Losses related to credit card fraud will grow to $43 billion within five years and climb to $408.5 billion globally within the next decade, according to a recent Nilson Report — meaning that credit card fraud detection has become more important than ever. When specific cases of credit card fraud are discovered, the majority of contemporary systems use artificial intelligence (AI) and machine learning (ML) to manage data analysis, predictive modeling, decision-making, fraud alerts, and remediation action.
Given the surge in online fraud and digital crime, it is more crucial than ever for businesses to take decisive action to stop payment card fraud using cutting-edge technology and robust security measures. Therefore, this project attempts to evaluate different machine learning models to detect fraudulent credit card transactions.
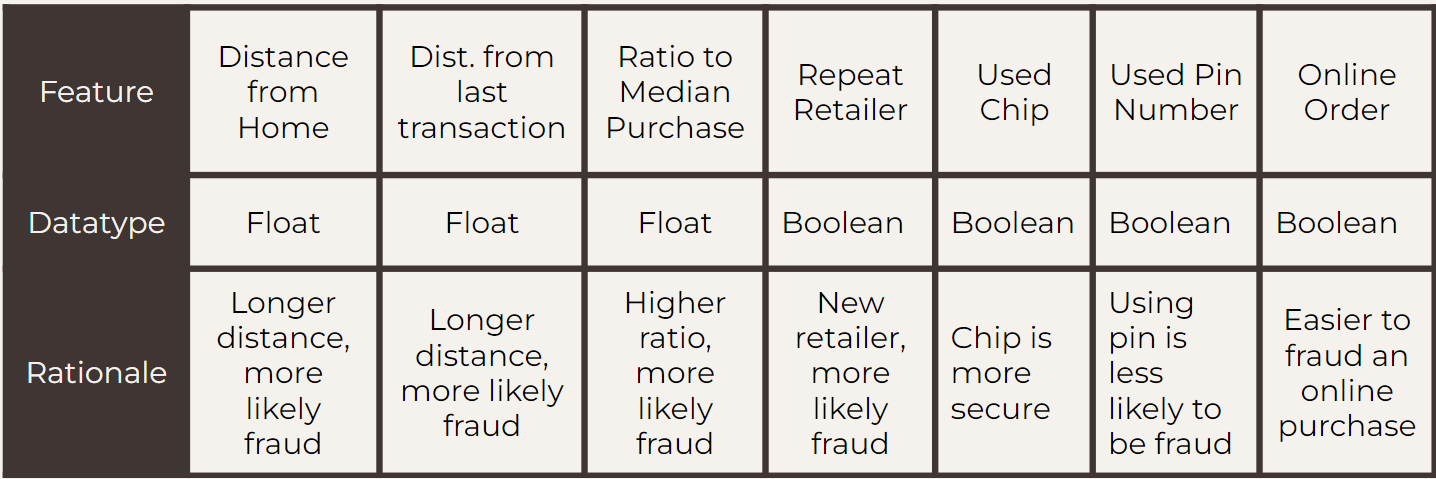
The dataset that we will be using for this particular problem can be found on Kaggle at this link. The feature explanation can be found in the image below
Firstly, we'll use 70% of our dataset for training and the remaining 30% for testing.
After exploring our dataset, we noticed that our dataset was extremely imbalanced, where non-fraudulent transactions were about 91% of the data. So, we decided to resample the data using 4 techniques
- Random Undersampling
- NearMiss Undersampling
- Random Oversampling
- SMOTE Oversampling
We also have a baseline/control trainng dataset that is left untouched (i.e., not applying any resampling methods).
For the machine learning models, we'll use Neural Networks (MLP), Random Forest, and K-Means Clustering. After training the models, we use our test data to obtain the model metrics such as accuracy score and precision/recall/f1 scores. We also visualize our results by plotting confidence score histograms and confusion matrices
We discover that Random Forest is the most effective model out of the three since all metrics are 1.00 (rounded to 2 d.p.). If we prioritize recall, the model that is trained by Random Undersampling is our best choice. However, if we want a balance between Precision and Recall (i.e., highest f1-score), the model that is trained by Random Oversampling would be more suitable.
The poorest performing model would be the one trained by NearMiss Undersampling, which results in the lowest accuracy, has a relatively lower average confidence score, and a lower recall. This can be attributed to the initial sampling, where due to algorithmic limitation, the two classes remain imbalanced.
For this dataset, Ratio to Median Purchase Price, Online Order, and Distance From Home are the 3 most influential features in determining whether a transaction is fraudulent or not. More specifically, higher purchase price (compared to median purchase), ordering online, and longer transaction distance from home, which are associated with higher positive SHAP values, increase the likelihood the transaction is fraudulent, and vice versa.