How to implement Caffe LSTM layer by MKL-DNN #669
Comments
|
Hi @xiaoweiChen, It looks like IntelCaffe LSTM implementation rewrites LSTM cell in terms of inner product and elementwise operations, which should call corresponding DNNL layers. If you want to make more efficient implementation you will need to implement a new DNNL-based version of the layer using DNNL's RNN primitive. Do you see any differences in the cell definition or parameters? An important thing to keep in mind is that IntelCaffe relies on Intel MKL-DNN v0.21, which is not supported anymore. Transition to v1.2 will require significant changes to the codebase. If you have a Caffe model and looking for efficient inference deployment tool you may want to try OpenVINO, an Intel supported engine for deep learning model deployment. OpenVINO can run Caffe models with similar or better performance than IntelCaffe and thread safe. OpenVINO langing page: https://github.com/opencv/dldt |
|
Thanks for your reply @vpirogov In fact, I am a OpenVINO player. I have few Caffe models which have LSTM layer(s). While, OpenVINO is not support Caffe LSTM layer. So, I add the Caffe LSTM layer as the custom into OpenVINO(Base OpenVINO 2019 R3.1 OpenSource), also do some modify for model-optimizer and inference-engine and make this custom layer work well. I implement the Scale, Eltwise(SUM), FullyConnected by DNNL 1.2.1 in OpenVINO Source code. The performace is good for my team. And I have read RNN primitive, while I can not understand how to give the param to So, I open this issue, and want to get a lstm sample for caffe, or let me know how to give the param to Thanks again! |
|
At first glance LSTM in Caffe matches the definition we have. @xiaoweiChen, could you please clarify what exactly you mean by saying "let me know how to give the param to We recently added simple primitive examples for each primitive, and LSTM is one of them. Did you have a change to look at it? |
|
Thanks for your work @emfomenk . I look your example just now. But, I also confusion for something. Preparatory working....
const int num = bottom[0]->shape(1);
const int x_dim = hidden_dim_ * 4;
const Dtype* C_prev = bottom[0]->cpu_data();
const Dtype* X = bottom[1]->cpu_data();
const Dtype* cont = bottom[2]->cpu_data();
Dtype* C = top[0]->mutable_cpu_data();
Dtype* H = top[1]->mutable_cpu_data();
for (int n = 0; n < num; ++n) {
for (int d = 0; d < hidden_dim_; ++d) {
const Dtype i = sigmoid(X[d]);
const Dtype f = (*cont == 0) ? 0 :
(*cont * sigmoid(X[1 * hidden_dim_ + d]));
const Dtype o = sigmoid(X[2 * hidden_dim_ + d]);
const Dtype g = tanh(X[3 * hidden_dim_ + d]);
const Dtype c_prev = C_prev[d];
const Dtype c = f * c_prev + i * g;
C[d] = c;
const Dtype tanh_c = tanh(c);
H[d] = o * tanh_c;
}
C_prev += hidden_dim_;
X += x_dim;
C += hidden_dim_;
H += hidden_dim_;
++cont;
}
lstm_forward::desc(
aprop,
direction,
src_layer_desc,
src_iter_h_desc,
src_iter_c_desc,
weights_layer_desc,
weights_iter_desc,
bias_desc,
dst_layer_desc,
dst_iter_h_desc,
dst_iter_c_desc);OK, preparatory work completed. I will give my opinion, may my opinion is not right. Confusion 1: My opinion: Confusion 2: In primitive example for LSTM and example rnn-inference-fp32 My opinion: Hopeful, I explain my confusions clearly. Looking for your reply! Thanks. |

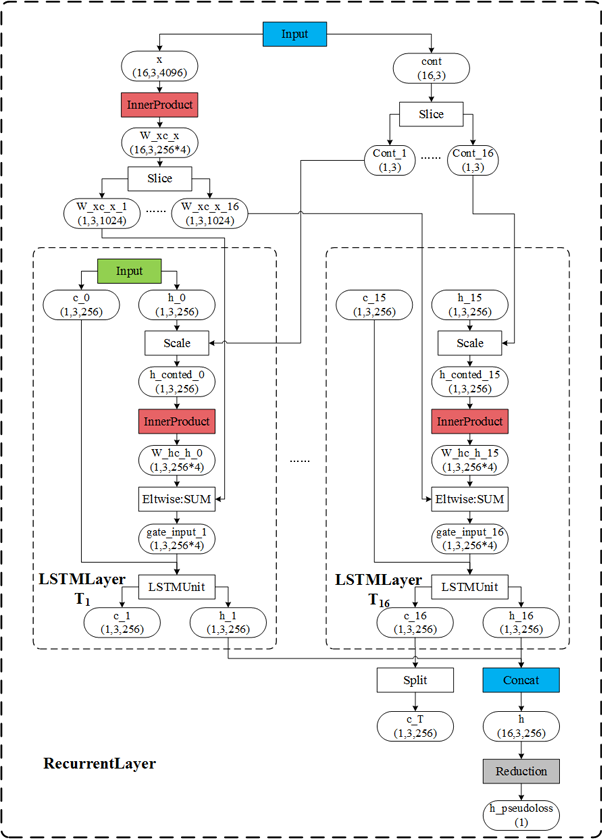
|
Hi @xiaoweiChen, Sorry for the delay with respond and thanks for the nice explanation and pictures! To be aligned on terms, let me try to map Caffe variables on DNNL names.
Parameters table: L = 1 # number of LSTM layers
D = 1 # number of directions
T = 16 # time stamps
N = 3 # batch
SLC = 4096
DIC = 256Now, coming back to your questions:
The weights that are processed in InnerProduct here, is what you showed on the first picture The InnerProduct here, corresponds to
As I mentioned above, // x
memory_desc src_layer_md({T, N, SLC}, dt::f32, format_tag::tnc);
memory src_layer(src_layer_md, engine, x);
// c_0
memory_desc src_iter_c_md({L, D, N, DIC}, dt::f32, format_tag::ldnc);
memory src_iter_c(src_iter_c_md, engine, c_0);
// c_T
memory_desc dst_iter_c_md({L, D, N, DIC}, dt::f32, format_tag::ldnc);
memory dst_iter_c(dst_iter_c_md, engine, c_T);
// h_0
memory_desc src_iter_md({L, D, N, SIC}, dt::f32, format_tag::ldnc);
memory src_iter(src_iter_md, engine, h_0);
// h_16
memory_desc dst_iter_md({L, D, N, DIC}, dt::f32, format_tag::ldnc);
memory dst_iter(dst_iter_md, engine, h_16);
// h
memory_desc dst_layer_md({T, N, DIC}, dt::f32, format_tag::tnc);
memory dst_layer(dst_layer_md, engine, h);
// W_xc
memory_desc weights_layer_md({L, D, SLC, 4, DIC}, dt::f32, format_tag::ldigo);
memory weights_layer(weights_layer_md, engine, W_xc);
// b_c
memory_desc bias_md({L, D, 4, DIC}, dt::f32, format_tag::ldgo);
memory bias(bias_md, engine, b_c);
// W_hc
memory_desc weights_iter_md({L, D, SIC, 4, DIC}, dt::f32, format_tag::ldigo);
memory weights_iter(weights_iter_md, engine, W_hc);
lstm_forward::desc(forward_inference, unidirectional_left2right,
src_layer_md, src_iter_md, src_iter_c_md,
weights_layer_md, weights_iter_md, bias_md,
dst_layer_md, dst_iter_md, dst_iter_c_md); |
|
Thanks for your words @emfomenk I known how to map the caffe lstm to dnnl lstm interface. While, base on your words, I have a question: as I know:
but...
I don't know the And I try to resolve this by myself. and use c++ implement this lstm layer, and make code compile-well. En... Unfortunately, I meet runtime error
My code paste below, may there have some argument(s) for lstm_forward::primitive_desc is wrong... |
|
In your case |
|
Thanks @emfomenk , SIC == DIC can resolve the above exception. Now, I just make the layer as a program without OpenVINO IE framework. The program would crash at LSTM execute. I try to debug this base on DNNL Release source code 1.2.1 version(on windows):
sgemm_nocopy_driver(transa, transb, myM, myN, myK, p_alpha, myA,
lda, myB, ldb, &myBeta, myC, ld, myBias, ws);The second hit would lead program crash The crash location is ker_(m, n, k, alpha, a, lda, b, ldb, beta, c, ldc, bias, ws);The local values is I found the Well, show my program code here: #include <vector>
#include "dnnl.hpp"
using SizeVector = std::vector<std::size_t>;
int main() {
std::vector<std::size_t> x_dims {16, 3, 4096};
auto x_size = 1;
for (auto num : x_dims) {
x_size *= num;
}
auto x = new float[x_size];
std::vector<std::size_t> h_dims {16, 3, 256};
auto h_size = 1;
for (auto num : h_dims) {
h_size *= num;
}
auto h = new float[h_size];
// DNNL implement
using tag = dnnl::memory::format_tag;
using dt = dnnl::memory::data_type;
dnnl::engine eng(dnnl::engine::kind::cpu, 0);
dnnl::stream s(eng);
std::size_t L = 1; // number of LSTM layers
std::size_t D = 1; // number of directions
std::size_t T = x_dims.at(0); // time stamps
std::size_t N = x_dims.at(1); // batch
std::size_t SLC = x_dims.at(2);
std::size_t DIC = h_dims.at(2);
auto SIC = DIC;
// void compile-time warning as error
long int L_i = L;
long int D_i = D;
long int T_i = T;
long int N_i = N;
long int SLC_i = SLC;
long int DIC_i = DIC;
long int SIC_i = SIC;
// x
dnnl::memory::desc src_layer_md({T_i, N_i, SLC_i}, dt::f32, tag::tnc);
//dnnl::memory src_layer(src_layer_md, eng, x->buffer());
dnnl::memory src_layer(src_layer_md, eng, x);
SizeVector inner_c_h_shape {L, D, N, DIC};
//auto inner_c_h_desc = TensorDesc(Precision::FP32, inner_c_h_shape, ANY);
auto inner_c_h_size = 1;
for (auto num : inner_c_h_shape) {
inner_c_h_size *= num;
}
// c_0
//auto c_0 = std::make_shared<TBlob<float>>(inner_c_h_desc);
//c_0->allocate();
auto c_0 = new float[inner_c_h_size];
dnnl::memory::desc src_iter_c_md(
{L_i, D_i, N_i, DIC_i}, dt::f32, tag::ldnc);
dnnl::memory src_iter_c(src_iter_c_md, eng, c_0);
memset(c_0, 0, inner_c_h_size * sizeof(float));
// c_T
//auto c_T = std::make_shared<TBlob<float>>(inner_c_h_desc);
//c_T->allocate();
auto c_T = new float[inner_c_h_size];
dnnl::memory::desc dst_iter_c_md(
{L_i, D_i, N_i, DIC_i}, dt::f32, tag::ldnc);
dnnl::memory dst_iter_c(dst_iter_c_md, eng, c_T);
memset(c_T, 0, inner_c_h_size * sizeof(float));
// h_0
//auto h_0 = std::make_shared<TBlob<float>>(inner_c_h_desc);
//h_0->allocate();
auto h_0 = new float[inner_c_h_size];
dnnl::memory::desc src_iter_md({L_i, D_i, N_i, DIC_i}, dt::f32, tag::ldnc);
dnnl::memory src_iter(src_iter_md, eng, h_0);
memset(h_0, 0, inner_c_h_size * sizeof(float));
// h_16
//auto h_16 = std::make_shared<TBlob<float>>(inner_c_h_desc);
//h_16->allocate();
auto h_16 = new float[inner_c_h_size];
dnnl::memory::desc dst_iter_md({L_i, D_i, N_i, DIC_i}, dt::f32, tag::ldnc);
dnnl::memory dst_iter(dst_iter_md, eng, h_16);
memset(h_16, 0, inner_c_h_size * sizeof(float));
// h
dnnl::memory::desc dst_layer_md({T_i, N_i, DIC_i}, dt::f32, tag::tnc);
dnnl::memory dst_layer(dst_layer_md, eng, h);
// W_xc
SizeVector W_xc_shape {L, D, SLC, 4, DIC};
auto W_xc_size = 1;
for (auto num : W_xc_shape) {
W_xc_size *= num;
}
auto W_xc = new float[W_xc_size];
dnnl::memory::desc weights_layer_md(
{L_i, D_i, SLC_i, 4, DIC_i}, dt::f32, tag::ldigo);
dnnl::memory weights_layer(weights_layer_md, eng, W_xc);
// b_c
SizeVector bias_shape {L, D, 4, DIC};
auto bias_size = 1;
for (auto num : bias_shape) {
bias_size *= num;
}
auto b_c = new float[bias_size];
dnnl::memory::desc bias_md({L_i, D_i, 4, DIC_i}, dt::f32, tag::ldgo);
dnnl::memory bias(bias_md, eng, b_c);
// W_hc
SizeVector W_hc_shape {L, D, SIC, 4, DIC};
auto W_hc_size = 1;
for (auto num : W_hc_shape) {
W_hc_size *= num;
}
auto W_hc = new float[bias_size];
dnnl::memory::desc weights_iter_md(
{L_i, D_i, SIC_i, 4, DIC_i}, dt::f32, tag::ldigo);
dnnl::memory weights_iter(weights_iter_md, eng, W_hc);
auto lstm_desc = dnnl::lstm_forward::desc(
dnnl::prop_kind::forward_inference,
dnnl::rnn_direction::unidirectional_left2right, src_layer_md,
src_iter_md, src_iter_c_md, weights_layer_md, weights_iter_md,
bias_md, dst_layer_md, dst_iter_md, dst_iter_c_md);
auto lstm_prim_desc = dnnl::lstm_forward::primitive_desc(lstm_desc, eng);
dnnl::lstm_forward(lstm_prim_desc)
.execute(s,
{
{DNNL_ARG_SRC_LAYER, src_layer},
{DNNL_ARG_WEIGHTS_LAYER, weights_layer},
{DNNL_ARG_WEIGHTS_ITER, weights_iter},
{DNNL_ARG_BIAS, bias},
{DNNL_ARG_DST_LAYER, dst_layer},
{DNNL_ARG_SRC_ITER_C, src_iter_c},
{DNNL_ARG_DST_ITER_C, dst_iter_c},
{DNNL_ARG_SRC_ITER, src_iter},
{DNNL_ARG_DST_ITER, dst_iter},
});
s.wait();
return 0;
}Because this is a small program for test, so I not use |

|
En... Now, the test program is running well. And, Tomorrow I will test this under OpenVINO IE farmework. If everything is OK, I will show the layer benchmark data here ;) |
|
Glad to head you resolved the issues :) |
|
hi @emfomenk , I use the test program code into framework, but get the wrong result. I move out my caffe LSTM implement from framework(also use DNNL to implement). I shared my test code and implment code here: Two questions here:
You can see the If you have time, please help me. I don't know where is wrong... Thanks!!! |
|
I will close this issue. The last question is a precision question, may. I find the way to resolve this question. and make the result same with my caffe lstm implementation. I do some modify in jit_uni_rnn_common_postgemm.hpp, this part dnnl use 'kernel_' to compute the lstm-cell, and this use assembly with xbyak. I am not familar with xbyak, I can not dump the optimization code. So I have no idea for which part is wrong in assembly. Well, I paste the modify code here.
...
template <typename src_data_t, typename acc_data_t, typename scratch_data_t>
rnn_postgemm_sig(execute_fwd) {
using namespace rnn_utils;
rnn_utils::ws_gates_aoc<src_data_t> ws_gates(rnn, ws_gates_);
rnn_utils::ws_gates_aoc<scratch_data_t> scratch_gates(
rnn, scratch_gates_);
rnn_utils::weights_peephole_aoc_t<const float> weights_peephole(
rnn, weights_peephole_);
rnn_utils::bias_aoc_t bias(rnn, bias_);
auto src_iter_ld = rnn.src_iter_ld(cell_position);
auto src_iter_c_ld = rnn.src_iter_c_ld(cell_position);
auto dst_iter_c_ld = rnn.dst_iter_c_ld(cell_position);
auto dst_ld = rnn.dst_ld(cell_position);
auto dst_copy_ld = rnn.dst_copy_ld(cell_position);
rnn_utils::ws_states_aoc<src_data_t> states_t_l(
rnn, states_t_l_, dst_ld);
rnn_utils::ws_states_aoc<src_data_t> states_t_l_copy(
rnn, states_t_l_copy_, dst_copy_ld);
rnn_utils::ws_states_aoc<const src_data_t> states_tm1_l(
rnn, states_tm1_l_, src_iter_ld);
rnn_utils::ws_states_aoc<float> c_states_t_l(
rnn, c_states_t_l_, dst_iter_c_ld);
rnn_utils::ws_states_aoc<const float> c_states_tm1_l(
rnn, c_states_tm1_l_, src_iter_c_ld);
rnn_utils::ws_gates_aoc<scratch_data_t> scratch_cell(
rnn, scratch_cell_);
utils::array_offset_calculator<src_data_t, 2> ws_Wh_b(
ws_grid_, rnn.mb, rnn.dic);
static std::atomic_int cont = {0};
auto caffe_lstm_cell = [](
int dic,
int cont,
void *param2_,
const void *param3_,
void *param4_,
const void *param6_,
void *param7_) {
float *X = static_cast<float *>(param2_);
const float *biases = static_cast<const float *>(param3_);
float *h = static_cast<float *>(param4_);
const float *pre_c = static_cast<const float *>(param6_);
float *c = static_cast<float *>(param7_);
auto sigmoid = [](float x) {
return 1.f / (1.f + expf(-x));
};
auto i_index_offset = 0 * dic;
auto f_index_offset = 1 * dic;
auto o_index_offset = 2 * dic;
auto g_index_offset = 3 * dic;
for (auto index = 0; index < dic; ++index) {
auto i_index = i_index_offset + index;
auto f_index = f_index_offset + index;
auto o_index = o_index_offset + index;
auto g_index = g_index_offset + index;
auto i_gate_num = X[i_index] + biases[i_index];
auto f_gate_num = X[f_index] + biases[f_index];
auto o_gate_num = X[o_index] + biases[o_index];
auto g_gate_num = X[g_index] + biases[g_index];
auto i_gate = sigmoid(i_gate_num);
auto f_gate = cont == 0 ? 0.f : sigmoid(f_gate_num);
auto o_gate = sigmoid(o_gate_num);
auto g = tanhf(g_gate_num);
auto preC = pre_c[index];
auto c_curr = f_gate * preC + i_gate * g;
auto h_curr = o_gate * tanhf(c_curr);
c[index] = c_curr;
h[index] = h_curr;
}
};
// Todo: add parallelization on dic for the batch 1 case
// Assumption: the kernel runs a loop on dic elements
parallel_nd(rnn.mb, [&](int i) {
void *param1_ = &ws_gates(i, 0, 0); // RNN, LSTM, GRU
void *param2_ = &scratch_gates(i, 0, 0); // RNN, LSTM, GRU
const void *param3_ = &bias(0, 0); // RNN, LSTM, GRU
void *param4_ = &states_t_l(i, 0); // RNN, LSTM, GRU
void *param5_ = states_t_l_copy_
? &states_t_l_copy(i, 0)
: states_t_l_copy_; // RNN, LSTM, GRU
const void *param6_;
void *param7_, *param8_;
void *param9_ = nullptr;
switch (pd_->cell_kind()) {
case alg_kind::vanilla_lstm:
param6_ = &c_states_tm1_l(i, 0);
param7_ = &c_states_t_l(i, 0);
param8_ = (void *)&weights_peephole(0, 0);
break;
case alg_kind::lbr_gru:
param6_ = &states_tm1_l(i, 0);
param7_ = &scratch_cell(i, 0, 0);
param8_ = &ws_Wh_b(i, 0);
break;
case alg_kind::vanilla_gru:
param6_ = &states_tm1_l(i, 0);
param7_ = nullptr;
param8_ = nullptr;
break;
default:
param6_ = nullptr;
param7_ = nullptr;
param8_ = nullptr;
break;
}
//kernel_(param1_, param2_, param3_, param4_, param5_, param6_,
// param7_, param8_, param9_);
caffe_lstm_cell(
rnn.dic,
cont.load(),
param2_,
param3_,
param4_,
param6_,
param7_);
});
cont.fetch_add(1, std::memory_order_relaxed);
}
...
|
|
Thanks for the analysis! The only difference I see is: auto f_gate = cont == 0 ? 0.f : sigmoid(f_gate_num);while in oneDNN we have: auto f_gate = sigmoid(f_gate_num);According to oneDNN's RNN definition (link) the
Maybe you could initialize the f-gate part of the first iteration of the input_layer data with |

|
Happy for seeing your reply and Thanks point the difference . @emfomenk In fact, I don't want to modify the code in DNNL. According your words "initialize the f-gate part of the first iteration of the input_layer data with This would not modify anything for DNNL. Emmm.... May, this is best way for me now. In your opinion, this is a good idea? or, you can give some suggestions for doing this work? |
|
You cannot modify bias, because it is the same for all timestamps: if you do so, you will get incorrect results for t=1 .. T. I suggested to initialize h0, but now, looking at the formula I realized that it will be multiplied by U-matrix, which could lead to nans (as weights could be both positive and negative). So, it seems this is the incompatibility that cannot be easily fixed. The only way to work-around this issue is to split the LSTM in to two steps: t = 0 and t = 1 ... T. For the first LSTM (with t=0) you can do the trick with the bias as you mentioned. For t = 1 .. T you just use the parameters from the model. |
Caffe LSTM implement is different from other framwork.
I want use MKL-DNN implement a Caffe LSTM.
Could give me some suggestions? Thanks!!
The text was updated successfully, but these errors were encountered: