이 개발브런치는 기존 프로젝트를 Java 프로젝트 구조로 재개발하기 위해 작성되었다. 기여도를 위해 개발 지사로 전환할 수 있다. 자세한 내용은 이 문제를 참조하십시오. 컨트리뷰션을 위해 개발브런치로 전환할 수 있다. 자세한 내용은 이 이슈를 참고하십시오.
이것들은 단지 시범을 위한 것이다. 표준 자바 라이브러리에는 성능상의 이유로 더 나은 것들이 구현되어있다

From Wikipedia: 버블 소트(sinking sor라고도 불리움)는 리스트를 반복적인 단계로 접근하여 정렬한다. 각각의 짝을 비교하며, 순서가 잘못된 경우 그접한 아이템들을 스왑하는 알고리즘이다. 더 이상 스왑할 것이 없을 때까지 반복하며, 반복이 끝남음 리스트가 정렬되었음을 의미한다.
속성
- 최악의 성능 O(n^2)
- 최고의 성능 O(n)
- 평균 성능 O(n^2)
View the algorithm in action

From Wikipedia: 삽입 정렬은 최종 정렬된 배열(또는 리스트)을 한번에 하나씩 구축하는 알고리즘이다. 이것은 큰 리스트에서 더 나은 알고리즘인 퀵 소트, 힙 소트, 또는 머지 소트보다 훨씬 안좋은 효율을 가진다. 그림에서 각 막대는 정렬해야 하는 배열의 요소를 나타낸다. 상단과 두 번째 상단 막대의 첫 번째 교차점에서 발생하는 것은 두 번째 요소가 첫 번째 요소보다 더 높은 우선 순위를 가지기 떄문에 막대로 표시되는 이러한 요소를 교환한 것이다. 이 방법을 반복하면 삽입 정렬이 완료된다.
속성
- 최악의 성능 O(n^2)
- 최고의 성능 O(n)
- 평균 O(n^2)
View the algorithm in action

From Wikipedia: 컴퓨터 과학에서, 합병 정렬은 효율적인, 범용적인, 비교 기반 정렬 알고리즘이다. 대부분의 구현은 안정적인 분류를 이루는데, 이것은 구현이 정렬된 출력에 동일한 요소의 입력 순서를 유지한다는 것을 의미한다. 합병 정렬은 1945년에 John von Neumann이 발명한 분할 정복 알고리즘이다.
속성
- 최악의 성능 O(n log n) (일반적)
- 최고의 성능 O(n log n)
- 평균 O(n log n)
View the algorithm in action

From Wikipedia: 퀵 정렬sometimes called partition-exchange sort)은 효율적인 정렬 알고리즘으로, 배열의 요소를 순서대로 정렬하는 체계적인 방법 역활을 한다.
속성
- 최악의 성능 O(n^2)
- 최고의 성능 O(n log n) or O(n) with three-way partition
- 평균 O(n log n)
View the algorithm in action

From Wikipedia: 알고리즘 입력 리스트를 두 부분으로 나눈다 : 첫 부분은 아이템들이 이미 왼쪽에서 오른쪽으로 정렬되었다. 그리고 남은 부분의 아이템들은 나머지 항목을 차지하는 리스트이다. 처음에는 정렬된 리스트는 공백이고 나머지가 전부이다. 오르차순(또는 내림차순) 알고리즘은 가장 작은 요소를 정렬되지 않은 리스트에서 찾고 정렬이 안된 가장 왼쪽(정렬된 리스트) 리스트와 바꾼다. 이렇게 오른쪽으로 나아간다.
속성
- 최악의 성능 O(n^2)
- 최고의 성능 O(n^2)
- 평균 O(n^2)
View the algorithm in action

From Wikipedia: 쉘 정렬은 멀리 떨어져 있는 항목의 교환을 허용하는 삽입 종류의 일반화이다. 그 아이디어는 모든 n번째 요소가 정렬된 목록을 제공한다는 것을 고려하여 어느 곳에서든지 시작하도록 요소의 목록을 배열하는 것이다. 이러한 목록은 h-sorted로 알려져 있다. 마찬가지로, 각각 개별적으로 정렬된 h 인터리브 목록으로 간주될 수 있다.
속성
- 최악의 성능 O(nlog2 2n)
- 최고의 성능 O(n log n)
- Average case performance depends on gap sequence
View the algorithm in action
정렬 알고리즘의 복잡성 비교 (버블 정렬, 삽입 정렬, 선택 정렬)
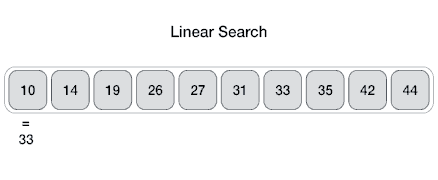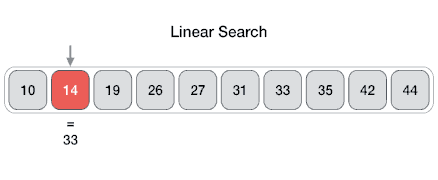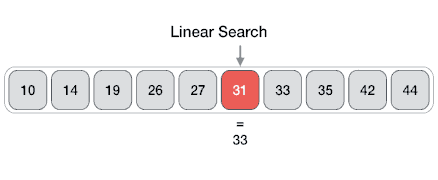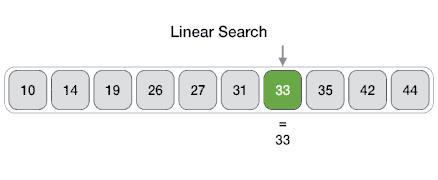
From Wikipedia: 선형 탐색 또는 순차 탐색은 목록 내에서 목표값을 찾는 방법이다. 일치 항목이 발견되거나 모든 요소가 탐색될 때까지 목록의 각 요소에 대해 목표값을 순차적으로 검사한다. 선형 검색은 최악의 선형 시간으로 실행되며 최대 n개의 비교에서 이루어진다. 여기서 n은 목록의 길이다.
속성
- 최악의 성능 O(n)
- 최고의 성능 O(1)
- 평균 O(n)
- 최악의 경우 공간 복잡성 O(1) iterative

{kind=link}
From Wikipedia: 이진 탐색, (also known as half-interval search or logarithmic search), 은 정렬된 배열 내에서 목표값의 위치를 찾는 검색 알고리즘이다. 목표값을 배열의 중간 요소와 비교한다; 만약 목표값이 동일하지 않으면, 목표물의 절반이 제거되고 검색이 성공할 때까지 나머지 절반에서 게속된다.
속성
- 최악의 성능 O(log n)
- 최고의 성능 O(1)
- 평균 O(log n)
- 최악의 경우 공간 복잡성 O(1)
| 전환 | 다이나믹프로그래밍(DP) | 암호 | 그 외 것들 |
|---|---|---|---|
| Any Base to Any Base | Coin Change | Caesar | Heap Sort |
| Any Base to Decimal | Egg Dropping | Columnar Transposition Cipher | Palindromic Prime Checker |
| Binary to Decimal | Fibonacci | RSA | More soon... |
| Binary to HexaDecimal | Kadane Algorithm | more coming soon... | |
| Binary to Octal | Knapsack | ||
| Decimal To Any Base | Longest Common Subsequence | ||
| Decimal To Binary | Longest Increasing Subsequence | ||
| Decimal To Hexadecimal | Rod Cutting | ||
| and much more... | and more... |
| 그래프 | 힙 | 리스트 | 큐 |
|---|---|---|---|
| 빈 힙 예외처리 | 원형 연결리스트 | 제너릭 어레이 리스트 큐 | |
| 힙 | 이중 연결리스트 | 큐 | |
| 그래프 | 힙 요소 | 단순 연결리스트 | |
| 크루스칼 알고리즘 | 최대힙 | ||
| 행렬 그래프 | 최소힙 | ||
| 프림 최소신장트리 |
| 스택 | 트리 |
|---|---|
| 노드 스택 | AVL 트리 |
| 연결리스트 스택 | 이진 트리 |
| 스택 | And much more... |