A typical situation is the execution of a program (usally a computation-intensive algorithm) on a cluster of virtual machines on Cloud. In this way it is possible to take advantage of parallelization to obtain better performance.
In this scenario, the programmer would have to manually do the following operations:
- configure and launch the cluster of Virtual Machines
- upload the program to be executed on each instance of the cluster
- log in on each instance of the cluster
- run the program in parallel on each instance of the cluster
- deallocate all the resources used
It can be seen that such a procedure could be very tedious. For this reason, through the Java SDK made available by the various cloud providers, I have created this project that allows you to automatically perform all the operations described above.
- Input: A matrix A of size m x n and a vector x of length n
- Output: the product of the matrix by the vector denoted as
where c is also a vector of length n and its element at index i is defined as:
In this figure we can see a resolved example.
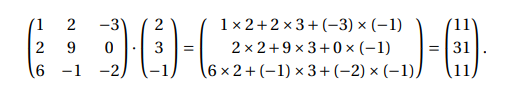
- Download the project folder
- Download and install Maven
- Import the project as Existing Maven project into Eclipse IDE or another IDE
- Run as Java application the file VMClusterExecution.java into the package vmclusterclient.
- Some parameters can also be provided: args -> [0]cloud, [1]vmTypeSize, [2]purchasingOption, [3]vmCount, [4]persistent, [5]region
- What do these parameters mean?
- cloud: is used to specify on which cloud platform the cluster of virtual machines is used.
- vmTypeSize: specifies the type of each instance of virtual machine in the cluster. Each cloud provider offers different options for VMs which mainly vary in number of vCPUs, memory, network performance etc.
- purchasingOption: specifies a characteristic of virtual machines that compose the cluster that determines how much we pay for the use. There are 2 ways to acquire virtual machines and consequently this parameter can assume the following two values:
- "on-demand": On-Demand VMs provide resizeable compute capacity with a pay-as-you-go rate namely it is paid only a fixed price just for the time of use of VM.
- "spot": Spot VMs provide access to unused compute capacity at deep discounts compared to pay-as-you-go (on-demand) rates. Spot VMs offer the same characteristics as on-demand virtual machine, but the main difference that allows this discounted price is the possible eviction: the virtual machine can be evicted, stopped and terminated at any time if the cloud provider needs capacity back.
- "spot" purchasing_option is not yet supported on Azure or not compatible with Student Subscription.
- vmCount: specifies the number of vitual machines that compose the cluster (pay attention with the number of VMs requested because some cloud providers could have some limts on this parameter).
- persistent: this parameter could be "true" or "false" and specifies if at the end of FLY execution we want to keep the VM Cluster active or we want to shut it down.
- If persistence="true" then at the end of the execution the cluster remains active and ready for the next execution. So in this scenario if for the next execution is needed a cluster with the same characteristics the existent cluster is used, avoiding all the time needed for the cluster boot. If instead it is requested a cluster with different characteristics then the existent cluster is shutted down and it is recreated a new cluster to satisfy the request.
- If persistence="false" then at the end of the execution the cluster will be shutted down.
- region: region of datacenter used by the chosen cloud provider.
- If no parameters are provided, the default ones are used (a cluster of 2 virtual machines t2.micro on-demand on AWS)
This is an example of parameters:
aws t3.micro on-demand 2 false eu-west-2
In this example the program is executed on a cluster of 2 virtual machines of type "t3.micro" on AWS in London(eu-west-2) region, on-demand and with the will to terminate all the resources used at the end od the computation.
*Remember to insert your credentials to access resources on the chosen cloud provider.
*If you want to execute a differente program change the implementation of matrix-vector multiplication with the implementation of yout program and change the method called to aggregate the partial results into the final result.
*If you want to switch Cloud provider just specify it in run parameters (the Cloud providers until now supported are AWS and Azure).
Whichever cloud provider is chosen, the sequence of operations performed when launching the execution is as follows (the refernce file is here):
-
Declaration and initialization of the matrix with random integers (lines 72 to 83)
-
Creation of queues on the chosen cloud provider: the termination queue where the termination messages will arrive, for example when the cluster instances finish their computation and the results queue where the partial results of the computations will be published.
- these queues on the cloud have their corresponding queue locally, so some threads take care of checking if there are messages arriving on the queues on the cloud, retrieve them and bring them back to the local queues. (lines 100 to 141 for AWS - lines 238 to 270 for azure)
-
the object that deals with interacting with the cloud provider services is instantiated (line 143 for AWS - line 228 for azure).
*the implementation of all methods of these objects are present in their respective packages (awsclient and azureclient)
-
Zip of the current project and upload to a storage space on the chosen cloud provider (for example an S3 bucket in the case of AWS) (line 150 for AWS - line 274 for azure)
-
Creation of the virtual machine instances that make up the cluster. (line 153 for AWS - line 276 for azure)
- in this operation there is first a check if there is a cluster of virtual machines with the desired characteristics. If there is, it is used, otherwise a cluster is created from scratch and in this case the waiting time is longer as it is necessary to wait for the execution of the initial script on all cluster instances to install the necessary software.
-
Launch of the building phase of the project by indicating as "mainClass" the name of the class that contains the function to be performed in parallel on the cluster of virtual machines (for example FunctionToExecute_aws in the case of the AWS cloud) (line 173 for AWS - line 292 for azure)
-
In the meantime that the building phase is completed, the input partitioning phase is carried out. In this case, the input matrix is partitioned as balanced as possible in such a way as to create portions of the matrix that have approximately the same size that will later be distributed to the cluster instances (line 175 for AWS - line 294 for azure)
-
When the building phase has been successfully completed on all instances of the cluster, parallel execution is launched on all machines. Each virtual machine retrieves its portion of input written on a file in JSON format, performs its computation (in this case the multiplication with the vector) and publishes its partial result on the result queue (lines 177 to 187 for AWS - lines 296 to 316 for azure)
-
When all virtual machines in the cluster have completed their computation, i.e. when all termination messages have been received, all messages from the result queue are retrieved and a function is called that aggregates all partial results into the final result (in this case the result vector) (lines 189 to 208 for AWS - lines 317 to 336 for azure)
-
Finally, the resources allocated on the Cloud are terminated if required, otherwise the resources remain ready for a possible subsequent execution (lines 211 to 222 for AWS - lines 339 to 345 for azure)