when inference, how to set sigma value? #39
Comments
|
I don't think this line is caused by sigma values. When squeezing data, I think it breaks the continuity of audio in time domain. Thus you will find such lines in frequency domain. For example, when using |
|
Please try sigma = 1 or train more iteration. It helped me. |
|
just, train more steps may make this noise disappear 150k sigma=0.6 208k sigma=0.6 |
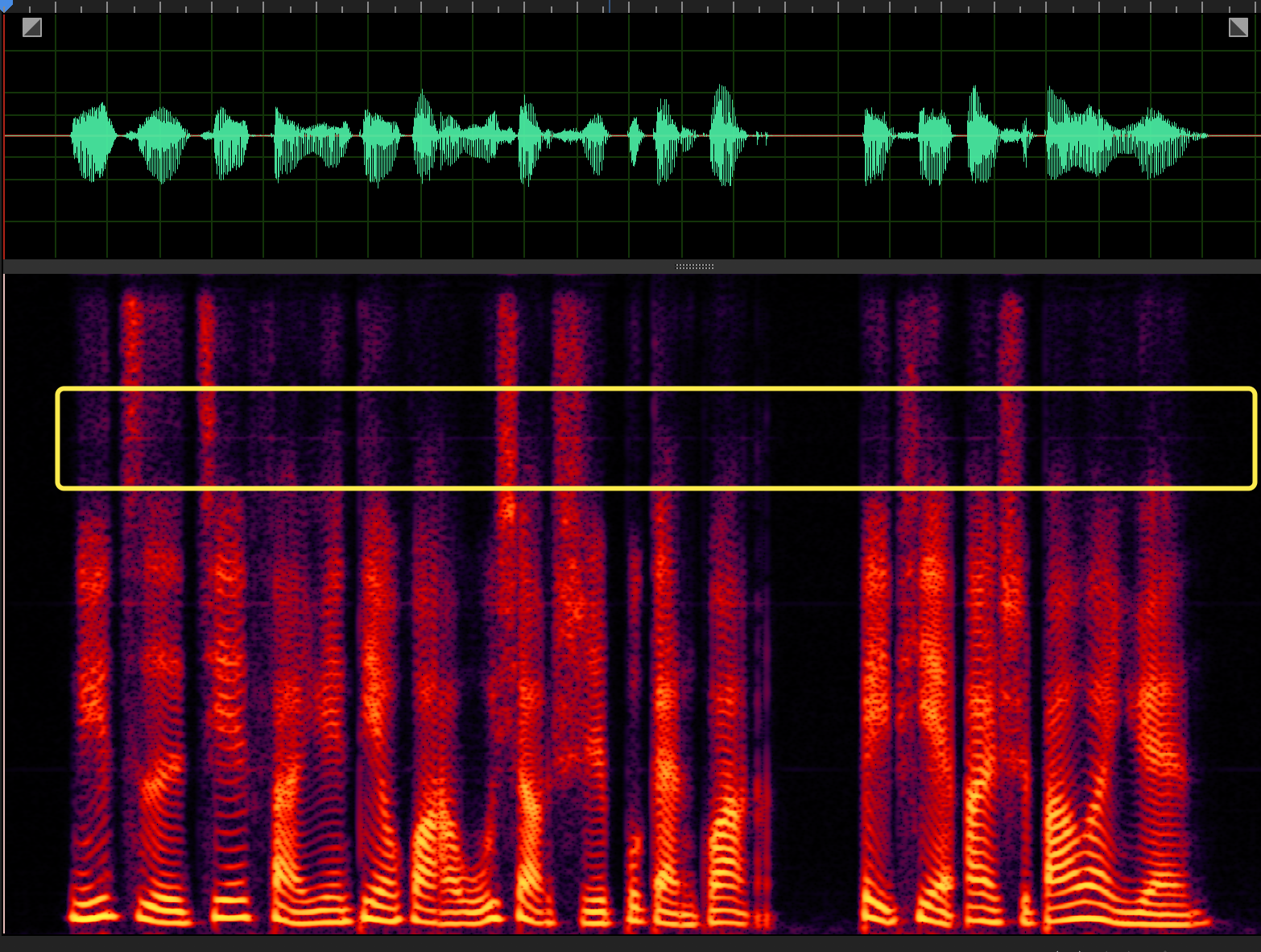
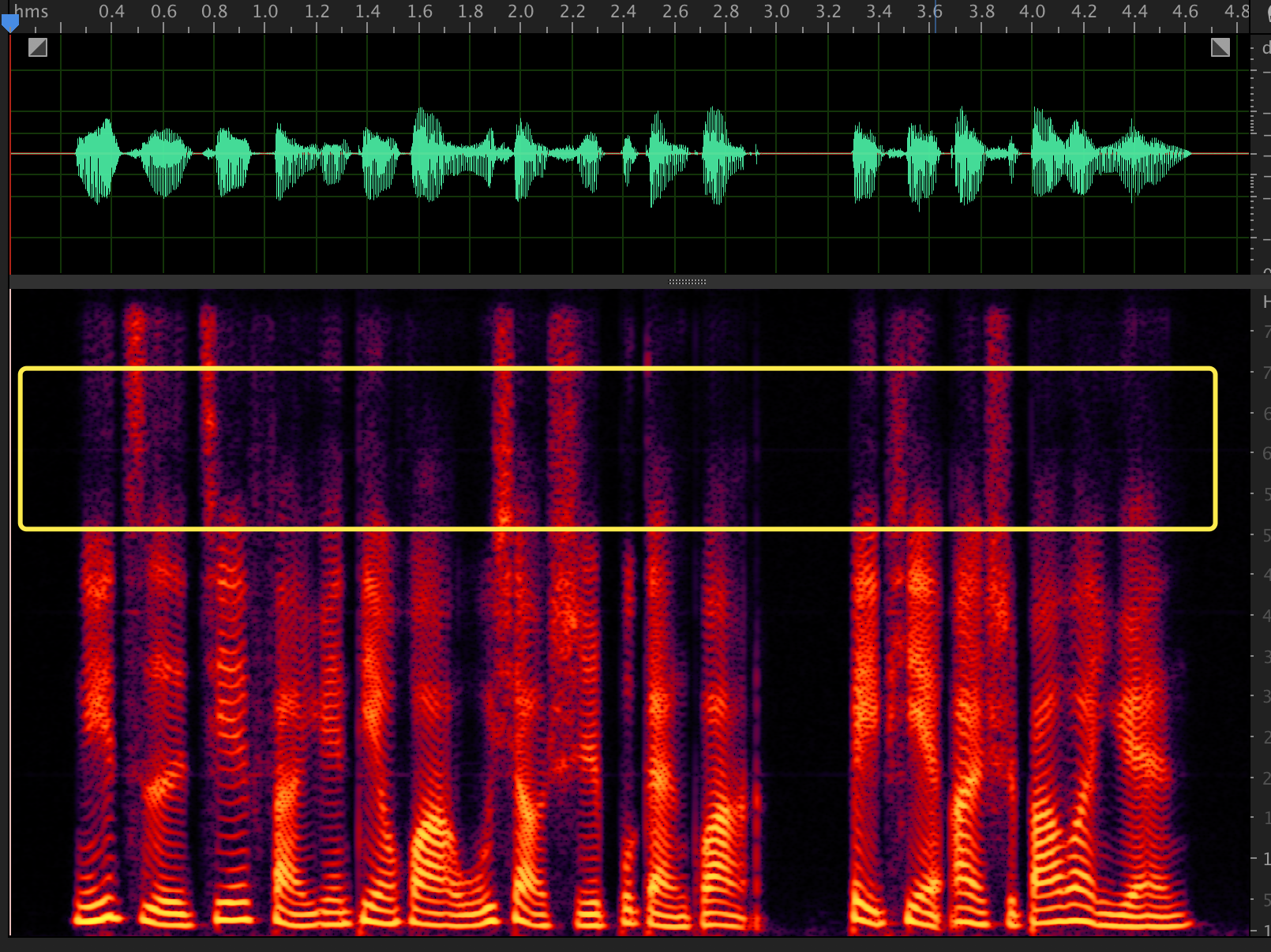
|
@syang1993 can your share your config json? |
|
@azraelkuan can you share your config json? your sigma=0.6 is during training? |
|
@hdmjdp keep the same with this repo except the wavenet filters, i change it to 128 for big batch size |
|
@hdmjdp You can just use the default config. @azraelkuan The lines also esixts in your 208K sample (2k ,4k, 6k). |
|
@syang1993 @azraelkuan } |
|
@hdmjdp Hi, I tried the default config before with batch_size=4, it works well. So I think you don't need to change the config settings. For noise line, you can try to set |
|
@syang1993 thanks for replying. My dataset is 24k, and titanv can not use batchsize=4 when seqlen=18000. What is your gpu type? |
|
@syang1993 @azraelkuan Another question. Do you try train using fp16? |
|
@syang1993 hello! your generated sample is very good and it's a 16khz audio. in your config mel_fmax=8000? and i'm confused why not use the default mel_fmax = sample_rate/2(ljspeech ,22050). and is it important? |
|
@syang1993 Hi, I want to ask something unrelated with waveglow, but also about the noise line. |
|
@hcwu1993 I used |
|
@zhangyizhong17 How do you sample in parallel wavenet? I tried parallel-wavenet with same database like waveglow, but I didn't find the noise line in the generated samples. I attached a sample from parallel-wavenet using predicted mels. So I don't think the noise line is caused by data itself. |
|
@zhangyizhong17 can you provide a link to the parallel wavenet implementation that was used to generate the sample you shared? |
|
@syang1993 what do you use repo of parallel wavenet? |
|
@hdmjdp you mean the repo I used to train parallel wavenet or the mel-prediction method? |
|
@syang1993 sorry I couldn't find my sample any more. it was 2-3 month ago. my folder is like a mess. |
|
@rafaelvalle |
|
@zhangyizhong17 Yes, the sample I attached used MoL. |
|
@syang1993 Yes. |
|
Closing due to inactivity. |
when sigma=0.6

you can see in the high frenquency, has a line noise. how to remove it?
The text was updated successfully, but these errors were encountered: