RFC: a new design for alert system #3963
Comments
|
So, somewhat ironically, I'm actually working on a notification daemon in Python that replicates a lot of the functionality from
It's not yet complete to the point of being able to post it, but I've got most of it written right now (core logic, logging, basic queue backends, and a couple of basic delivery methods, working on the configuration parsing right now, after which I should be able to start testing all of it as one unit instead of individual modules). I have no idea if this would be of direct interest for netdata, but I was planning on providing stuff with it directly so it can work with netdata as a (near) drop-in replacement for |
So essentially the one you are writing is another application which should run alongside netdata? |
|
hm... interesting ideas. Thank you for this! Another approach would be to move alarm-notify.sh inside netdata. This would give the following benefits:
There will be 2 drawbacks:
If we mix the above with the It will be a little bit complicated, because the netdata daemon is multi-host (due to streaming), so the plugin would have to add/remove hosts and alarm logs, as they are added/removed in netdata. So, this would also require a small protocol to be implemented for the bidirectional communication between netdata and the plugin. |
|
Yet another solution could be to create a daemon for managing the alarms, that one or more netdata could connect to it permanently, to push the alert log. That daemon could also have any API for the dashboards to learn the status of the alarms. |
|
Somehow I am not in favor of another daemon for this, the all-in-one solution works right now and is easy for new users. Preferably implementation following hexagonal architecture pattern would be good here and allow for quick extraction to another application if needed in the future. I was also considering moving alerting into core netdata as it seemed most optimal, but since only @ktsaou know C, this would potentially harm development time and future expansion. It seems to me that the mixed approach might be the most future-proof despite some initial problems with implementation. As for bi-directional communication protocol - gRPC? |
me neither, but it is an option, so it should be stated. Ideally, each netdata should be autonomous, but should also allow centralized notifications. Centralized notifications will allow things we can't support today, like web push notifications, mobile push notifications, will eliminate the need of having a working MTA on all servers for mail delivery, will simplify the dependencies for containers, etc. So, a simple solution could be to improve So, the netdata daemon could be enhanced with at least these:
|
|
I don't think netdata core (part written in C) package should manage alerts itself and that part should be offloaded to a plugin or external daemon. Core would just focus on emiting alerts when a condition apply and not have any logic of resending, deduplicating alerts and all that stuff. In that model there is a question if we want to resend alert to plugin/daemon every every X seconds or only on rising/falling edge (trigger based approach), but that is just an implementation detail. If we could put whole logic of managing alerts into a plugin/daemon application (points 1,2,3, and 5 from @ktsaou post), then it would be easier to maintain and possibly extend that part. Let's use experience of other monitoring projects like prometheus or influxdb, where instance emits alerts to some alert management app which in turn routes them via proper channel. The idea is to mix two worlds. Create a modular plugin which would communicate with netdata over gRPC via unix socket. This will allow to easily package and ship netdata and still maintain a possibility for a centralized alert management by switching from unix socket to TCP/IP communication. One could probably ask, why not completely offload alert management to a daemon app? And answer is simple - better user experience. This way we ship a complete package with everything in it and without a need for another program. Just consider how it simplifies netdata deployment in containerized environments. Idea schematics:
Left is a simple setup for one netdata instance. Basically one which should be enabled by default. |
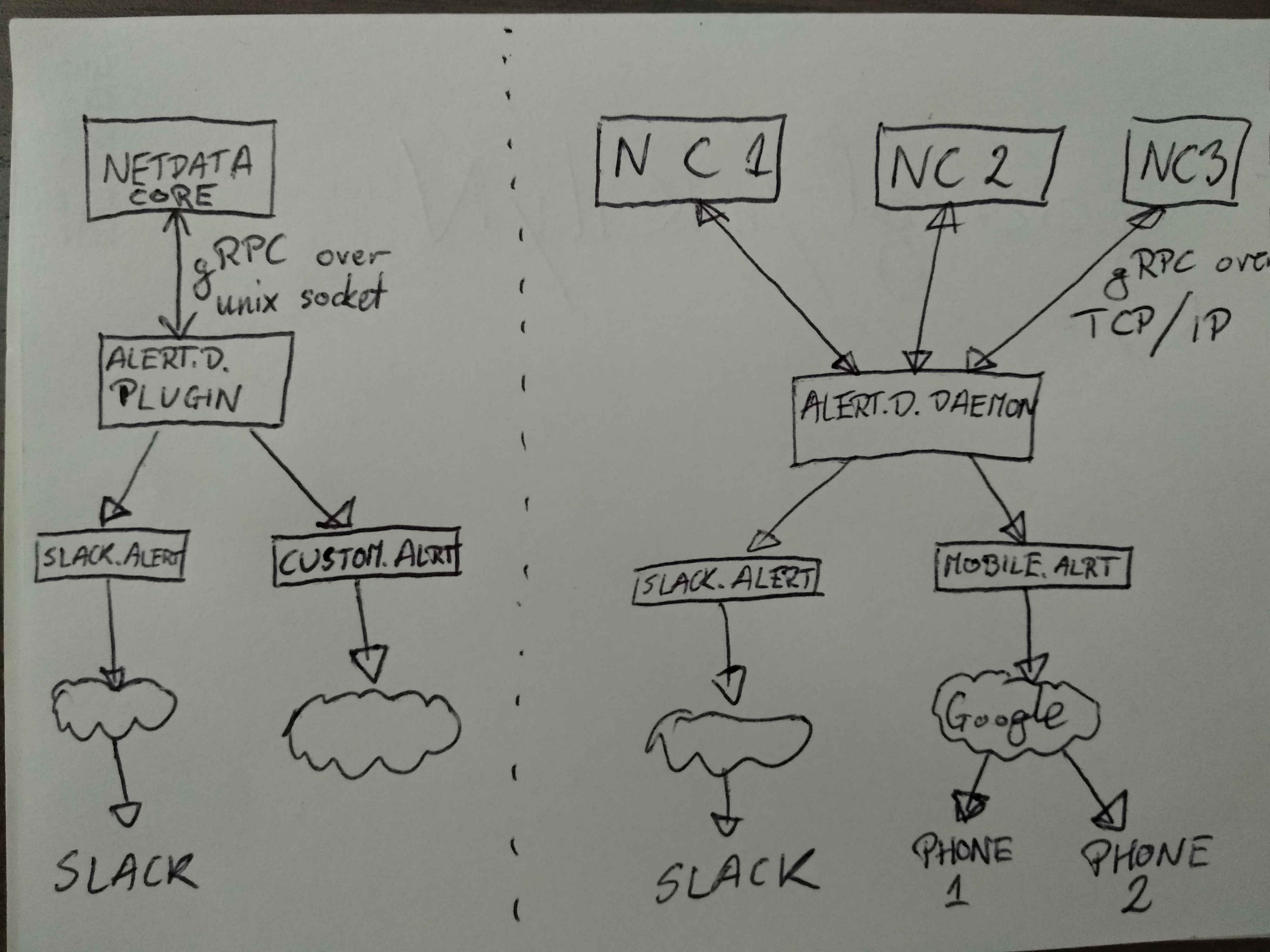
|
hm... I don't see a gRPC implementation for C. It only exists for C++. But a simple socket protocol could also do. The whole idea with the communication between netdata core and alert.d is that it has to be async. So, netdata core will send the request, receive immediately/synchronously an ACK, but the actual status of the notification will come later, once the notification has been dispatched. So, it is purely 2-way async communication. Also, in standalone mode, it could also work over pipes, to avoid having a separate daemon running. Generally the above operation would probably better implemented with a queue, so that will survive disruption. For example using http://zeromq.org/ - Check this video about zeromq, it is nice: https://www.youtube.com/watch?v=_JCBphyciAs |
|
Maybe this one https://github.com/Juniper/grpc-c ? As for pipes - I don't know if it wouldn't be better to focus on one communication system/protocol instead of creating two separate implementations. Zeromq could also work, it is used as a default communication protocol for saltstack to push configuration changes, so it is quite proven. |
|
Both gRPC and zeroMQ could be used for async communication. However tere is one advantage of gRPC over zeroMQ, it is layered over HTTP so can use existing network infrastructure. And since more people know how HTTP works, it would probably be easier for them to configure things like firewalls, encrypting data, implementing flow control, etc. However zeroMQ looks like it is a little faster protocol (for async communication it need ROUTER-DEALER connection not REQ-REP). There is quite nice comparission of both on stack overflow: https://stackoverflow.com/questions/39350681/grpc-and-zeromq-comparsion |
|
Also as for C library for gRPC, it is here: https://github.com/grpc/grpc/tree/master/src/core |
|
@paulfantom Yes, it's designed to run as a separate daemon. My primary motivation for writing it is to have only one thing on my systems actually dispatching notifications, instead of the current situation of half a dozen, and thus have all the configuration for notifications in one place. Long term, I don't think it's likely to be the best option for netdata, but I just wanted it to be out there as something that could be an alternative delivery mechanism (and I am serious about providing the required stuff with it to make it trivial to use with netdata, same goes for every other item on my systems that sends alerts). As far as long-term usage, what I see as an ideal solution would meet all these criteria:
|
|
Ad 1: That's why I wanted to have Ad 2: As for efficiency in Bash vs Python - it depends on many variables. I also don't say that
Actually that is something that should be considered. It works well when used in non-distrubuted systems. However in distributed ones, constant alarm resending is considered a feature, since it allows master to "see" if a slave is still active or if it is unavailable (disconnected from network or high system load) - it is a heartbeat signal. If there was a way of providing heartbeat feature in other, less expensive, way then trigger-based system is still ok. Ad 3: If there was an Ad 4: That's what I proposed in a chart. 😄 It should communicate with netdata with a specified protocol (I am looking if there is some open-source spec), so if anyone would like to send alert via it, just communicate by using that protocol. From what I see daemon you are writing is an extended version of prometheus/alertmanager. It is efficient (written in go-lang), easy to understand (config is a YAML file), and it is a separate application. What is different is an ability to add new delivery mechanisms on the fly. I also wanted to add, that we SHOULD NOT create new communication protocols and rely as much as possible on ones which are already established. Relevant: https://xkcd.com/927/. |
|
On the note of item 2 in particular, my point about efficiency is more about minimizing impact on the rest of the system when an alarm fires than it is about timely delivery (though timely delivery is still a plus IMO). If your delivery mechanism has to compute something before it is sending a notification, it should do so as efficiently as possible to minimize how much it slows down everything else. As far as what I'm working on, it's conceptually pretty similar to alertmanager, with the biggest differences aside from language being how routing is configured and the lack of some features that alertmanager provides that I don't care about (like clustering and silences). It doesn't really support 'on-the-fly' additions of delivery mechanisms, but I plan to have things set up to work kind of like netdata's python.d module for this (that is, you drop a file with the right API exposed in the correct directory, restart the daemon, and it just works). Also, entirely agreed that a there is no reason for a new protocol, with the specific caveat that I would like to avoid doing stupid things like using HTTP as a transport layer when it's not needed. |
In my proposal that sort of processing would be in Silencing is actually an important feature. You don't want to send alerts on 1am for systems that are not crucial, but you want to send those alerts on work hours. Using HTTP as transport layer can actually be a good idea. It is supported by every middle layer device. Everyone knows how to configure firewall to allow HTTP traffic, how to tag it, how to secure it and so on. And if you use something based on TCP (I don't even consider UDP for alerts) it isn't so simple. It could be fast, but it is a pain for end users. And what is the reason for fast but unusable system? |
In this case, yes, for my usage, I just do the silencing at the level of the sender, not the broker, so I don't need it (currently) in what I'm writing. I might add it eventually, but it's not going to be in the initial version simply because I have to draw the line somewhere for features. As far as HTTP, I'm more referring to cases like microsoft's SSDP, which is run on top of HTTP on top of UDP (so they didn't need it for framing), shouldn't be crossing firewalls (so they didn't need it for simplicity there), and really needs to be efficient (which is not helped by HTTP). |
|
I don't have much knowledge on microsoft SSDP, but from what you are saying it looks like shit. Here we might or might not end up with using HTTP for communication over unix socket on localhost. Which isn't ideal but solves some problems with scalability. |
|
Currently netdata team doesn't have enough capacity to work on this issue. We will be more than glad to accept a pull request with a solution to problem described here. This issue will be closed after another 60 days of inactivity. |
|
@Ferroin let's use this one for the new refactoring of alarm-notify.sh. Limit the scope to splitting the code to individual files that will reside in the directories for each notification method, so that alarm-notify.sh becomes smaller and cleaner. |
As of today
alart-notify.shhas 2304 lines of bash script with multiple code repetitions and extensive boilerplate. Adding new alert destination comes down to copying a bunch of code and pasting it with a minor alterations. There is an attempt to reduce this in #3960 but that does not solve fundamental problem, which is the fact that bash just simply isn't made for this.To solve that I can think of two possible solutions, which aren't exclusive with each other:
alert-notify.shto python, go-lang or other langAs for second point I was thinking of something like
python.d.pluginbut for alert system, temporarily let's call italert.d.plugin. This plugin could just send alerts to a specific alert module (likeslack.alert) and take care of things like alert deduplication, management, and routing.Example alert flow:
alert.d.pluginparses generic alert and routes it to specified module, ex.email.alertAND/ORslack.alertSince alerting should be available on every system and python isn't available everywhere, I would suggest using go-lang, but I don't have any strong opinions on choosing language.
@ktsaou @l2isbad @Ferroin
The text was updated successfully, but these errors were encountered: