Düzenli ifadeler, özellikle programlama yaparken verilerin aradığımız niteliklere göre sınırlandırılması ve sınırlandırlan verilerin istenildiği şekilde çekilmesi adına bizlere yardım eder.
Ayrıca anlatımlarda; düzenli ifadelerin daha önce temel linux eğitimde değinmiş olduğumuz joker karakterleri de içerisinde barındırdığını ve joker karakterlere benzer ancak daha kapsamlı seçenekler sunduğunu da görmüş olacağız. Lafı daha fazla uzatmadan örnekler üzerinden düzenli ifadelerin işlevlerine göz atalım.
Başlamadan evvel, burada yer alan bilgilerin ve kullanımların tam anlaşılabilmesi için buradaki örneklerin haricinde sizlerin de pek çok alıştırma yapması gerektiğini lütfen unutmayın. Bilgilerin kalıcı olması adına lütfen buradaki örneklerin dışına çıkarak, bolca alıştırma yapın.
Kullanımı, iki köşeli parantez arasına ulaşmak istediğiniz hedefteki ayırt edici karakterleri yazmak üzerinedir.
Örnek olması açısından "dosya" isimli belgelerden sadece sonunda 2,3,4 olanları kapsayacak bir komut olması için konsola ls -l [234] komutunu verdim.

Bir örnek daha verelim.
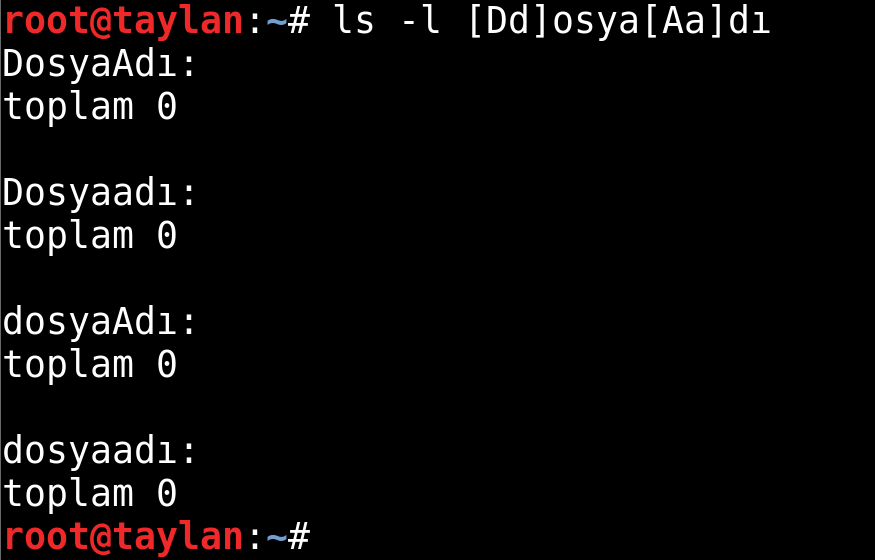
[Dd]osya[Aa]dı şeklinde bir belirtme; DosyaAdı, Dosyaadı, dosyaAdı, dosyaadı şeklindeki bütün isimleri kapsayacaktır. Bu sayede ilgili dosyalar için tüm küçük büyük harf kombinasyonu kolaylıkla sağlanmış olur.
Ayrıca kullanım şekillerine çok fazla örnek verilebilir ancak burada birkaç örnek daha vererek keşfi size bırakıyorum.
Not : Burada belirtilen x y z temsili değerleri ifade etmektedir !
[0-9] : 0'dan 9'a kadar olan rakamları kapsar.

[x,y,z] : belirtilen değerlerle eşleşenleri basar.

[x-z] : x ile z değerleri arasındaki karakterlerle eşleşir.

[xyz] : belirtilen değerlerle eşleşenleri basar.

[!xyz] : Belirtilen karakterlerin dışındakileri diğer tüm karakterleri basar.

[!x-z] : Verilen x ile z değeri arasındaki değerler haricindeki karakterler basar.

Örnek olması açısında "dosya" isimli belgelerden sadece sonunda 2,3,4 olanları kapsayacak bir komut olması için konsola ls -l [234] komutunu verdim.
Bir örnek daha verelim.
[Dd]osya[Aa]dı şeklinde bir belirtme; DosyaAdı, Dosyaadı, dosyaAdı, dosyaadı şeklindeki bütün isimleri kapsayacaktır. Bu sayede ilgili dosyalar için tüm küçük büyük harf kombinasyonu kolaylıkla sağlanmış olur.
Ayrıca kullanım şekillerine çok fazla örnek verilebilir ancak burada birkaç örnek daha vererek keşfi size bırakıyorum.
Not : Burada belirtilen x y z temsili değerleri ifade etmektedir !
[0-9] : 0'dan 9'a kadar olan rakamları kapsar.
[x,y,z] : belirtilen değerlerle eşleşenleri basar.
[x-z] : x ile z değerleri arasındaki karakterlerle eşleşir.
[xyz] : belirtilen değerlerle eşleşenleri basar.
[!xyz] : Belirtilen karakterlerin dışındakileri diğer tüm karakterleri basar.
[!x-z] : Verilen x ile z değeri arasındaki değerler haricindeki karakterler basar.
Kıvırcık parantez de köşeli paranteze benzer şekilde içerisine girilen ifadelere göre çalışır.
Çalışma yapısını anlamak için aşağıdaki örneklere göz atabilirsiniz.
{x,y,z} : içerisinde virgüller ile ayrılmış ifadeleri tek tek basar.


{x..y} : iki ifade arasına koyulan iki nokta(..) sayesinde otomatik olarak başlangıç karaterinden son karaktere gelinceye kadar sıralı çıktılar elde edebiliyoruz. Tam kullanımı {başlangıç_ifadesi..bitiş_ifadesi} şeklindedir.
Kullanım örnekleri; Rakam ya da harflerin istenildiği yerden başlayıp istenildiği kısıma kadar sıralanması sağlanabilir.
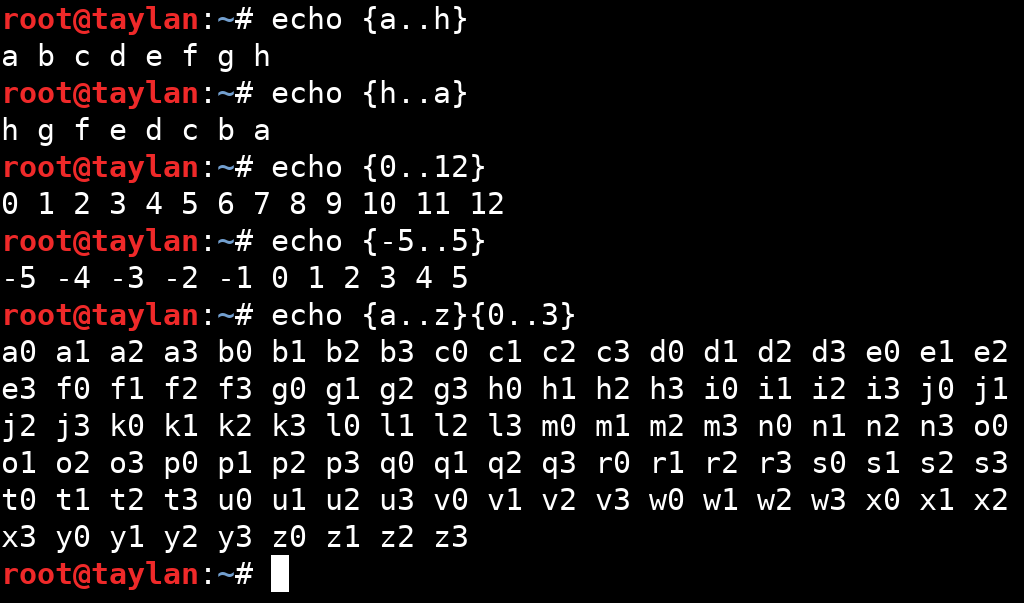
Üstelik bu sıralama birer birer artmak zorunda da değil. İstenilen aralıkta artışın yapılması {başlangıç_ifadesi..bitiş_ifadesi..artış_aralığı} şeklindeki kullanım ile sağlanabilir.

Noktanın bulunduğu yere gelebilecek herhangi bir karakteri temsil eder.
Satır başını temsil eder.
Satır sonunu temsil eder.
Kümede belirtilen karakterler haricindeki tüm karakterleri kapsar. Ayrıca şapka işareti yerine ünlem işareti(!) de kullananabiliriz.
Şimdi birkaç farklı örnek ile kullanımı ele alalım;
Örneğin sonunda rakam bulunan dosyaları listelemek istemezsek komutumuzu ls *[^0-9] şeklinde girebiliriz. Bu sayede ls komutu başlangıcı ne olursa olsun sonunda rakam yer alan dosyaları liste dışı bırakıyor.

Daha net anlaşılması adına bir örnek daha; * işaretinin sona koyulması ile hariç tutma durumu, başlangıcında rakam yer alan dosyalar için de uygulanabilir.
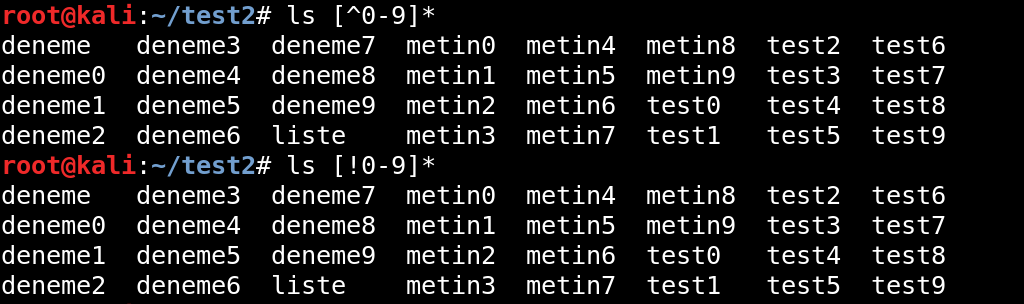
Ayrıca örneklerde ele aldığımız hariç tutma durumunu, ihtiyacımıza göre rakamlar yerine harfler ya da özel karakterler için de kullanabiliyoruz.
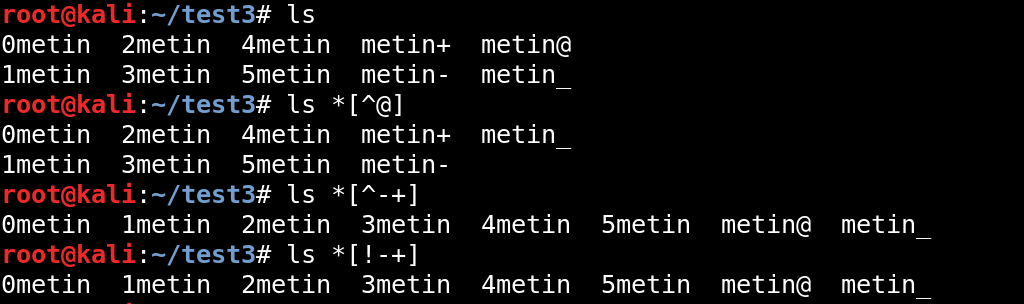
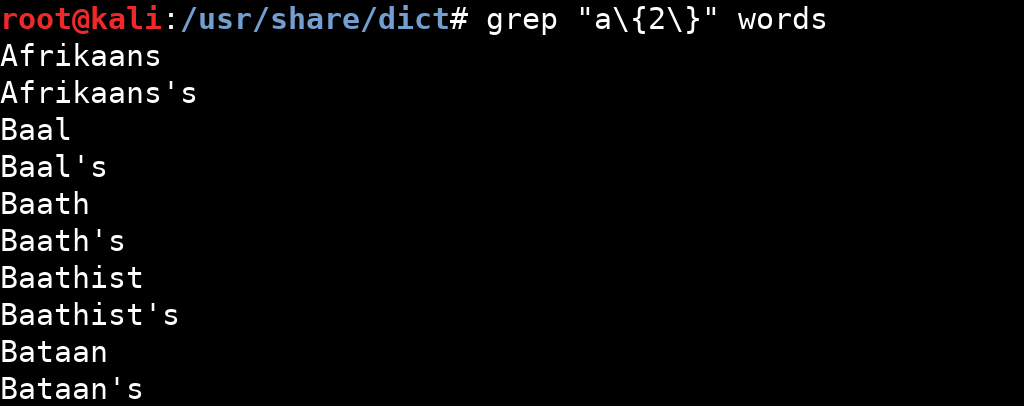
Kendisinden önceki karakterin tam olarak x kez tekrar edildiğiniz belirtir.
Örneğin 2 kez a harfinin geçtiği tüm kelimeleri listelemek istersek, grep komutu yardımı ile a\{2\} düzenli ifadesini kullanabiliriz.
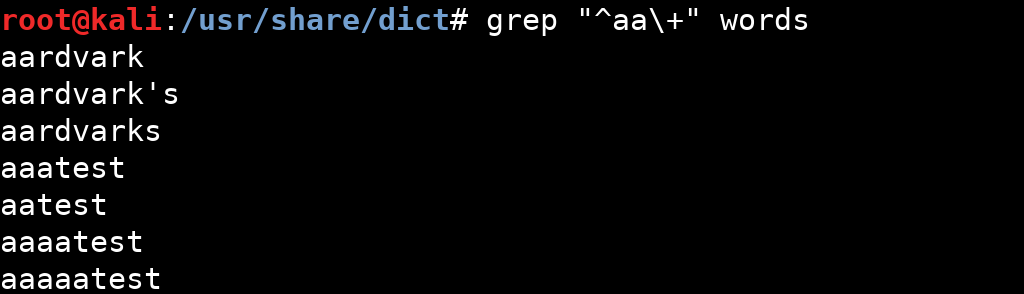
Kendisinden önceki karakterin en az x kez tekrar edildiğiniz belirtir.

Kendisinden önceki karakterin 1 ya da daha fazla olduğunu, diğer bir deyişle en az 1 kez bulunduğu durumları belirtir.
Kendisindne önceki karakterin 0 ya da 1 kez oldğunu belirtir.
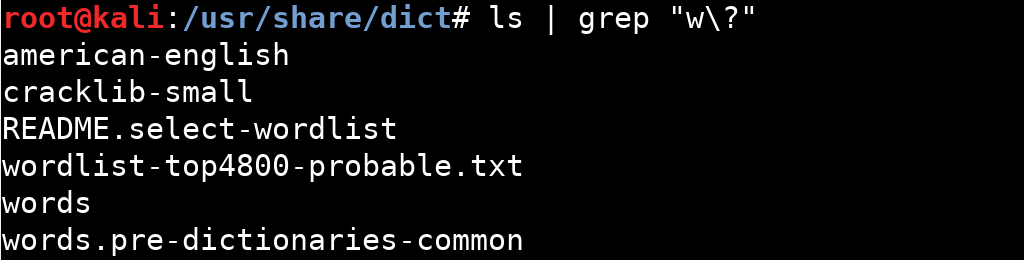
Kendisindne bir önceki veya bir sonraki karaktere denk gelir.
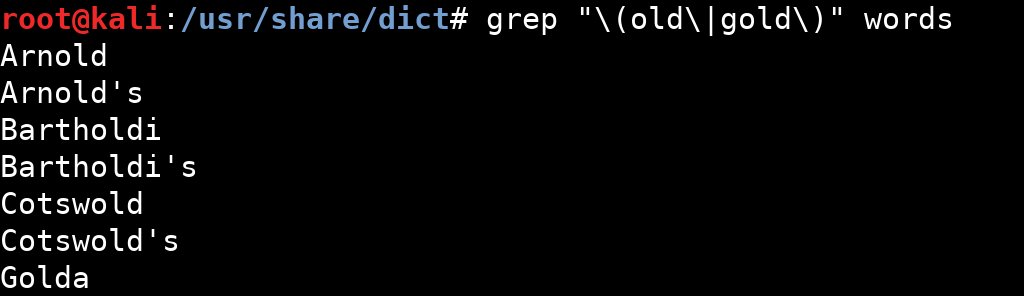
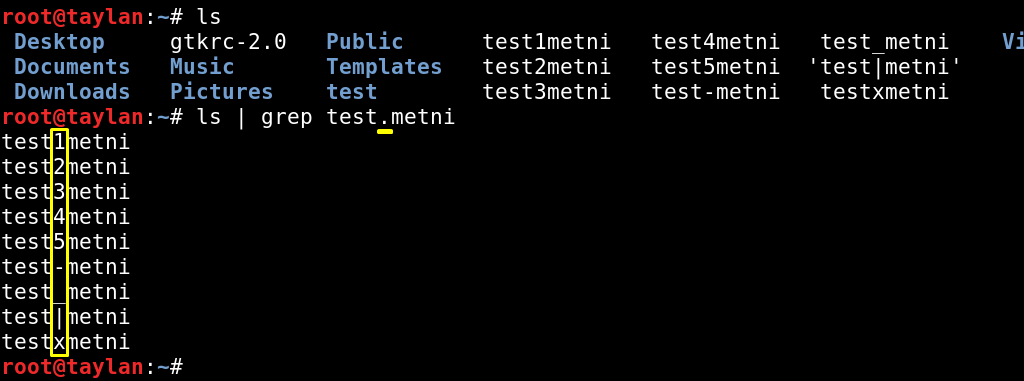
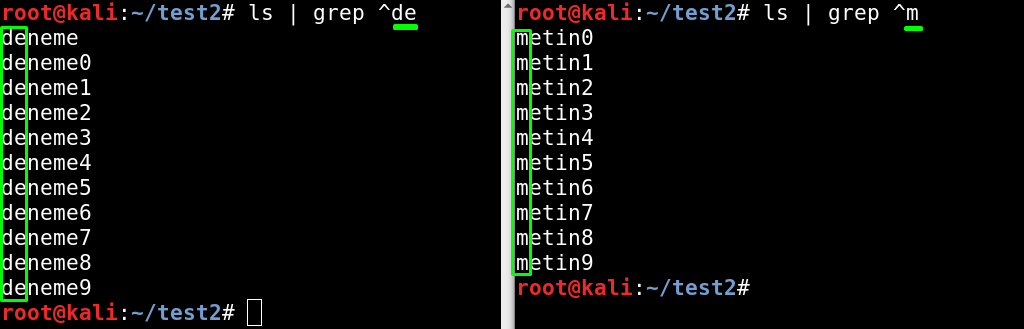
xyz ile başlayan satırları kapsar.
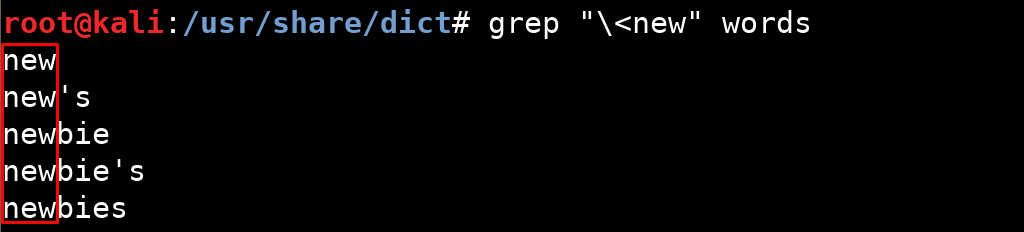
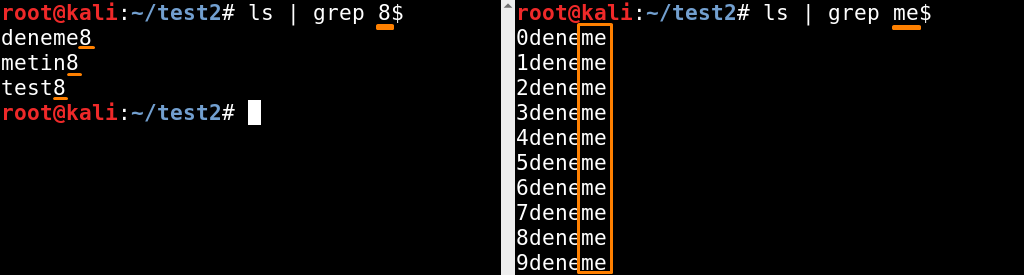
xyz ile biten satırları kapsar.
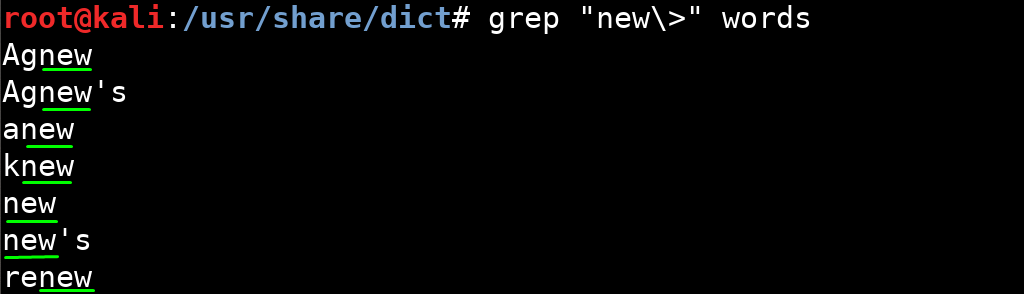
Özel karakterlerin normal karakterler olarak algılanmasını sağlarlar.

Kullanım Örnekleri
Karakter sınıflarını; bir önceki kısımda ele aldığımız düzenli ifadelerin sıklıkla kullanılan özelliklerinin kalıplaşmış kısayol hali olarak düşünebilirsiniz. Bu ne demek oluyor ?
Açıklayalım;
Örneğin biz yalnızca noktalama işaretleri içeren verileri almak istediğimizde düzenli ifadeler ile bunları tek tek tanımlamamız gerekiyorken, bunun yerine daha önceden tanımlanıp sınıf haline getirilmiş olan punct karakter sınıfını kullanabiliriz.

Kısacası karakter sınıfları sık kullanılan filtreleme seçeneklerinin bir araya getirildiği düzenli ifade demetleridir. Eğer filtreleyeceğimiz veri, bu sık kullanılan düzenli ifade demetine dahil ise, uzun uzadıya yazmak yerine yazdığımız kodun daha derli toplu olması adına karakter sınıfını kullanabiliriz. Ancak filtreleyeceğimiz veri çok daha spesifik ise düzenli ifadeleri kullanmamız gerekir.
Anlatmak istediğim konuyu en iyi örnekler açıklayacaktır.
Öncelikle kullanabileceğimiz temel sınıflara aşağıdaki tablo ile göz atalım.
| Sınıf | Özellik |
|---|---|
| digit | Rakamlar. bu‘ (0-9) ’ile aynıdır. |
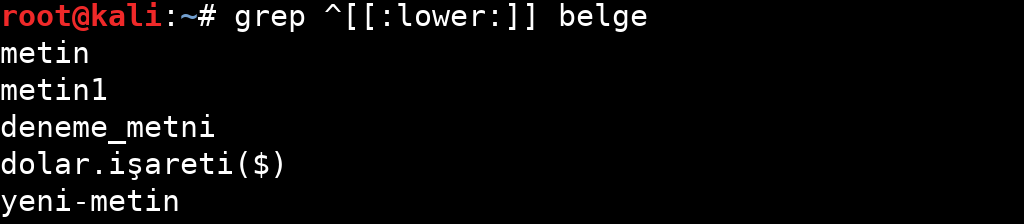
| lower | Küçük karakterler. bu‘ (a-z) ’ile aynıdır. |
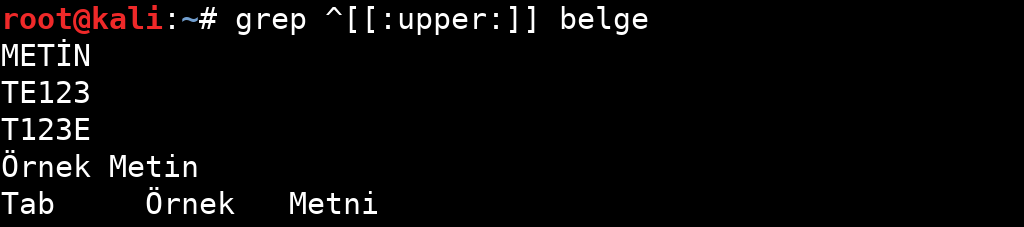
| upper | Büyük karakterler. bu‘ (A-Z) ’ile aynıdır. |
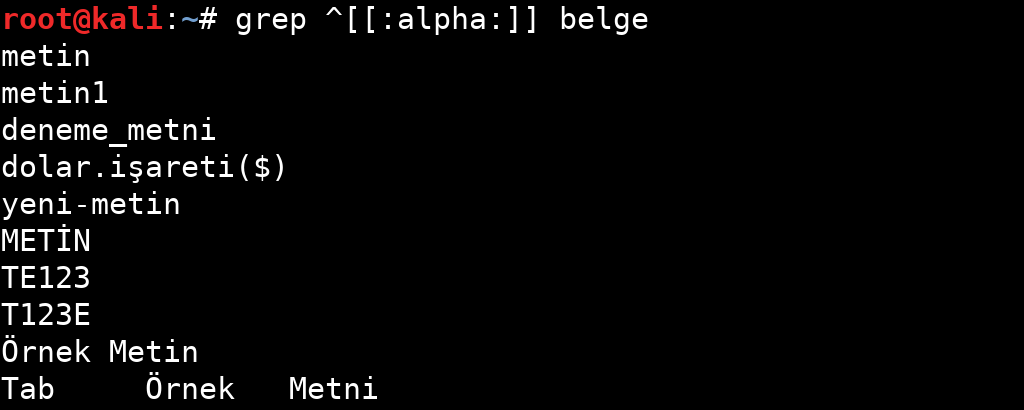
| alpha | Alfabetik karakterler: ‘ [: lower:] ’ ve ‘ [: upper:] ’; bu‘ [A-Za-z] ’ile aynıdır. |
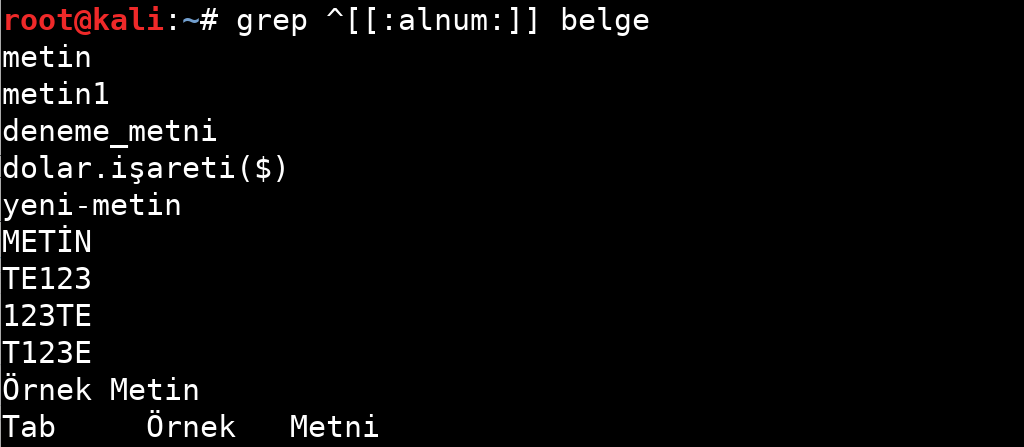
| alnum | Alfanümerik karakterler: ‘ [: alpha:] ’ ve ‘ [: digit:] ’; bu‘ [0-9A-Za-z] ’ile aynıdır. |
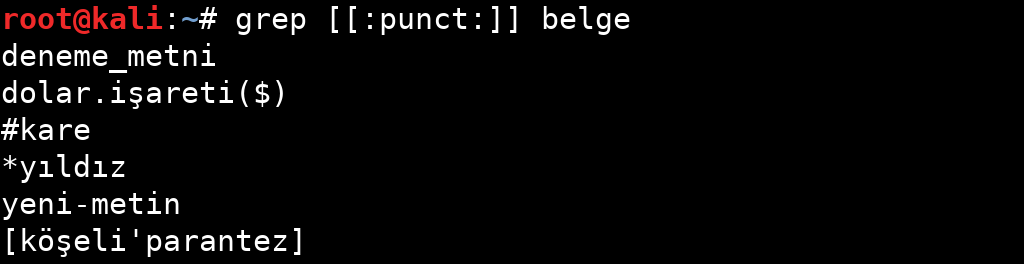
| punct | Noktalama işaretleri. (``! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { |
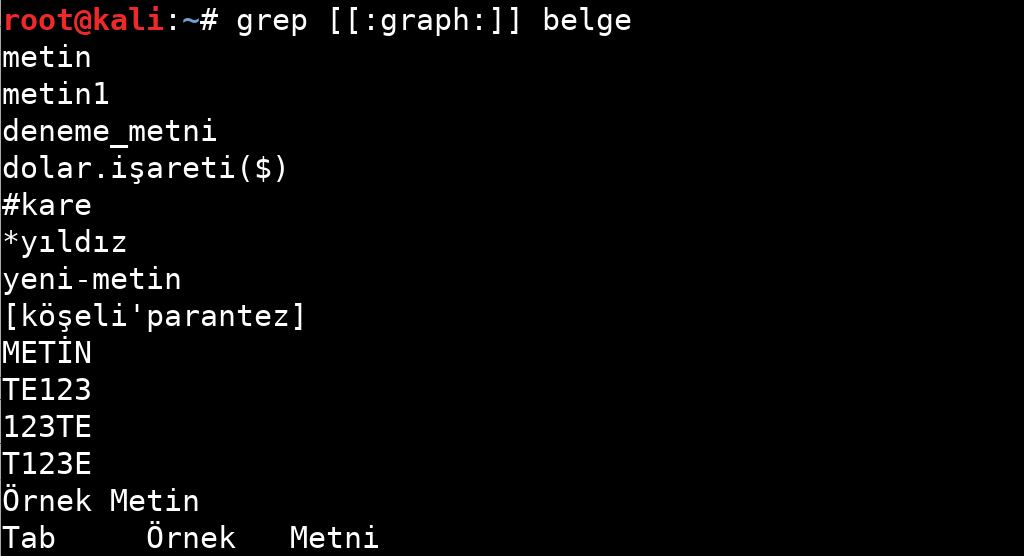
| graph | Grafiksel karakterler: ‘ [: alnum:] ’ ve ‘ [: punct:] ’. |
| blank | Boş karakterler: boşluk(space) ve tab içerenler. |
| space | Herhangi bir boşluk karakteri: tab, yeni satır, dikey tab, space vb.. |
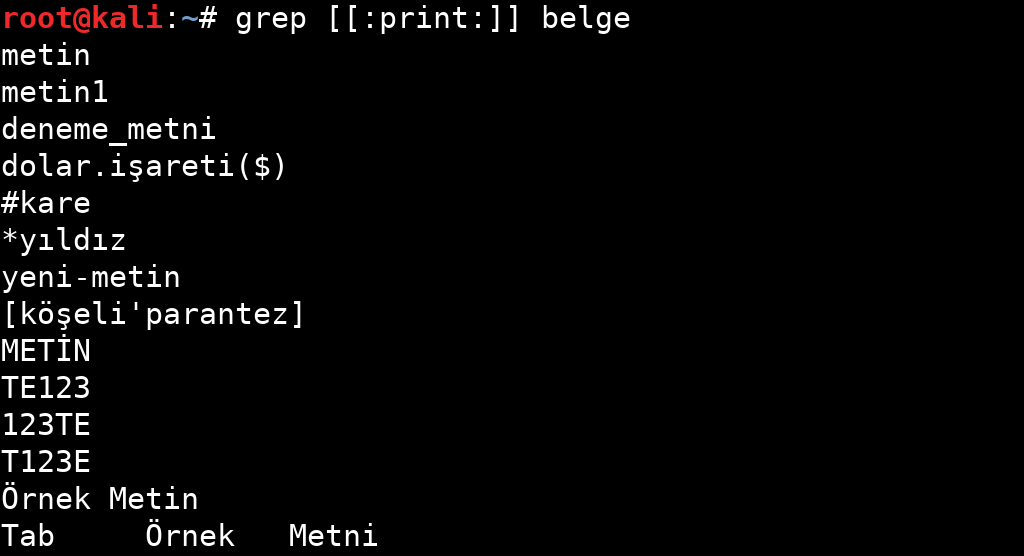
| Yazdırılabilir karakterler: ‘ [: alnum:] ’, ‘ [: punct:] ’ ve boşluk(space). | |
| xdigit | Onaltılı sayı sistemi: 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f. |
Tablodan da anlayacağınız gibi belirli özellikler için sınırlandırılmış ifadeler bulunuyor. Bu ifadelerin kullanım örneklerine aşağıdaki görsellerden bakabilirsiniz.