
RetinaNet has been formed by making two improvements over existing single stage object detection models (like YOLO and SSD): Feature Pyramid Networks for Object Detection, Focal Loss for Dense Object Detection.
Feature Pyramid Networks for Object Detection:
Pyramid networks have been used conventionally to identify objects at different scales. A Feature Pyramid Network (FPN) makes use of the inherent multi-scale pyramidal hierarchy of deep CNNs to create feature pyramids.
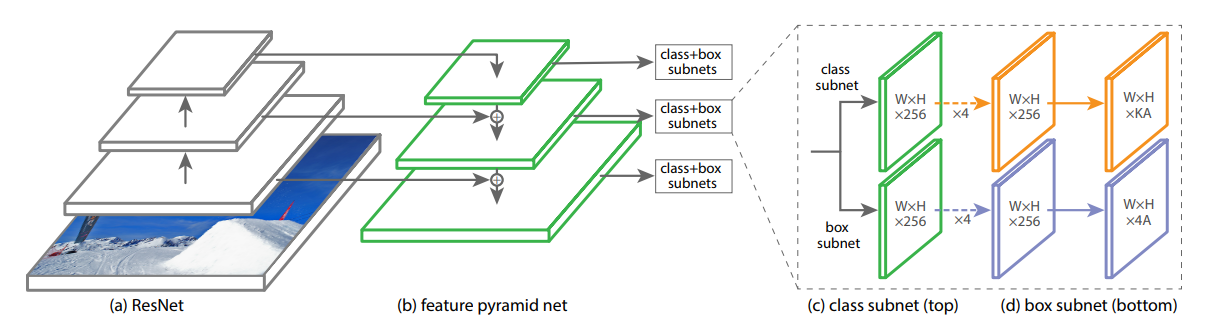
Focal Loss for Dense Object Detection:
Focal Loss is an improvement on cross-entropy loss that helps to reduce the relative loss for well-classified examples and putting more focus on hard, misclassified examples.
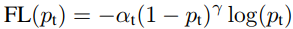






Training, inference and validation was mostly done in google colab. Training used the NVIDIA Tesla K80 GPU and inference uses the same GPU. The validation notebook uses Intersection over Union for bounding boxes in order to work out precision, recall and f1_score.
Notebooks for this are availiable below.
Training: https://colab.research.google.com/drive/1iWFUw1arJVmIhkzOXEASYZs3iBuYwPzi
Inference: https://colab.research.google.com/drive/1EropOnvawLHd8ylgAWM0gZh6LqtLUPyV
Validation (precision, recall, accuracy): https://colab.research.google.com/drive/1ZMRVnz0DmNxK4SYPG2KxKKtSxf6Yeqrx