Implement quality treatment for asynchronous actions in multicore (3/3?) #11307
Conversation
62a6a97
to
d549824
Compare
| ret; \ | ||
| 1: \ | ||
| movq $-1, Caml_state(young_limit); \ | ||
| ret |
There was a problem hiding this comment.
For a start, adding this to the .S is only one way of implementing it. I looked around for other ways and it seemed the simplest to me, but maybe you know better ways. Notice that we only need it at the end of non-noalloc C calls, so for easier portability it might cheap enough to call caml_update_young_limit_after_c_call instead (if there is a good place to insert such a call).
There was a problem hiding this comment.
I cannot think of a nicer way at the moment, it seems reasonable to me
There was a problem hiding this comment.
- What happens if you don't update the young limit here? Will the signal be delayed arbitrarily or forgotten? Is it a matter of timely handling of the pending action or is it a matter of correctness?
- Needs to be implemented for the newer backends. RISC-V, s390x, WIP (Power) @xavierleroy.
There was a problem hiding this comment.
I still need to understand what this code is trying to do. Explain me like I'm 6.
There was a problem hiding this comment.
@xavierleroy An explanation of the new action_pending mechanism is given at signals.c#R281-R305. The explanation is intended to be more complete and self-contained than the text it replaces, thanks to this approach being simpler. Let me know if this text is helpful; if unclear I can try to clarify it, and if still unclear I have a metaphor for 6-year olds (involving a postman and a flag on the mailbox) that I can write down when time allows.
There was a problem hiding this comment.
This, and also the delaying that would happen for sure would be detrimental for memprof callbacks which should run as soon as possible.
There was a problem hiding this comment.
@xavierleroy are you satisfied with the responses in this thread?
There was a problem hiding this comment.
I would have loved to read the story with the postman and the mailbox :-) But, yes, the comments in the code clearly describe the design and the implementation. Thanks!
The only question that popped in my mind (but I think I have an answer) is this: when we're about to return from caml_c_call and notice that action_pending is set, why don't we jump directly to C code that can handle the pending action, instead of setting young_limit and relying on the next poll point in the OCaml code to notice and handle the pending action?
One possible answer is that the frame descriptor that ocamlopt attached to the C call site is not quite right for this purpose: the return value of the C call would have to be kept alive specially, and the backtrace may be wrong if the delayed async action raises an exception.
Another answer is that it would need more code in the runtime/*.S files, something we should avoid for our sanity.
So, I have no further questions on this PR, just one pedantic assembly code remark that can be ignored (next comment).
There was a problem hiding this comment.
This amounts to adding a polling location when returning from C code. If that's what we want, we can do it, but there is always a danger for code that is careful to control polling locations (especially in a place where that is likely to return a resource). For instance this would break the resource-safety property of Mutex.protect https://github.com/ocaml/ocaml/blob/trunk/stdlib/mutex.ml#L27 as it stands, and it would be more work to restore this property.
There was a problem hiding this comment.
Thanks for the response. The assembly code remark has been fixed in 53dedf1. I shall merge this PR.
|
Hey! |
|
Yes, it is ready for review. I consider it in polished state after several rounds of self-review. I have not followed the 5.0 alpha business but given the fixes it brings (and the fact that it is a pre-requisite for #11272), it is intended for 5.0. |
|
Concerning the alpha business, all fixes are still in scope for 5.0 during the alpha and beta release phase. Please don't hesitate to ping me on PRs that should be integrated in 5.0 once reviewed. |
|
Indeed, those kind of known possible C runtime API changes are one of the reason we have this 0th alpha release with less stability guarantees than an ordinary alpha. |
|
@sadiqj @gasche @kayceesrk This fixes bugs for 5.0 and it is a pre-requisite for #11272. Is anyone planning to have a look? |
Not this week as I am busy with other things. |
d549824
to
1f248ab
Compare
|
Regarding review: |
|
Very sorry about this. I was not aware of this effect of force pushes. Are they not accessible from the old branch d549824 ? |
|
I think it had to do with how the Github UI records comments when you do a review commit by commit, force-push probably messed with this, I know now not to trust this too much. :-) |
There was a problem hiding this comment.
Thank you for your PR!
I had a go at reviewing this PR, and left a few questions and nitpicks.
I am not quite familiar with the newer advances in the design of signals handling in the runtime, another look (by someone with more recent knowledge :-)) will be required.
The approach does make sense to me, I think it does as advertised and has the nice property of eradicating masking in both domain and systhread bootup.
I will need to re-read a few sections, I have more questions coming for caml_interrupt_all_for_signal, but I need to document myself a bit more first.
| ret; \ | ||
| 1: \ | ||
| movq $-1, Caml_state(young_limit); \ | ||
| ret |
There was a problem hiding this comment.
I cannot think of a nicer way at the moment, it seems reasonable to me
| ret; \ | ||
| 1: \ | ||
| movq $-1, Caml_state(young_limit); \ | ||
| ret |
There was a problem hiding this comment.
Double ret should maybe be avoided here.
There was a problem hiding this comment.
I think this is the best implementation: forward jumps are predicted not-taken in the absence of branch predictor history, so it is guaranteed that it costs (almost) zero in the fast path. This is the code generated by gcc (or clang, I don't remember; I used godbolt) after I using the appropriate __builtin_expect. (I will add comments to this effect to facilitate the implementation in future targets.)
|
Is there anything blocking this delicate bugfix PR for 5.0? |
|
@gasche Can you please put a 5.0 milestone on this or something? |
|
I could only have a very quick look, but your "optimal" strategy is already making me nervous performance-wise. Remember that 99% of OCaml programs do not handle signals. I don't want to penalize them to avoid corner cases in the remaining 1%. We've already paid enough with the polling points. |
|
I'll look into having benchmarks for this PR. The reasoning performance-wise is that the additional check involves a correctly-predicted branch, which can be free, and a load from a cache line that is already accessed in the same code. In addition the check is not needed (and not implemented) after "noalloc" C calls. (This does not affect this PR, but I do not think that the "1%" figure is a good estimation to have in mind regarding asynchronous callbacks: 1) we have already seen that interrupts are fairly commonly used in some application domains dear to OCaml, and 2) if we keep pathological corner-cases then users of memprof and finalizers are also affected even when those callbacks do not raise.) |
4612352
to
61cda27
Compare
|
(Temporarily reverting fd3db5e for benchmarking purposes.) |
|
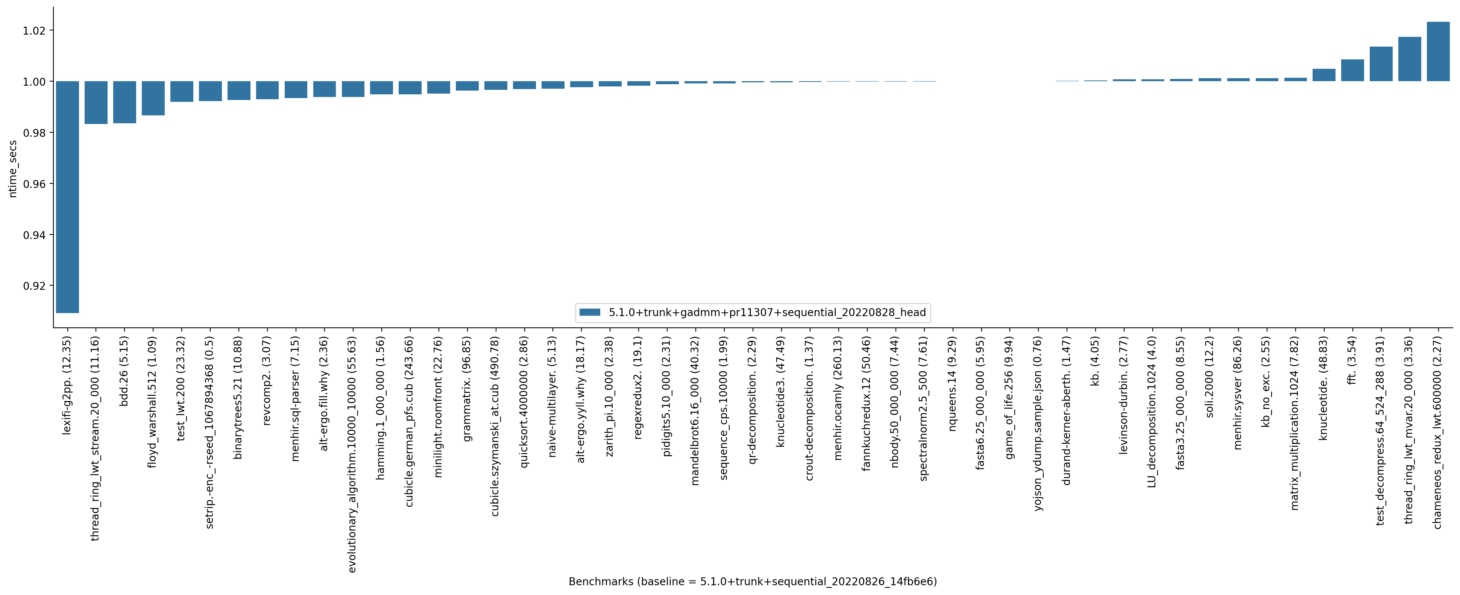
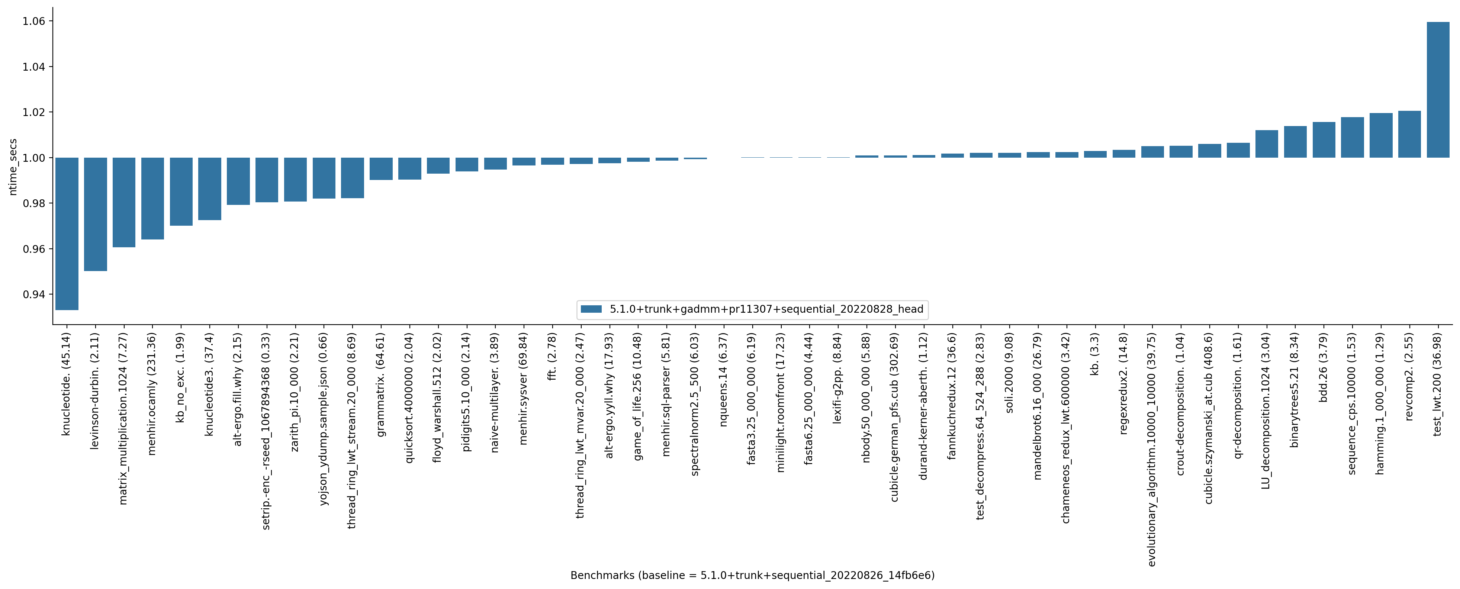
Here are results of sequential benchmarks: Turing host: Navajo host: I do not see anything too striking in these results, but I am not very familiar with this benchmark suite. The turing one looks favourable but I do not have an interpretation to offer for the good results. I am running additional benchmarks to see if the sensitivity of lwt-based benchmarks is related to fd3db5e (new unconditional polling after every blocking section). These lwt benchmarks look like micro-benchmarks, so such a slowdown (if actually caused by this change) might not be representative of real programs. |
3380e1c
to
d7727ce
Compare
|
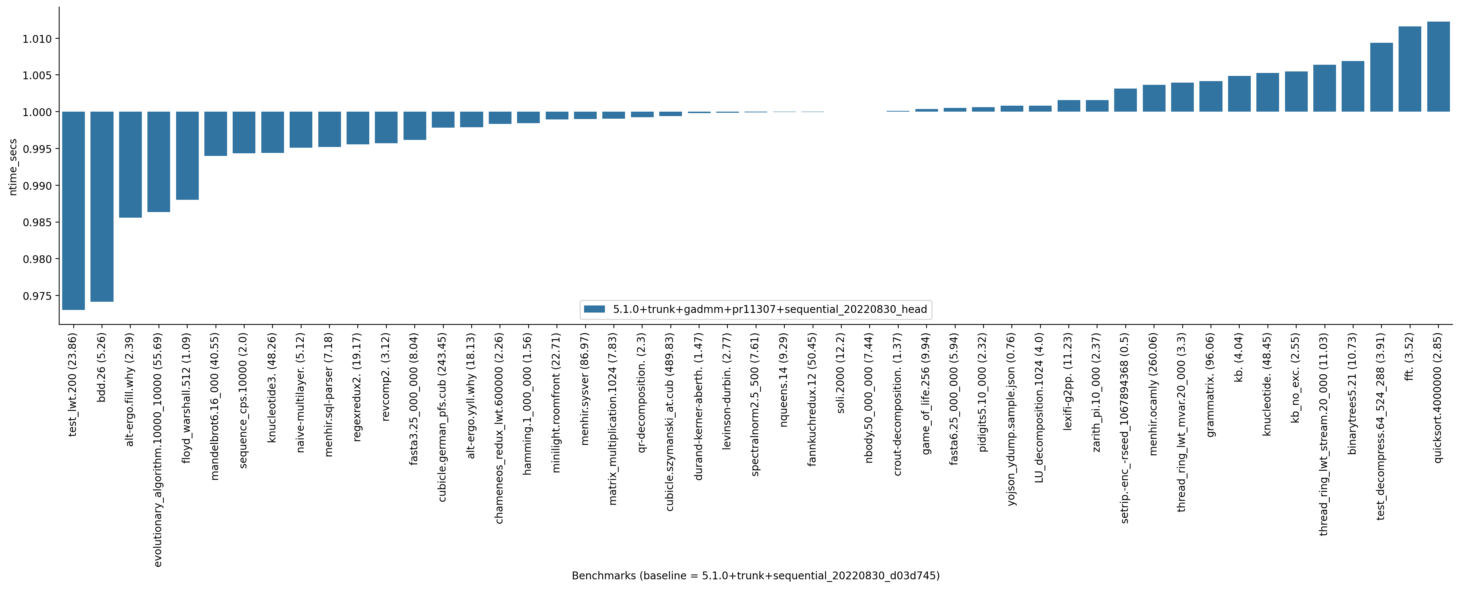
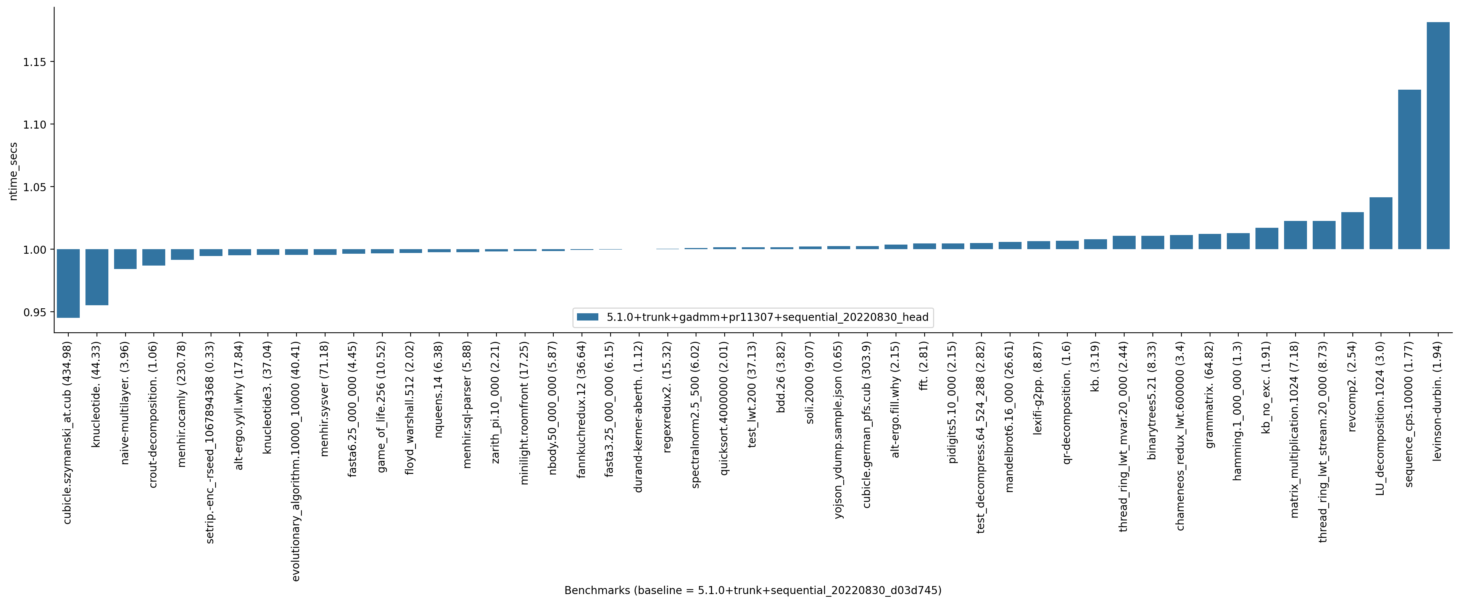
I am considering withholding the commit "Check actions unconditionally when leaving a blocking section" for now. There is a chance that it affects the lwt micro-benchmarks and although I do not think there is an issue with it, it is not needed as a bugfix. Here are the new results without this commit: Turing: Withing the limits of sandmark benchmarks, the results seem favourable. |
d7727ce
to
6945c6a
Compare
|
In the meanwhile I was looking for more portable ways to update FUNCTION(G(caml_c_call))
[…]
/* Call the function (address in %rax) */
C_call (*%rax)
> movq %rax, %r15 /* save return value */
> movq %r14, %rdi /* pass domain state as argument */
> C_call (ret_from_c_call)
> movq %r15, %rax /* restore return value */
/* Prepare for return to OCaml */
movq Caml_state(young_ptr), %r15
/* Load ocaml stack and restore global variables */
SWITCH_C_TO_OCAML
retwhich is barely simpler than the RET_FROM_C_CALL macro, for a likely measurable performance cost. So RET_FROM_C_CALL remains the best solution. |
|
Precheck is green (https://ci.inria.fr/ocaml/job/precheck/864/). Only RISC-V remains untested. |
Changes
Outdated
| @@ -105,6 +105,17 @@ Working version | |||
| (Stephen Dolan, review by Sébastien Hinderer, Vincent Laviron and Xavier | |||
| Leroy) | |||
|
|
|||
| - #11307: Finish implementing quality treatment for asynchronous | |||
| actions in multicore: soundness, liveness, and performance issues. | |||
| Do not wait that other threads have processed signals not for us in | |||
There was a problem hiding this comment.
Can you rephrase this sentence?
Do not wait that other threads have processed signals not for us in [caml_enter_blocking_section].
I don't understand this.
There was a problem hiding this comment.
I will actually remove the line. It alludes to the fix for inifinte loop at #12342 which is already in 5.1.
testsuite/tests/c-api/alloc_async.ml
Outdated
| allocations from C, but runs at the first polling location in OCaml | ||
| code after that. | ||
|
|
||
| See in particular RET_FROM_C_CALL from runtime/amd64.S. |
There was a problem hiding this comment.
Is RET_FROM_CALL necessary for this test to pass? Can you please clarify?
There was a problem hiding this comment.
There was a problem hiding this comment.
I wouldn’t mind the text being part of this PR.
There was a problem hiding this comment.
Ok, it is simpler this way
|
I tested the PR on RISC-V qemu docker container and all the tests pass. |
|
Please can you fix the conflicts in Changes? |
When a signal arrives, we interrupt all domains. This is a strategy that makes much fewer assumptions about signal-safety, threads, and domains. The point of view of this commit is that realistic uses of signals (SIGINT, SIGALRM...) make them arrive infrequently-enough that this is affordable. * In mixed C/OCaml applications, there is no guarantee that the POSIX signal handler runs in an OCaml thread so [domain_state] might not be available. * While C11 mandates that atomic thread-local variables are async-signal-safe for reading, gcc does not conform and can allocate in corner cases involving dynamic linking. * It is unclear whether the OSX implementation of [domain_state] is safe to read from signal handlers either, but this might be a theoretical concern only. * Do not make the hypothesis that the thread executing a POSIX signal handler is the most ready to execute the corresponding OCaml signal handler (e.g. Ctrl-C sent to the toplevel received by domain 0 when stuck inside [Domain.join]). * These changes allow simplifications to the spawning of threads and domains since we no longer need to mask signals during thread creation. (See subsequent commit.) The biggest risk of this change is the fact that C code allocating on the GC heap repeatedly polls without clearing pending actions until a safe point is found. By interrupting all domains when a signal arrives, the cost of this phenomenon is amplified. A subsequent commit fixes this behaviour by making sure that a signal notified to a domain causes this domain to poll only once inside C code.
As implemented by the previous bugfix commit.
As follows from the preceding commit.
Do not slow down allocations from C when an asynchronous callback cannot be handled immediately. Before this commit, an async action pending in C code, and thus not immediately processed inside allocations, is remembered by leaving [young_limit] to the max value after the allocation. Thus all subsequent allocations go through the slow path until the action is processed. There is also an [action_pending] flag which is a bit redundant in remembering that an async action is pending. This commit introduces a simpler design whereby: - [action_pending] alone is used to remember that an async action is pending, - [young_limit] is only used to interrupt running code in order to notify of new pending actions. When switching from C to OCaml, the value of [action_pending] is used to set [young_limit] for interruption as necessary. This is done when returning from C to OCaml (see RET_FROM_C_CALL) or when calling into an OCaml callback (see caml_update_young_limit_after_c_call). Other relevant changes: - We can always reset [young_limit] to its regular value inside C code and thus avoid the repeated slow path. - We make [action_pending] a _Bool (better code generation for RET_FROM_C_CALL across platforms) - [caml_set_action_pending] no longer immediately interrupts the program; the [action_pending] flag is no longer used in this way. This new design can also be seen as a step towards implementing masking (i.e. delaying async action inside OCaml code blocks just like inside C code).
Omit a redundant call to caml_set_action_pending
This depends on the "Optimal polling" commit
6e6b45f
to
f6010b9
Compare
|
Rebased and cleaned-up history. |
runtime/power.S
Outdated
| .macro RET_FROM_C_CALL | ||
| lbz TMP, Caml_state(action_pending) | ||
| cmplwi TMP, 0 | ||
| beqlr 0 |
There was a problem hiding this comment.
Bonus point for using beqlr (conditional branch to the link register), but we can mark this branch as (very) likely taken, it might help some POWER processors with the branch prediction.
| beqlr 0 | |
| beqlr+ 0 |
There was a problem hiding this comment.
I thank the clang programmers for this. Neither clang nor gcc choose beqlr+ despite the __builtin_expect, do you know why they make this choice?
|
Thanks @gadmm for persisting with the PR for more than a year! |
|
Thanks! |
Here is for your consideration a simplification of the remaining commits at #11057 (after #11095 and #11190).
This PR includes various fixes for soundness and performance of async actions.
In particular there is a bug whereby
caml_enter_blocking_sectioncan loop waiting for another domain to process its signals (sincecaml_check_pending_signalsis shared between all domains). The PR #11057 proposed two different ways to fix this:young_limitin case action are pending until one returns to OCaml code (this PR, 93dd8f28db). (Optimal Polling)Optimal Polling fixes more things than External Interrupts, and while the resulting implementation is simpler to understand, it is more invasive (e.g. changes to
.Sfiles). So I originally intended it for a part 4/4 of this PR series not needed for 5.0.While rebasing this PR, I realised that the simplifications Optimal Polling brought were greater than thought (also, there might be a bug in the current implementation of External Interrupts, so I would have to look at it again). So I decided in a first time to skip the External Interrupts design, so that you do not have to review two separate designs (where the second one undoes the changes of the first one), and go directly for the "nice" design. (For explanations of the "nice" design, see the lengthy documentation comments and commit logs.)
If you prefer starting with External Interrupts first, then we can delay the review of Optimal Polling until 5.1. If you like the Optimal Polling approach, then I will write a test to ensure that any future architecture implements the necessary code when returning from C to OCaml.
Commit logs have been updated to reflect previous discussions (cc @xavierleroy).
The commits are best reviewed separately. In case of the "Optimal Polling" commit, looking at the resulting implementation (and checking that it matches the description in the comments) might make more sense than looking only at the diff.
(cc @sadiqj, @gasche, @kayceesrk.)