A potential performance bug (missing optimization) #12957
Comments
|
Thank you for your report! We will investigate and come back to you |
|
The additional predicate should not improve the performance as it is an additional operation that we undertake. I would suspect some other effects to be at play here such as the second query being faster because it can use the cached results from the first run. If you still think that the 2nd query is actually faster, please provide the output of |
|
Hi, one easy way to reproduce is using the online sandbox: https://sandbox.neo4j.com/. I am using the built-in Or you can download and import the dataset from https://github.com/neo4j-graph-examples/pole. I also tested two queries with db.clearQueryCaches(). It does help but performance difference still exists(and up to 30+ times). See the snapshot below:
|

|
I ran the two queries on the crime investigation dataset and the one with the predicate seems to be a bit slower. These are the results after a bit of warming up for each one of them: When I run them on a fresh cache, they are at ~4 secs and ~2 secs respectively. |

|
Hi, I have similar results to yours but I do not think it is normal to execute queries with PROFILE... Have you tried the queries without PROFILE? See my results below, PROFILE is OK but MATCH is problematic:
Is it possible that PROFILE and MATCH could execute two different code branches? |

|
If you add the How often did you run each query? Have you tried it in Sandbox? |

|
Hi, I just rerun queries on cypher 4.4 and 4.1. The sandbox is a bit unstable so I am not sure but cypher 4.4 does not give such a performance difference. Thanks for your response. |
|
Thank you for the feedback. Let me know if this issue is of any more use for you, otherwise i will close it. |
|
Hi, please close the issue |
|
Just for your information, I notice that the call stack is different in 4.1 but as it is older version maybe no need to worry about. The profile log in version 4.1: |
|
Thank you very much for that feedback. That explains a lot: Apparently, we find a suboptimal plan in 4.1 for the query without the predicate, which is fixed in 4.4. As we do not support 4.1 any more, we will leave it at that. |
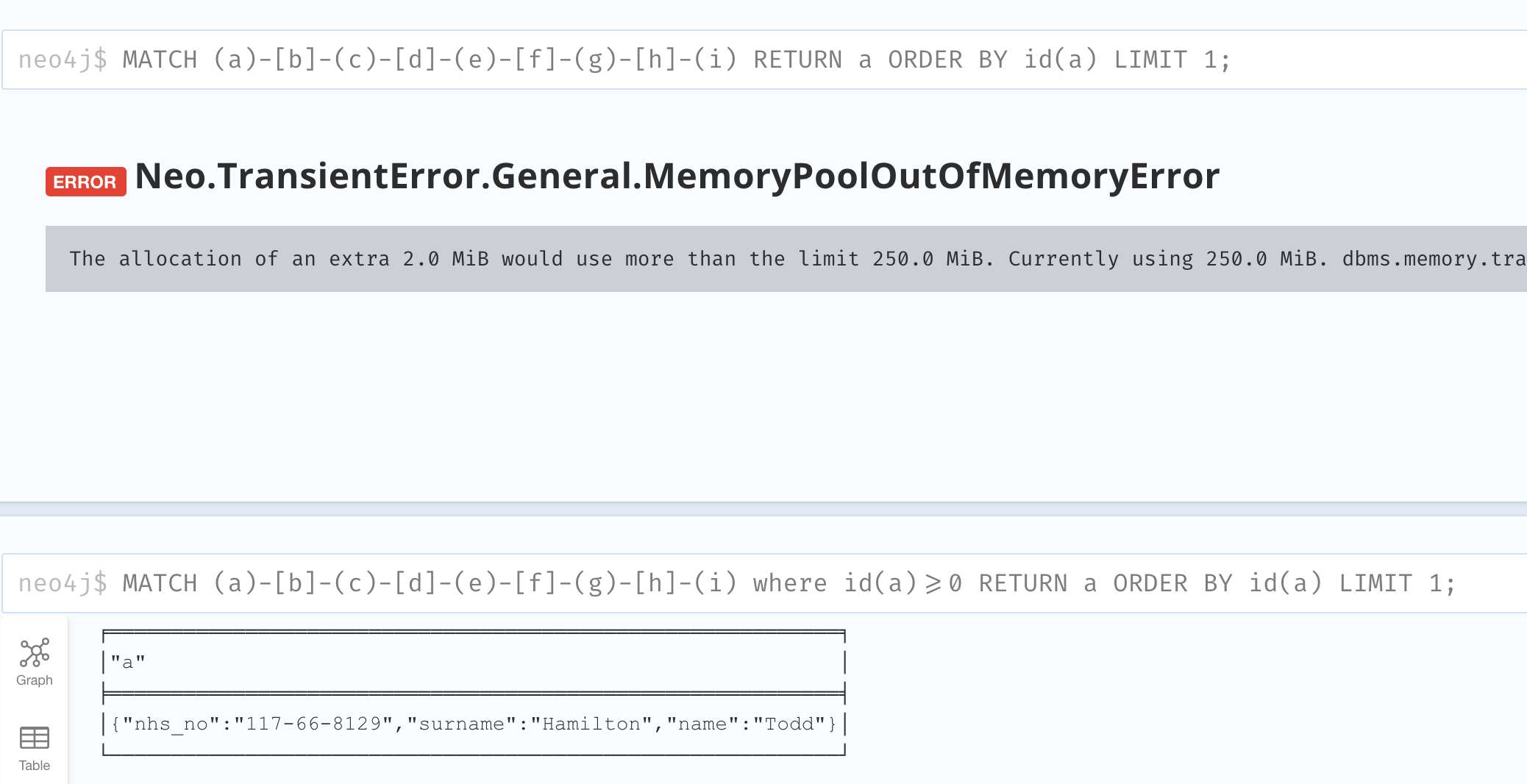
A potential performance bug found by executing equivalent queries:
Query 1:
Result 1:
Query 2:
Note that where id(a)>=0 is always True
Result 2
Not really sure why one redundant WHERE clause can boost the performance. Is it a potentially missed optimization for the first query?
Results in Sandbox:
The text was updated successfully, but these errors were encountered: