The Alexa Voice Service (AVS) enables developers to integrate Alexa directly into their products, bringing the convenience of voice control to any connected device. AVS provides developers with access to a suite of resources to quickly and easily build Alexa-enabled products, including APIs, hardware development kits, software development kits, and documentation.
The AVS Device SDK provides C++-based (11 or later) libraries that leverage the AVS API to create device software for Alexa-enabled products. It is modular and abstracted, providing components for handling discrete functions such as speech capture, audio processing, and communications, with each component exposing the APIs that you can use and customize for your integration. It also includes a sample app, which demonstrates the interactions with AVS.
You can set up the SDK on the following platforms:
- Linux or macOS
- Raspberry Pi (Raspbian Stretch)
You can also prototype with a third party development kit
Or if you prefer, you can start with our SDK API Documentation.
Watch this tutorial to learn about the how this SDK works and the set up process.

This diagram illustrates the data flows between components that comprise the AVS Device SDK for C++.
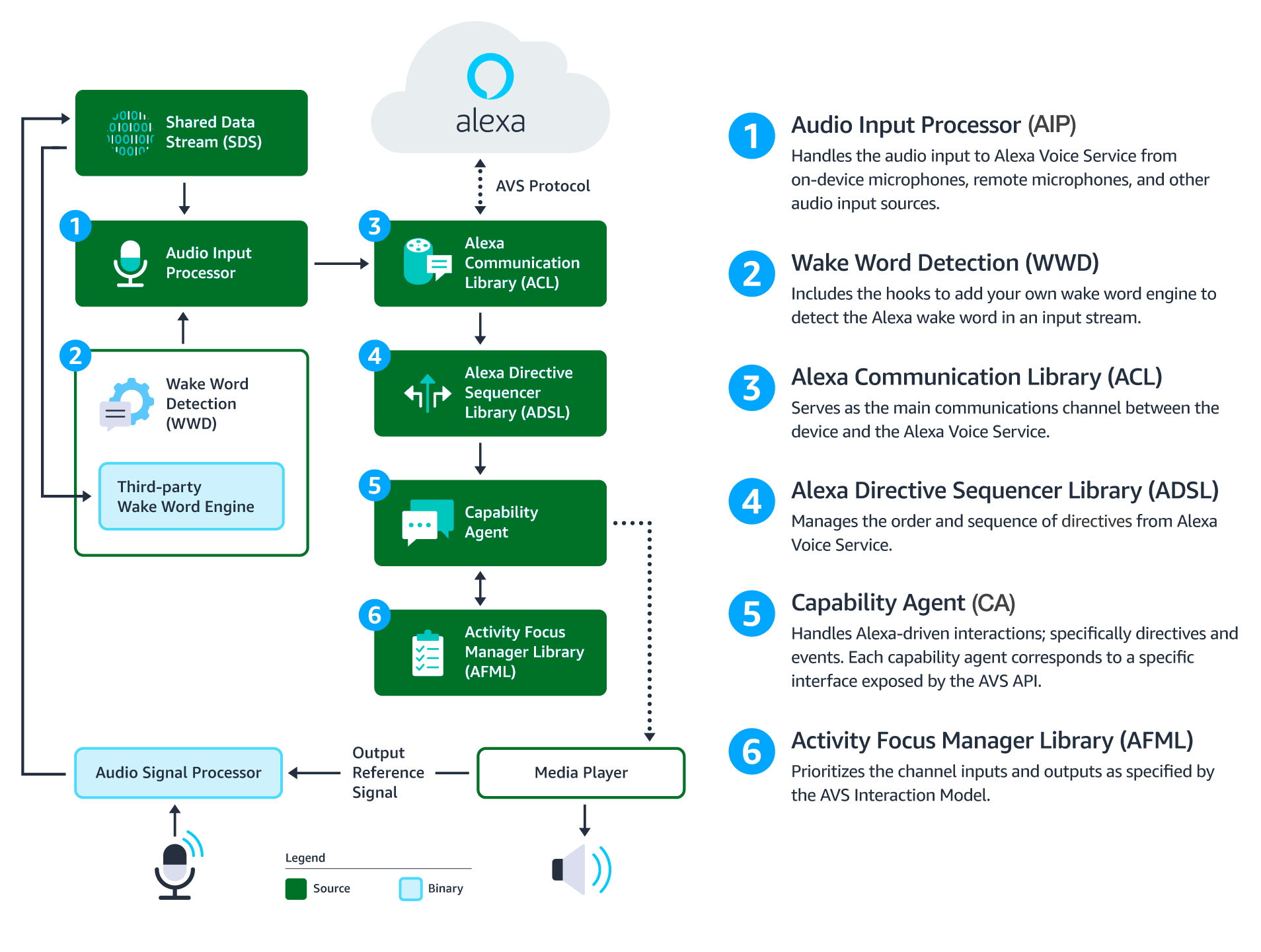
Audio Signal Processor (ASP) - Third-party software that applies signal processing algorithms to both input and output audio channels. The applied algorithms are designed to produce clean audio data and include, but are not limited to acoustic echo cancellation (AEC), beam forming (fixed or adaptive), voice activity detection (VAD), and dynamic range compression (DRC). If a multi-microphone array is present, the ASP constructs and outputs a single audio stream for the array.
Shared Data Stream (SDS) - A single producer, multi-consumer buffer that allows for the transport of any type of data between a single writer and one or more readers. SDS performs two key tasks:
- It passes audio data between the audio front end (or Audio Signal Processor), the wake word engine, and the Alexa Communications Library (ACL) before sending to AVS
- It passes data attachments sent by AVS to specific capability agents via the ACL
SDS is implemented atop a ring buffer on a product-specific memory segment (or user-specified), which allows it to be used for in-process or interprocess communication. Keep in mind, the writer and reader(s) may be in different threads or processes.
Wake Word Engine (WWE) - Software that spots wake words in an input stream. It is comprised of two binary interfaces. The first handles wake word spotting (or detection), and the second handles specific wake word models (in this case "Alexa"). Depending on your implementation, the WWE may run on the system on a chip (SOC) or dedicated chip, like a digital signal processor (DSP).
Audio Input Processor (AIP) - Handles audio input that is sent to AVS via the ACL. These include on-device microphones, remote microphones, an other audio input sources.
The AIP also includes the logic to switch between different audio input sources. Only one audio input source can be sent to AVS at a given time.
Alexa Communications Library (ACL) - Serves as the main communications channel between a client and AVS. The ACL performs two key functions:
- Establishes and maintains long-lived persistent connections with AVS. ACL adheres to the messaging specification detailed in Managing an HTTP/2 Connection with AVS.
- Provides message sending and receiving capabilities, which includes support JSON-formatted text, and binary audio content. For additional information, see Structuring an HTTP/2 Request to AVS.
Alexa Directive Sequencer Library (ADSL): Manages the order and sequence of directives from AVS, as detailed in the AVS Interaction Model. This component manages the lifecycle of each directive, and informs the Directive Handler (which may or may not be a Capability Agent) to handle the message.
Activity Focus Manager Library (AFML): Provides centralized management of audiovisual focus for the device. Focus is based on channels, as detailed in the AVS Interaction Model, which are used to govern the prioritization of audiovisual inputs and outputs.
Channels can either be in the foreground or background. At any given time, only one channel can be in the foreground and have focus. If multiple channels are active, you need to respect the following priority order: Dialog > Alerts > Content. When a channel that is in the foreground becomes inactive, the next active channel in the priority order moves into the foreground.
Focus management is not specific to Capability Agents or Directive Handlers, and can be used by non-Alexa related agents as well. This allows all agents using the AFML to have a consistent focus across a device.
Capability Agents: Handle Alexa-driven interactions; specifically directives and events. Each capability agent corresponds to a specific interface exposed by the AVS API. These interfaces include:
- SpeechRecognizer - The interface for speech capture.
- SpeechSynthesizer - The interface for Alexa speech output.
- Alerts - The interface for setting, stopping, and deleting timers and alarms.
- AudioPlayer - The interface for managing and controlling audio playback.
- Notifications - The interface for displaying notifications indicators.
- PlaybackController - The interface for navigating a playback queue via GUI or buttons.
- Speaker - The interface for volume control, including mute and unmute.
- System - The interface for communicating product status/state to AVS.
- TemplateRuntime - The interface for rendering visual metadata.
- Review the AVS Terms & Agreements.
- The earcons associated with the sample project are for prototyping purposes only. For implementation and design guidance for commercial products, please see Designing for AVS and AVS UX Guidelines.
- Please use the contact information below to-
- Contact Sensory for information on TrulyHandsFree licensing.
- Contact KITT.AI for information on SnowBoy licensing.
- IMPORTANT: The Sensory wake word engine referenced in this document is time-limited: code linked against it will stop working when the library expires. The library included in this repository will, at all times, have an expiration date that is at least 120 days in the future. See Sensory's GitHub page for more information.
Note: Features, updates, and resolved issues from previous releases are available to view in CHANGELOG.md.
v1.1 released 10/02/2017:
Enhancements
- Added a capability agent for Settings, which allows a client to notify Alexa of locale changes.
- Added a capability agent for PlaybackController, which exposes these transport controls: play, pause, next, and previous.
- Added
PlaylistParser, which is used to parse m3u and pls formatted playlists. - Added new unit tests for
AudioPlayer. - Refactored the Alerts capability agent to support named timers and reminders.
Bug Fixes
- Bug fix to address AIP getting stuck in the
LISTENINGorTHINKINGstate and refusing user input during a network outage. - Bug fix for the sample app crashing when it runs for more than 5 minutes following a network disconnect.
- Bug fix for user utterances being ignored after long Alexa TTS.
- Bug fix for GStreamer errors that appear on
SampleAppexit that result from accessing the pipeline before it has been setup. - Fix crash when playing URLs one after another.
- Bug fix for overrun in
AlertsRenderer. - SampleApp crashing when issuing "Alexa skip" command with iHeartRadio. (alexa#153)
HTTP2Transportnetwork thread triggering a join on itself.HTTP2Streamrequest handling truncating exception messages.AudioPlayerwas attempting an incorrect state transition fromSTOPPEDtoPLAYINGthrough aplaybackResumed.
Known Issues
- Native components for the following capability agents are not included in this release:
Speaker,TemplateRuntime, andNotifications ACL's asynchronous receipt of audio attachments may manage resources poorly in scenarios where attachments are received but not consumed.- When an
AttachmentReaderdoes not deliver data for prolonged periods,MediaPlayermay not resume playing the delayed audio. - Without the refresh token in the JSON file, the sample app crashes on start up.
- Alerts do not play after restarting the device.
- Alexa's responses are cut off by about half a second when asking "What's up" or barging into an active alarm to ask the time.
- Switching from Kindle to Amazon Music after pausing and resuming Kindle doesn't work.
- Pause/resume on Amazon Music causes entire song to start over.
- Stuck in listening state if
ExpectSpeechcomes in when the microphone has been turned off. - Pausing and resuming Pandora causes stuttering, looped audio.
- Audible features are not fully supported.
Recognizeevent after regaining network connection and during an alarm going off can cause client to get stuck inRecognizingstate.- Three Alerts integration tests fail:
handleMultipleTimersWithLocalStop,AlertsTest.UserLongUnrelatedBargeInOnActiveTimer,AlertsTest.handleOneTimerWithVocalStop MediaPlayerTest.testSetOffsetSeekableSourceunit test fails intermittently on Linux.