
The Telemetry Solution for the coding challenge has been implemented in Java and docker-compose, with:
- the Quarkus framework,
- and Apache Kafka as the streaming platform and data store.
-
Kafka as both the streaming platform and persistent data store (/archive):
Motivation
- Using Kafka for persistent storage may seem counter-intuitive at first. Kindly note, however, that Kafka is a
streaming platformand not a "traditional"messaging systemwhere messages are deleted from queues once they've been successfully consumed. - There are three primary differences between Kafka and traditional messaging systems:
- Kafka stores a persistent log which can be re-read and kept indefinitely.
- Kafka is built as a modern distributed system: it runs as a cluster, can expand or contract elastically, and replicates data internally for fault-tolerance and high-availability.
- Kafka is built to allow real-time stream processing, not just processing of a single message at a time. This allows working with data streams at a much higher level of abstraction.
Benefits
- Stream processing jobs perform computation(s) from a stream of data coming in via Kafka. When the
logic of the stream processing code changes, you often want to recompute the results. A very simple method to accomplish this is to reset the topic offset (either to zero or a specific starting time, etc.) so that the application can recompute the results with the new code. (I.e. The Kappa Architecture) - We can have an in-memory cache in each instance of the application that is fed by updates from Kafka. A very simple way of building this is to make the Kafka topic log compacted, and have the application simply start fresh at
offset zerowhenever it restarts to populate its cache. - Kafka is often used to capture and distribute a stream of "database" updates (this is often called Change Data Capture or CDC). Applications that consume this data in steady state only need the newest changes. New applications, however, need start with a full dump or snapshot of data. Performing a full dump of a large production database is, however, often a very delicate (performance impacts, etc.) and time consuming operation. Enabling log compaction on the topic(s) containing the stream of changes allows consumers of this data to perform simple reloads by resetting to offset to zero.
Implications
- Only the CarCoordinate MQTT source data will be published (and persisted) in the
carCoordinateKafka topic. - Stream processing outputs (i.e.
CarStatusandEventsMQTT messages) will not be stored in Kafka.- If this becomes a requirement in the future, the solution can be extended to assign session ID's and then store all of the stream processing outputs in kafka topics as well.
- This architecture enables the solution to reset the offset for the
carCoordinatetopic to zero (when required) in order to recompute the results (i.e. CarStatus and Events MQTT messages) when code/logic changes need to be implemented.
Alternatives
- InfluxDB is one of the best time series databases. The enterprise version is, however, required for features such as DB clustering; which is a critical non-functional requirement for well-architectured cloud-based solutions. As such, the FOSS version is not suitable for this solution.
- Using Kafka for persistent storage may seem counter-intuitive at first. Kindly note, however, that Kafka is a
-
Quarkus as the (Java) framework for implementing the application code:
Motivation
- Quarkus provides all of the required functionality to build the solution.
- I haven't used Quarkus before and decided that this coding challenge presents me with a good opportunity to learn a new framework.
Benefits
- Quarkus is an alternative to similar, but "older" frameworks, and provides excellent development functionalities and supports integration with cloud providers, containerisation technologies and serverless (Lambda) application architectures.
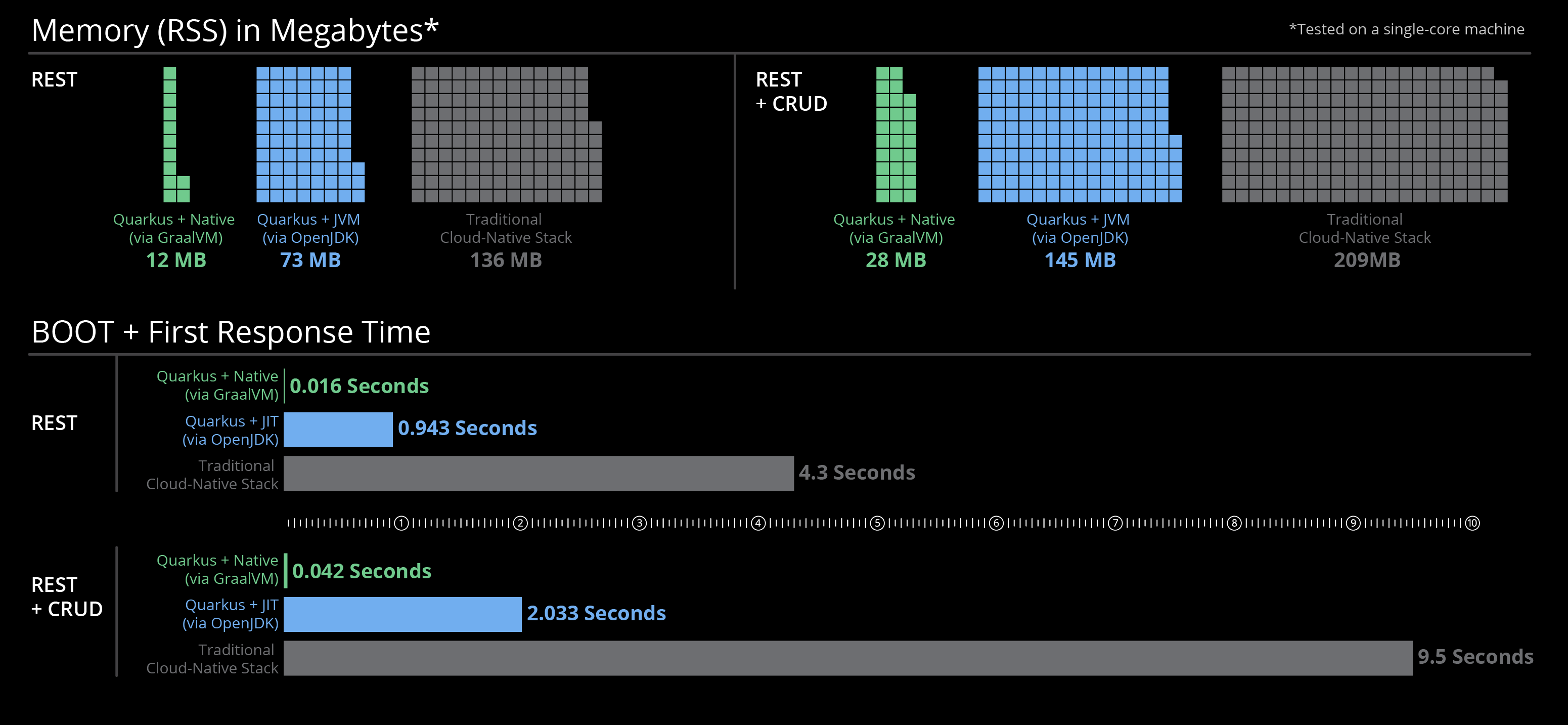
- Quarkus can compile Java bytecode to native OS binaries with extremely impressive results:
Implications
- Using Quarkus may require a relatively small invest of time to learn a new framework.
- The building of native binaries can be very slow. As such, it is recommended to build OpenJVM-based container images during development and to build native images for deployment on longer-lived environments.
Working from the architecture diagram above, the Telemetry Solution provides:
-
The CarCoordinateService that subscribes to the
carCoordinateMQTT topic (provided by thebrokerservice) and streams the consumed telemetry data to acarCoordinatetopic in thekafkaservice.- This service also subscribes to the
carCoordinatetopic (provided by thekafkaservice) and asynchronously consumes and processes thecarCoordinatestream to perform the telemetry data processing.
- This service also subscribes to the
-
The TelemetryService that processes the
carCoordinate's data stream and:- Calculates the speed and total distance that each Car has travelled using the Haversine formula.
- Maintains an ordered list of Car's (sorted by total distance travelled) and:
- Calculates and publishes MQTT CarStatus topic updates (with the CarStatusService) for both the speed and overall position of each Car.
- Detects and publishes MQTT Events topic updates (with the EventsService) for every Car that has overtaken another Car.
- Calculates and publishes MQTT Events topic updates (with the EventsService) for each Car's lap times and the overall fastest lap.
Prerequisites
- docker
- docker-compose
- OpenJDK 1.8
- Apache Maven
- A Linux-based environment (recommended)
- Or Windows 10 with WSL 1/2
A bash script has been provided to automate the code compilation, testing and execution of docker-compose:
./buildAndRun.sh
# -- OR, use the following for the native binary:
./buildAndRunNative.shOpen: http://localhost:8084
Press Control+C to stop docker-compose.
The code includes Unit Tests for the:
- Haversine formula implementation,
- Speed calculations.
- Circuit length calculation from GeoJSON coordinates.
The source code can be compiled and tested by running:
cd solution
./build.sh
# -- OR, use the following for the native binary:
./buildNative.shNote: I would normally automate the provisioning and deployment with CloudFormation, Terraform, the CLI-API, etc., but doing so (in this case) would require you to run potentially dodgy automation code and/or templates (etc.) from a third-party with privileged access to your AWS services/resources. This is obviously an extremely bad idea... so I've provided simple step-by-step instructions instead.
- Login to your AWS Console and change to the
Londonregion: https://aws.amazon.com - Click here to create a new EC2 instance
- Follow the onscreen prompts to provision a new EC2 instance with:
- Image:
Amazon Linux 2 AMI (HVM), SSD Volume Type(ami-05f37c3995fffb4fd) - Instance Type:
t2.micro - On the
Instance Detailspage, paste the following script into theUser Datatextbox underAdvanced Settings:
- Image:
#!/bin/bash
# update the system and install required packages
yum update -y
yum install -y docker git
# start docker on boot
systemctl enable docker --now
# install docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
usermod -aG docker ec2-user
# clone the solution's git repo
cd /home/ec2-user
git clone https://github.com/nicdesousa/MAT-Coding-Challenge.git
chown ec2-user:ec2-user -R /home/ec2-user/MAT-Coding-Challenge
# allocate some swap (file) memory to enable the solution to run on a t2.micro instance
# note: doing this is only suitable for a very small demo and certainly not recommended for anything else...
fallocate -l 1G /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
echo "/swapfile none swap sw 0 0" >> /etc/fstab
# run docker-compose when the instance boots
echo "runuser -l ec2-user -c 'cd /home/ec2-user/MAT-Coding-Challenge/; docker-compose up -d'" >> /etc/rc.local
chmod +x /etc/rc.d/rc.local
# "restart" to apply the instance changes
reboot- Click
Review and Launch - Click
Edit security groupsand add the following rules withAdd Rule:
| Type | Protocol | Port Range | Source | Description |
|---|---|---|---|---|
| HTTP | TCP | 80 | 0.0.0.0/0 | MAT Fan App HTTP |
| HTTPS | TCP | 443 | 0.0.0.0/0 | MAT Fan App Websocket |
Note: The solution (see docker-compose) enables using ports 80 and 443 instead of 8084 and 8080 to allow access for clients behind a restrictive (network or corporate) proxy server.
- Click
Review and Launchand thenLaunch - Click
View Instancesand wait ±5 minutes for the provisioning and deployment to complete. - Select your new EC2 instance, and copy the IP Address next to the
Description panel's->IPv4 Public IPfield. - Open a new browser tab/window, paste the copied IP Address, and press enter. (Please refresh the page until the site contents is shown.)
The Solution to the MAT Coding Challenge has now been deployed to a single EC2 Instance:

- When you're done, please remember to terminate your EC2 instance:
- Click here to view your AWS EC2 instances
- Right-click on your EC2 instance and select:
Instance State->Terminate
While it is out of scope for this challenge, the diagram below is an example of what a production solutions architecture could look like when applying the best-practices from the AWS Well-Architected Framework.
In this case, we use the existing containerised services (i.e. no code changes) and leverage ECS clusters with auto-scaling groups to provide a low-maintenance, secure, reliable, performant, and cost-effective AWS-based solution.



