いので、「対象者の感染している確率」も10%である。
したがって、「感染している、かつ、検査で陽性が出る同時確率」は70% × 10% = 7%となる。
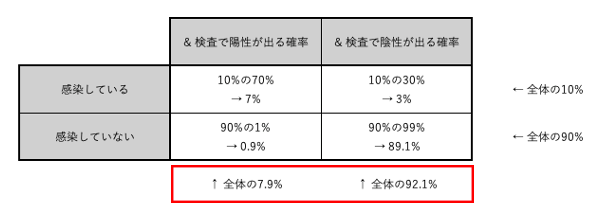
同様の処理を他の3つの条件付き確率に対してもおこなうと、下の画像のようになる。
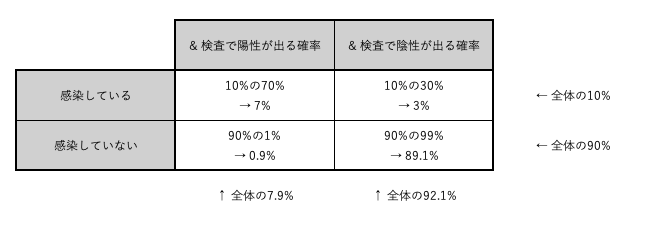
例えば、「検査で陽性が出る確率」は7 + 0.9 = 7.9%、「検査で陽性が出る、かつ、感染している確率」は7%なので、「検査で陽性が出た場合に感染している確率」は7 ÷ 7.9 = 0.8860...で約88.6%となる。
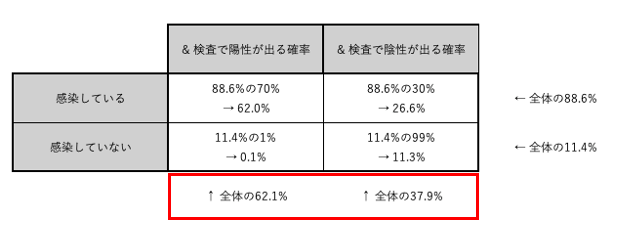
同様の処理を他の3つの同時確率に対してもおこなうと、下の画像のようになる。
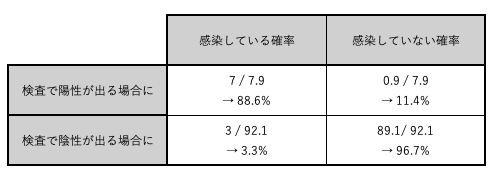
もし1回目の検査で陽性が出た場合、STEP2-2で作成した表から、感染している確率は88.6%、感染していない確率は11.4%であることがわかる。
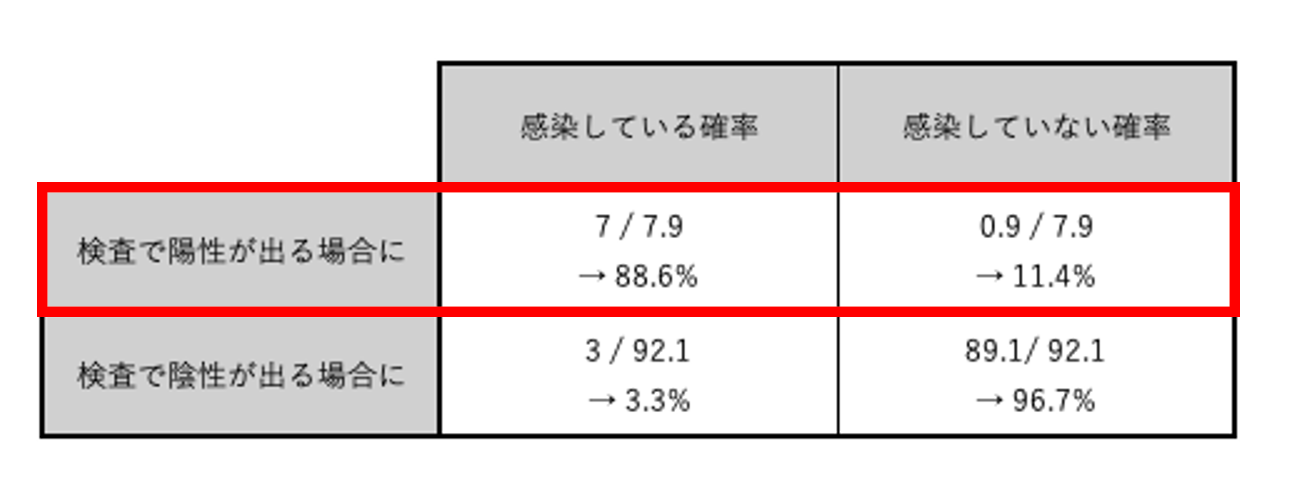
検査結果を見る前の対象者の感染確率は10%であったが、陽性という検査結果が1度出たことで、感染している確率は88.6%へと跳ね上がった。
次に、2回目の検査で陽性という結果が出た場合の感染確率を求める。 基本的にはSTEP1 ~ 3の処理を再度繰り返せばよい。ただし、STEP1で使用した対象者の感染確率はSTEP3で求めた感染確率に置き換える。
つまり、これが


つまり2回陽性という検査結果が出た場合、感染している確率は99.8%となる。
| 検査結果 | 感染している確率 |
|---|---|
| 検査0回目 | 10% |
| 検査1回目(陽性) | 88.6% |
| 検査2回目(陽性) | 99.8% |
$$ P(\theta \mid D) = \frac{P(D \mid \theta) \cdot P(\theta)}{P(D)} $$ という計算式の各項が具体例のどのデータと対応するかを確認する。
 例えば$P(D=陽性 \mid \theta=感染している) = 70%$で、$P(D=陰性 \mid \theta=感染していない) = 99%$となる。
例えば$P(D=陽性 \mid \theta=感染している) = 70%$で、$P(D=陰性 \mid \theta=感染していない) = 99%$となる。

具体例を用いて、計算式の各項が何を指しているかを確認したので、もう一度計算式に戻って、「ある感染症の検査をおこない、1回陽性という結果が出た場合の感染確率」を計算してみる。
「ある感染症の検査をおこない、1回陽性という結果が出た場合の感染確率」は$P(\theta=感染 \mid D=陽性)$であり、ベイズ更新の式より、
事前に分かっているデータより
$$ P(D=陽性 \mid \theta=感染)=0.7 \ P(\theta=感染)=0.1 $$ である。
また$P(D)$はベイズの定理を使って
$$ \begin{aligned} P(D=陽性) &= P(D=陽性 \cap \theta=感染している) + P(D=陽性 \cap \theta=感染していない) \ &= P(D=陽性 \mid \theta=感染) \cdot P(\theta=感染) + P(D=陽性 \mid \theta=感染していない) \cdot P(\theta=感染していない) \ &= 0.7 \cdot 0.1 + 0.01 \cdot 0.9 \ &= 0.079 \end{aligned} $$ である。 これらの結果を上のベイズ更新の式に代入して、
つまり、1回陽性という結果が出た場合の感染確率が88.6%であるということが計算式のみから導かれた。
数式から具体例に行ってまた数式に戻ると理解しやすい。
https://www.youtube.com/watch?v=6MAu12ask3Q
もう一つ記事を書きました。 https://zenn.dev/ukiyocreate_dev/articles/5a6e9182f1ebba