✅ setup Python environment
✅ setup Python environment
✅ entry points
- working directory:
$ cd python - python/experiments/deeprl_ddpg_continuous.py: train and eval
$ python -m experiments.deeprl_ddpg_continuous - python/experiments/deeprl_ddpg_plot.py: plot train and eval scores
$ python -m experiments.deeprl_ddpg_plot - launch tensorboard in VSCode:
$ tensorboard --logdir=./data/tf_log
✅ Result: A DDPG model was trained in one Unity-Reacher-v2 environment with 1 agent (1 robot arm) for 155 episodes, then evaluated in 3 environments (each with 1 agent) parallelly for 150 consecutive episodes and got an average score of 33.92(0.26) (0.26 is the standard deviation of scores in different envs). also the trained model is tested to control 20 agents in 4 envs parallelly and got a score of 34.24(0.10).
-
evaluation with graphics

Notes:- the 4 envs and each its own 1 (or 20) agents above were controlled by one single DDPG model at the same time.
- observation dimension
[num_envs, num_agents (per env), state_size]will be converted to[num_envs*num_agents, state_size]to pass through the neural networks. - during training, action dimension will be
[mini_batch_size (replay batch), action_size];
during evaluation, the local network will ouput actions with dimension[num_envs*num_agents, action_size], and it will be converted to[num_envs, num_agents, action_size]to step the envs.
-
train and eval scores
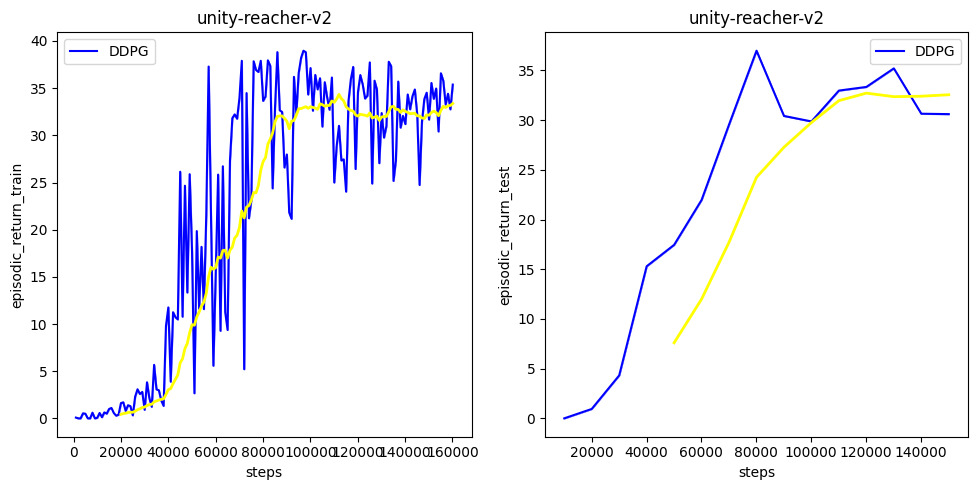
-
monitor train-eval scores with tensorboard
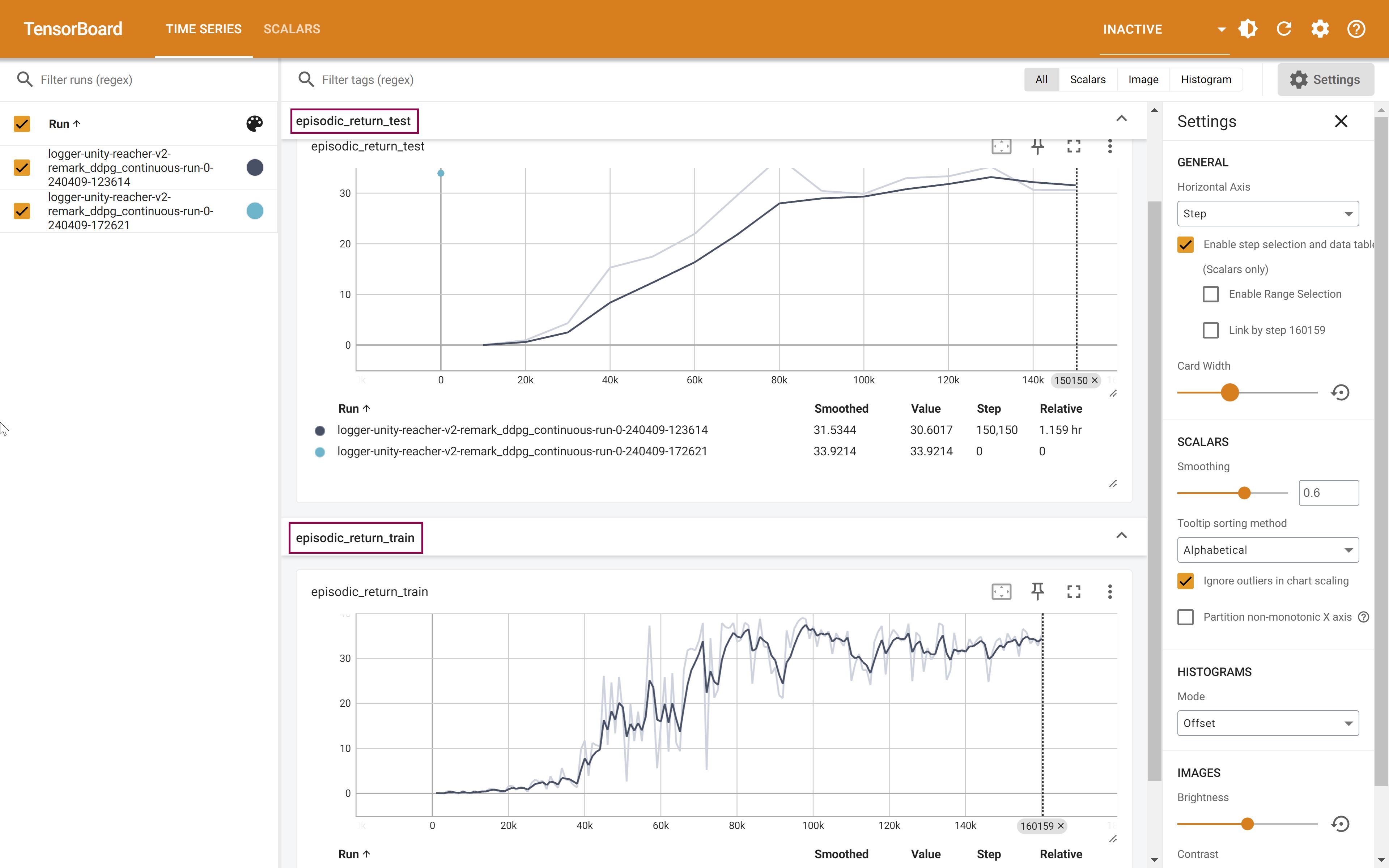
-
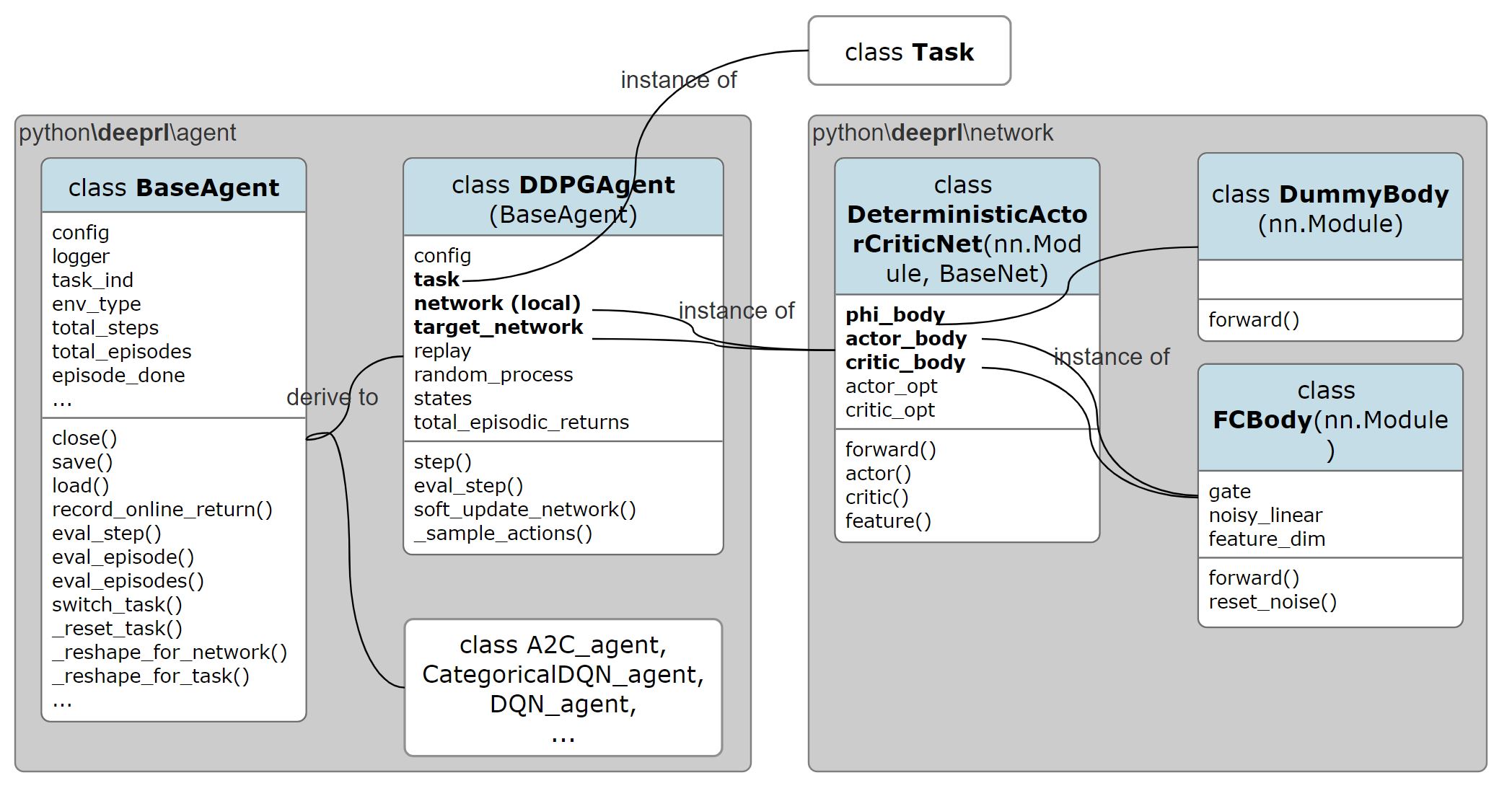
DDPG neural networks architecture
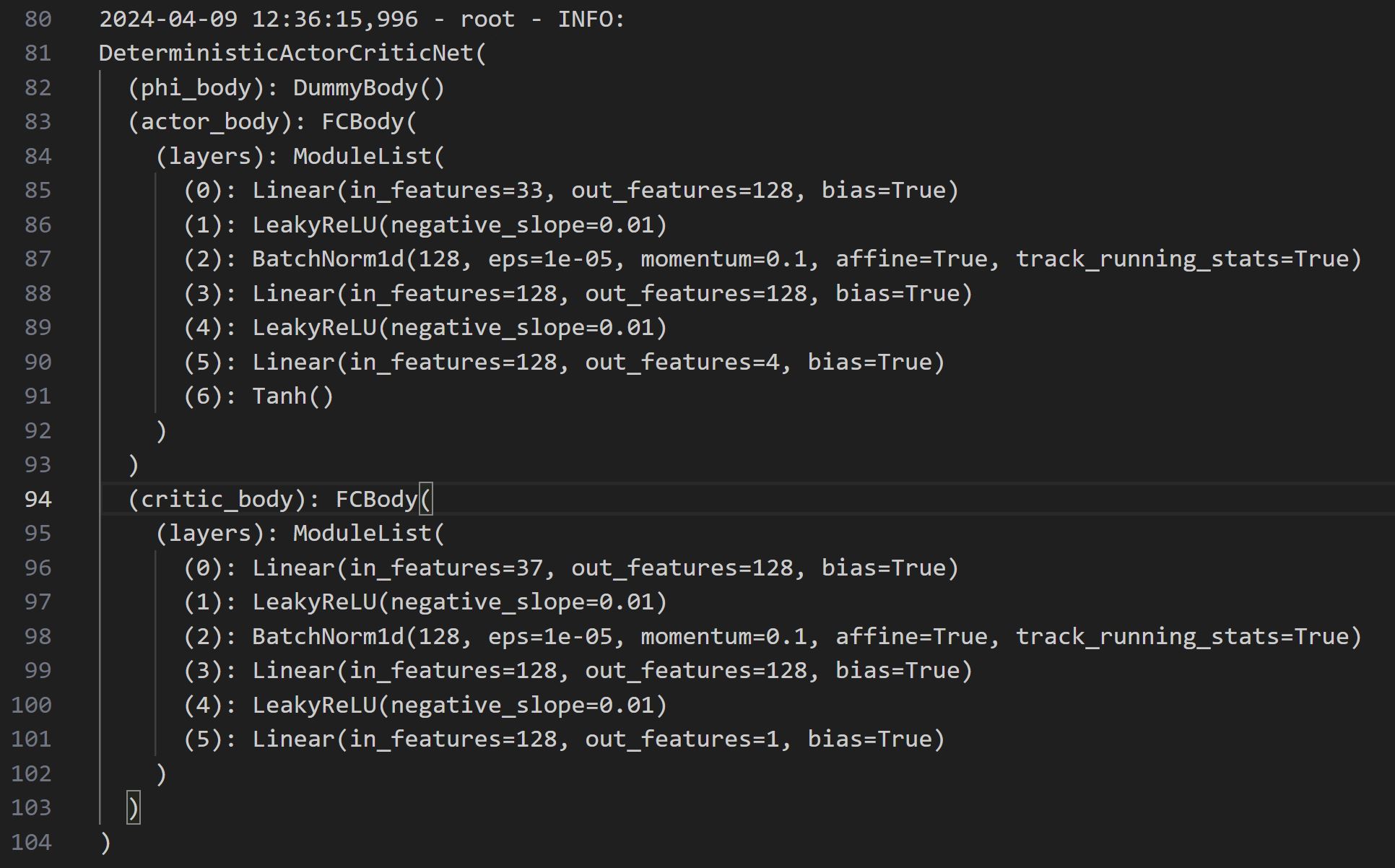
-
evaluation result (in 3 envs for 150 consecutive episodes)
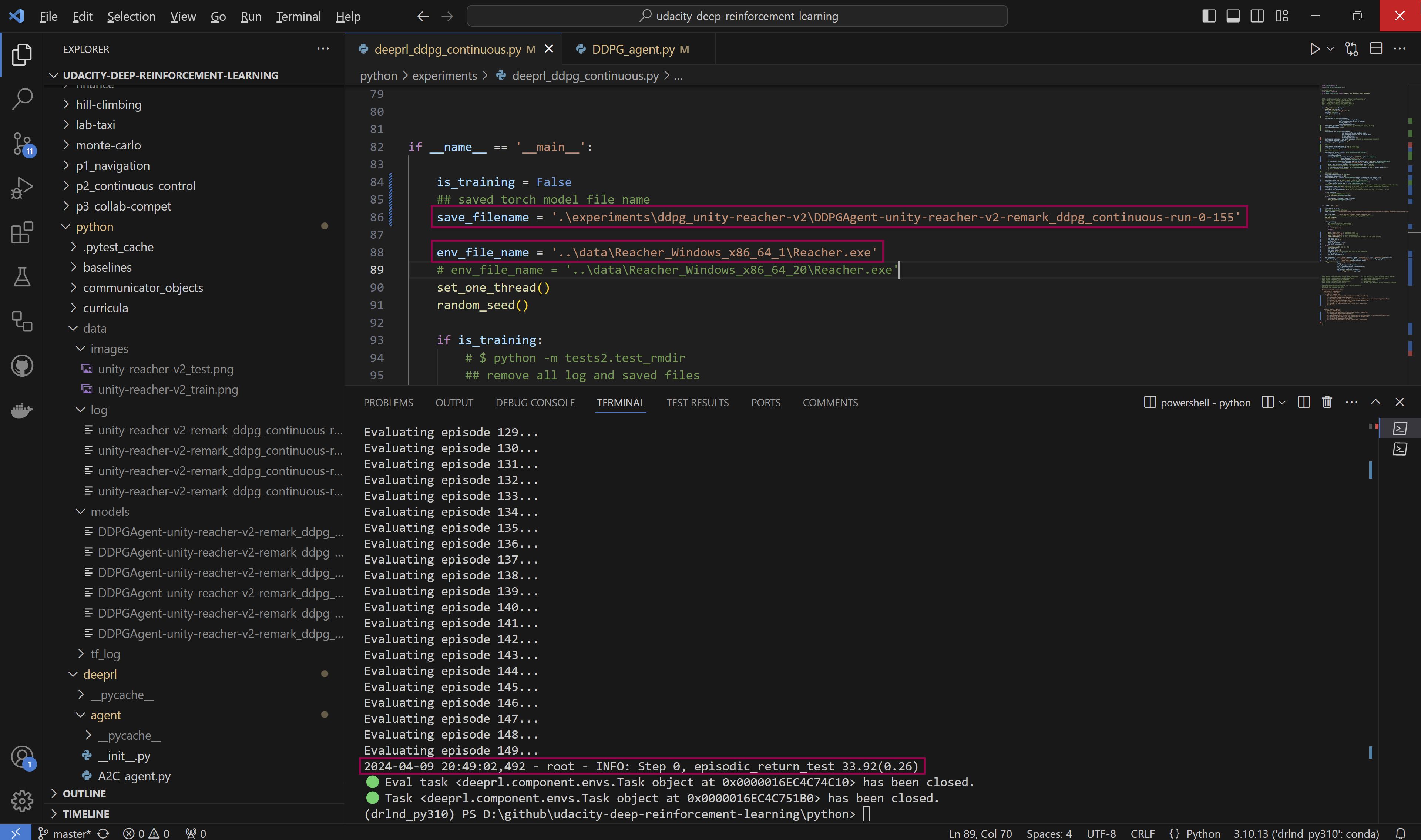
-
saved files (check the folder)
- trained model
- train log (human readable):
you can find all the configuration including training hyperparameters, network architecture, train and eval scores, here. - tf_log (tensorflow log, will be read by the plot modules)
- eval log (human readable)

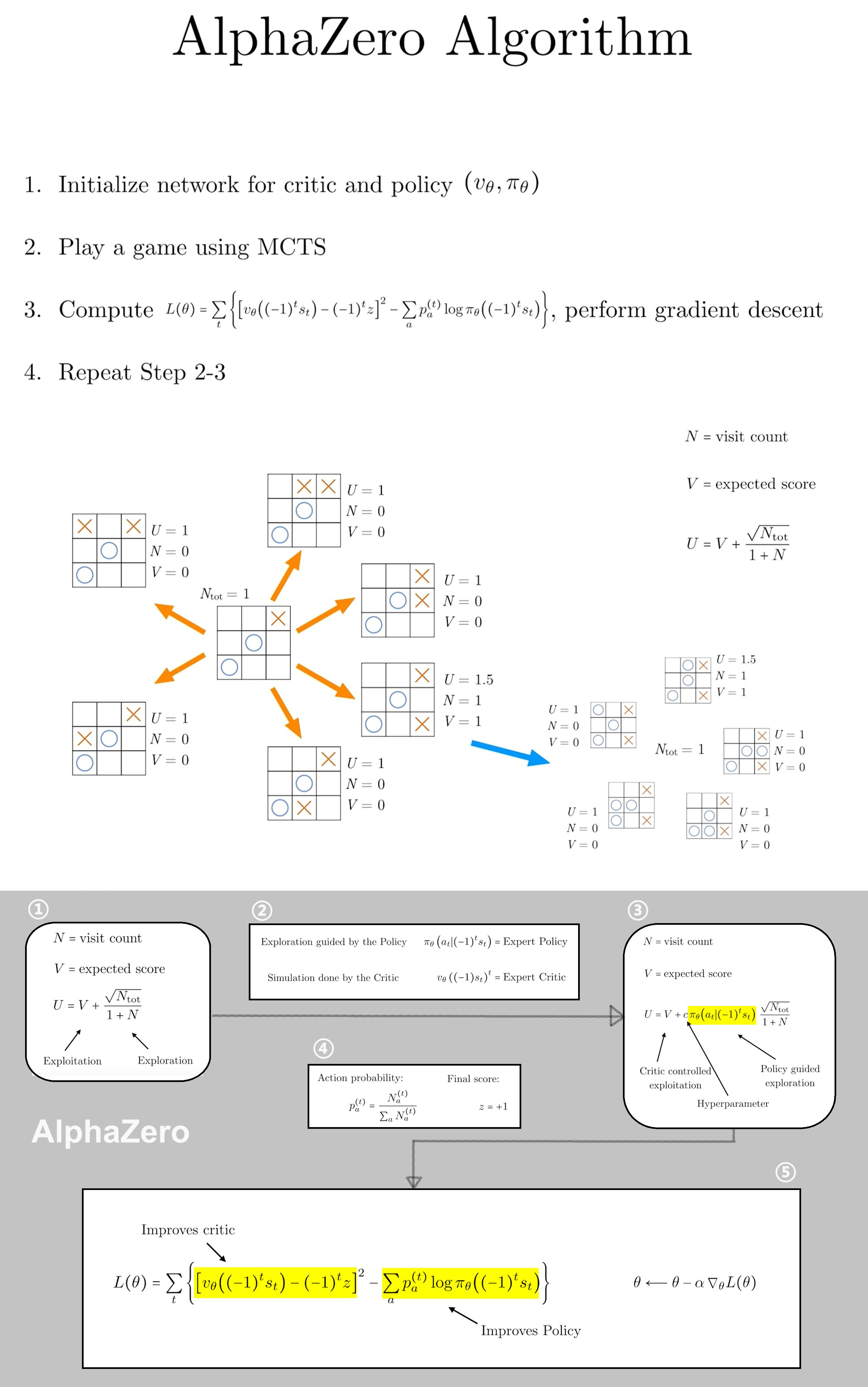
✅ major efforts in coding
-
all the code is integrated with
ShangtongZhang'sdeeprlframework which uses some OpenAIBaselinesfunctionalities. -
one task can step multiple envs, either with a single process, or with multiple processes. multiple tasks can be stepped synchronously.
-
to enable multiprocessing of Unity environments, the following code has had to be modified.
inpython/unityagents/rpc_communicator.pyclass UnityToExternalServicerImplementation(UnityToExternalServicer): # parent_conn, child_conn = Pipe() ## removed by nov05 ... class RpcCommunicator(Communicator): def initialize(self, inputs: UnityInput) -> UnityOutput: # type: ignore try: self.unity_to_external = UnityToExternalServicerImplementation() self.unity_to_external.parent_conn, self.unity_to_external.child_conn = Pipe() ## added by nov05
-
launch multiple Unity environments parallelly (not used in the project) from an executable file (using Python
SubprocessandMultiprocess, withoutMLAgents)- the major code file
python\unityagents\environment2.py - check the video of how to run the code ($
python -m tests2.test_unity_multiprocessing)

- the major code file
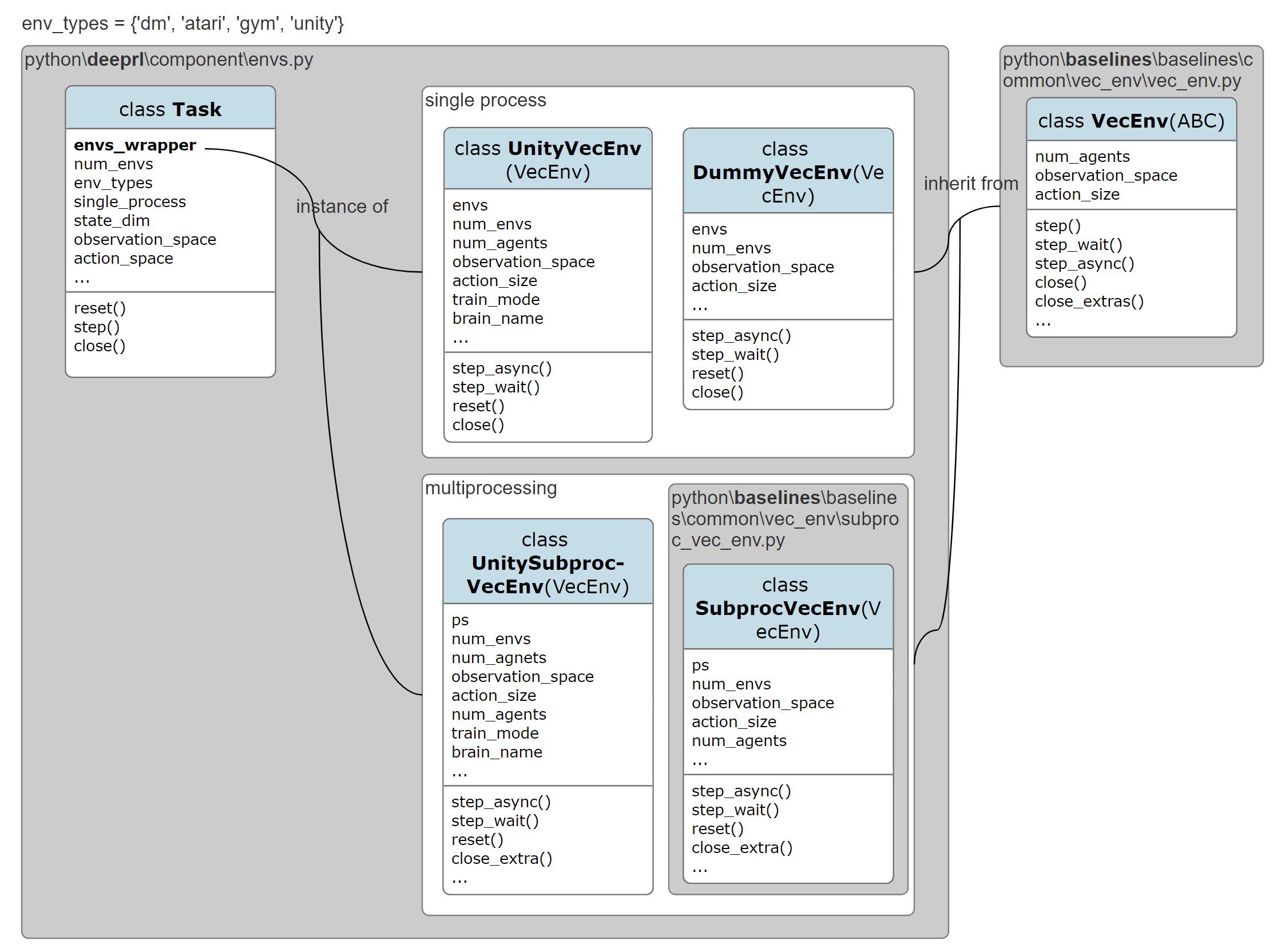
✅ reference



- For this toy game, two
Deep Q-networkmethods are tried out. Since the observations (states) are simple (not in pixels), convolutional layers are not in use. And the evaluation results confirm that linear layers are sufficient for solving the problem.- Double DQN, with 3 linear layers (hidden dims: 256*64, later tried with 64*64)
- Dueling DQN, with 2 linear layers + 2 split linear layers (hidden dims: 64*64)
▪️ The Dueling DQN architecture is displayed as below.
| Dueling Architecture | The green module |
|---|---|
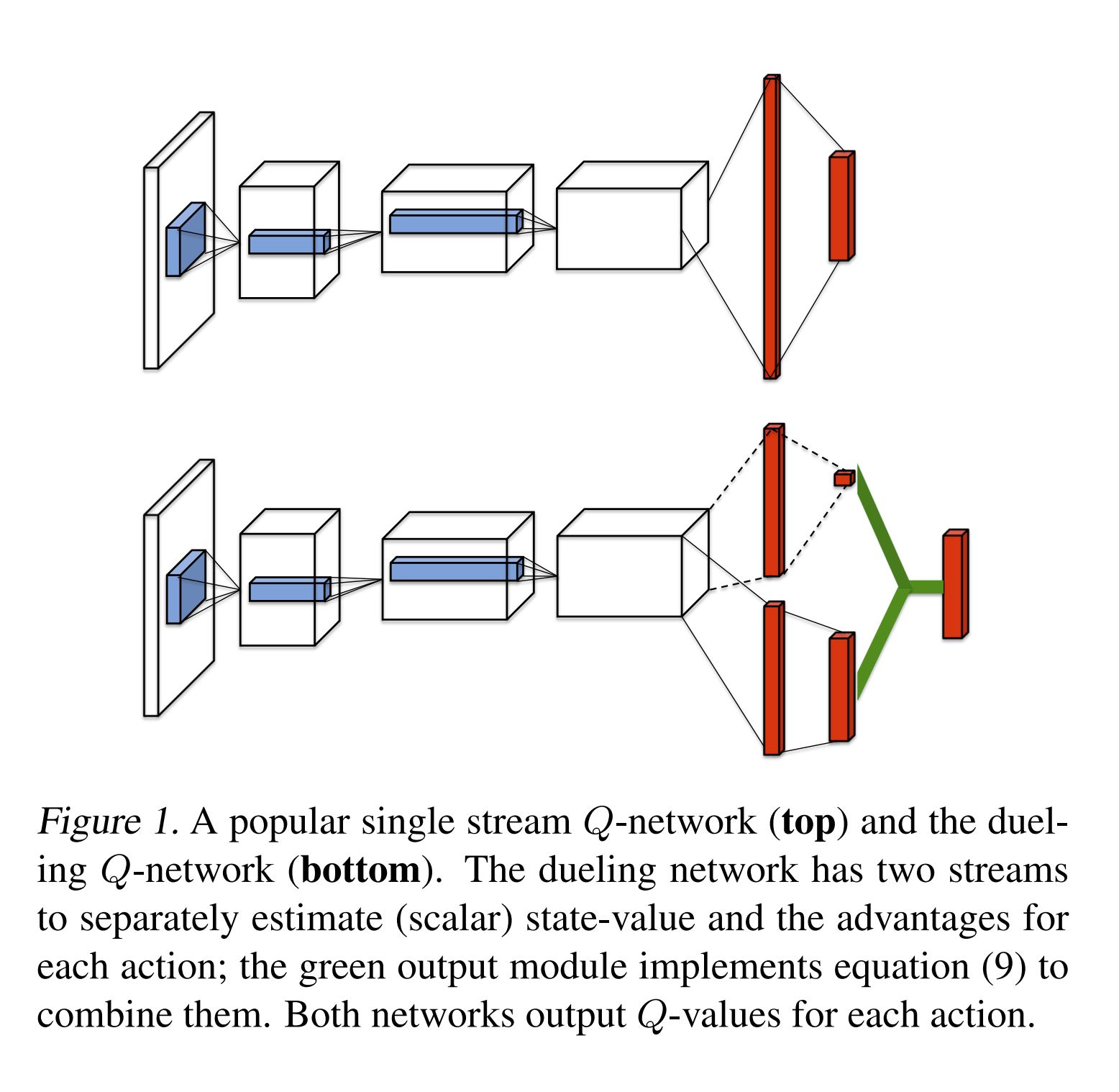
|
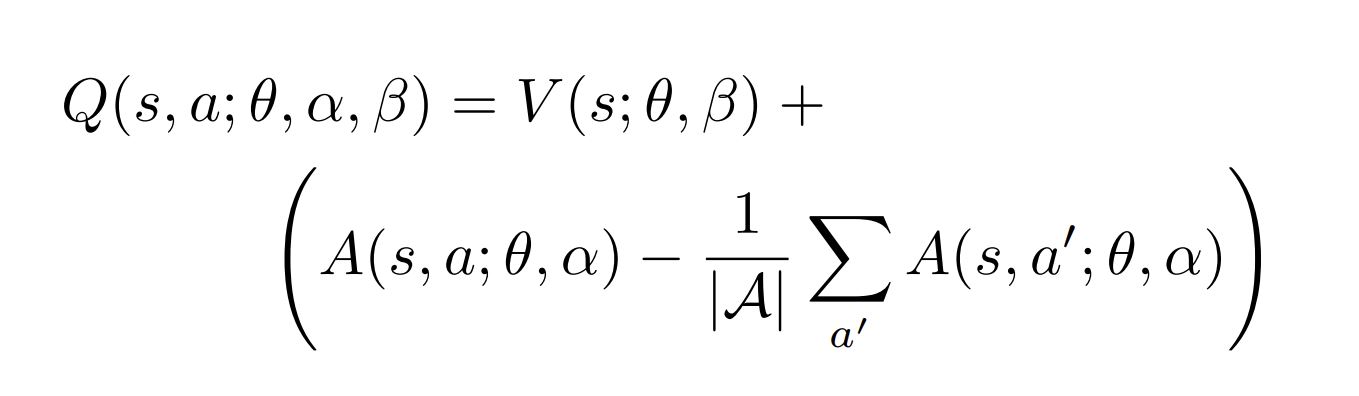
|
▪️ Since both the advantage and the value stream propagate gradients to the last convolutional layer in the backward pass, we rescale the combined gradient entering the last convolutional layer by 1/√2. This simple heuristic mildly increases stability.
self.layer1 = nn.Linear(state_size, 64)
self.layer2 = nn.Linear(64, 64)
self.layer3_adv = nn.Linear(in_features=64, out_features=action_size) ## advantage
self.layer3_val = nn.Linear(in_features=64, out_features=1) ## state value
def forward(self, state):
x = F.relu(self.layer1(state))
x = F.relu(self.layer2(x))
adv, val = self.layer3_adv(x), self.layer3_val(x)
return (val + adv - adv.mean(1).unsqueeze(1).expand(x.size(0), action_size)) / (2**0.5)▪️ In addition, we clip the gradients to have their norm less than or equal to 10. This clipping is not standard practice in deep RL, but common in recurrent network training (Bengio et al., 2013).
## clip the gradients
nn.utils.clip_grad_norm_(self.qnetwork_local.parameters(), 10.)
nn.utils.clip_grad_norm_(self.qnetwork_target.parameters(), 10.) - The following picture shows the train and eval scores (rewards) for both architectures. Since it is a toy project, trained models are not formally evaluated. We can roughly see that Dueling DQN slightly performs better with an average score of 17 vs. Double DQN 13 in 10 episodes.

- Project artifacts:
- All the notebooks (trained in Google Colab, evaluated on local machine)
- The project folder
p1_navigation(which contains checkpointsdqn_checkpoint_2000.pthanddueling_dqn_checkpoint_2000.pth) - Video recording (which demonstrates how trained models are run on the local machine)
- Project submission repo
2024-04-10 p2 Unity Reacher v2 submission
2024-03-07 Python code to launch multiple Unity environments parallelly from an executable file
...
2024-02-14 Banana game project submission
2024-02-11 Unity MLAgent Banana env set up
2024-02-10 repo cloned

This repository contains material related to Udacity's Deep Reinforcement Learning Nanodegree program.
The tutorials lead you through implementing various algorithms in reinforcement learning. All of the code is in PyTorch (v0.4) and Python 3.
- Dynamic Programming: Implement Dynamic Programming algorithms such as Policy Evaluation, Policy Improvement, Policy Iteration, and Value Iteration.
- Monte Carlo: Implement Monte Carlo methods for prediction and control.
- Temporal-Difference: Implement Temporal-Difference methods such as Sarsa, Q-Learning, and Expected Sarsa.
- Discretization: Learn how to discretize continuous state spaces, and solve the Mountain Car environment.
- Tile Coding: Implement a method for discretizing continuous state spaces that enables better generalization.
- Deep Q-Network: Explore how to use a Deep Q-Network (DQN) to navigate a space vehicle without crashing.
- Robotics: Use a C++ API to train reinforcement learning agents from virtual robotic simulation in 3D. (External link)
- Hill Climbing: Use hill climbing with adaptive noise scaling to balance a pole on a moving cart.
- Cross-Entropy Method: Use the cross-entropy method to train a car to navigate a steep hill.
- REINFORCE: Learn how to use Monte Carlo Policy Gradients to solve a classic control task.
- Proximal Policy Optimization: Explore how to use Proximal Policy Optimization (PPO) to solve a classic reinforcement learning task. (Coming soon!)
- Deep Deterministic Policy Gradients: Explore how to use Deep Deterministic Policy Gradients (DDPG) with OpenAI Gym environments.
- Pendulum: Use OpenAI Gym's Pendulum environment.
- BipedalWalker: Use OpenAI Gym's BipedalWalker environment.
- Finance: Train an agent to discover optimal trading strategies.
The labs and projects can be found below. All of the projects use rich simulation environments from Unity ML-Agents. In the Deep Reinforcement Learning Nanodegree program, you will receive a review of your project. These reviews are meant to give you personalized feedback and to tell you what can be improved in your code.
- The Taxi Problem: In this lab, you will train a taxi to pick up and drop off passengers.
- Navigation: In the first project, you will train an agent to collect yellow bananas while avoiding blue bananas.
- Continuous Control: In the second project, you will train an robotic arm to reach target locations.
- Collaboration and Competition: In the third project, you will train a pair of agents to play tennis!
- Cheatsheet: You are encouraged to use this PDF file to guide your study of reinforcement learning.
Acrobot-v1with Tile Coding and Q-LearningCartpole-v0with Hill Climbing | solved in 13 episodesCartpole-v0with REINFORCE | solved in 691 episodesMountainCarContinuous-v0with Cross-Entropy Method | solved in 47 iterationsMountainCar-v0with Uniform-Grid Discretization and Q-Learning | solved in <50000 episodesPendulum-v0with Deep Deterministic Policy Gradients (DDPG)
BipedalWalker-v2with Deep Deterministic Policy Gradients (DDPG)CarRacing-v0with Deep Q-Networks (DQN) | Coming soon!LunarLander-v2with Deep Q-Networks (DQN) | solved in 1504 episodes
FrozenLake-v0with Dynamic ProgrammingBlackjack-v0with Monte Carlo MethodsCliffWalking-v0with Temporal-Difference Methods
To set up your python environment to run the code in this repository, follow the instructions below.
-
Create (and activate) a new environment with Python 3.6.
- Linux or Mac:
conda create --name drlnd python=3.6 source activate drlnd- Windows:
conda create --name drlnd python=3.6 activate drlnd
-
If running in Windows, ensure you have the "Build Tools for Visual Studio 2019" installed from this site. This article may also be very helpful. This was confirmed to work in Windows 10 Home.
-
Follow the instructions in this repository to perform a minimal install of OpenAI gym.
-
Clone the repository (if you haven't already!), and navigate to the
python/folder. Then, install several dependencies.git clone https://github.com/udacity/deep-reinforcement-learning.git cd deep-reinforcement-learning/python pip install .
-
Create an IPython kernel for the
drlndenvironment.python -m ipykernel install --user --name drlnd --display-name "drlnd" -
Before running code in a notebook, change the kernel to match the
drlndenvironment by using the drop-downKernelmenu.

Come learn with us in the Deep Reinforcement Learning Nanodegree program at Udacity!
