We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition.
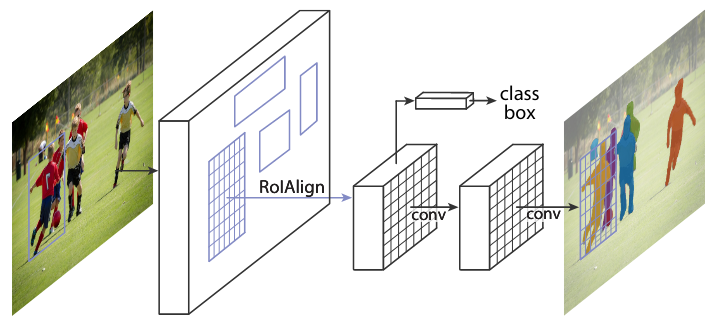
We support and provide some baseline results on nuImages dataset. We follow the class mapping in nuScenes dataset, which maps the original categories into 10 foreground categories. The convert script can be found here. The baseline results include instance segmentation models, e.g., Mask R-CNN, Cascade Mask R-CNN, and HTC. We will support panoptic segmentation models in the future.

The dataset converted by the script of v0.6.0 only supports instance segmentation. Since v0.7.0, we also support to produce semantic segmentation mask of each image; thus, we can train HTC or semantic segmentation models using the dataset. To convert the nuImages dataset into COCO format, please use the command below:
python -u tools/dataset_converters/nuimage_converter.py --data-root ${DATA_ROOT} --version ${VERSIONS} \
--out-dir ${OUT_DIR} --nproc ${NUM_WORKERS} --extra-tag ${TAG}--data-root: the root of the dataset, defaults to./data/nuimages.--version: the version of the dataset, defaults tov1.0-mini. To get the full dataset, please use--version v1.0-train v1.0-val v1.0-mini--out-dir: the output directory of annotations and semantic masks, defaults to./data/nuimages/annotations/.--nproc: number of workers for data preparation, defaults to4. Larger number could reduce the preparation time as images are processed in parallel.--extra-tag: extra tag of the annotations, defaults tonuimages. This can be used to separate different annotations processed in different time for study.
We report Mask R-CNN and Cascade Mask R-CNN results on nuimages.
| Method | Backbone | Pretraining | Lr schd | Mem (GB) | Box AP | Mask AP | Download |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | R-50 | IN | 1x | 7.4 | 47.8 | 38.4 | model | log |
| Mask R-CNN | R-50 | IN+COCO-2x | 1x | 7.4 | 49.7 | 40.5 | model | log |
| Mask R-CNN | R-50-CAFFE | IN | 1x | 7.0 | 47.7 | 38.2 | model | log |
| Mask R-CNN | R-50-CAFFE | IN+COCO-3x | 1x | 7.0 | 49.9 | 40.8 | model | log |
| Mask R-CNN | R-50-CAFFE | IN+COCO-3x | 20e | 7.0 | 50.6 | 41.3 | model | log |
| Mask R-CNN | R-101 | IN | 1x | 10.9 | 48.9 | 39.1 | model | log |
| Mask R-CNN | X-101_32x4d | IN | 1x | 13.3 | 50.4 | 40.5 | model | log |
| Cascade Mask R-CNN | R-50 | IN | 1x | 8.9 | 50.8 | 40.4 | model | log |
| Cascade Mask R-CNN | R-50 | IN+COCO-20e | 1x | 8.9 | 52.8 | 42.2 | model | log |
| Cascade Mask R-CNN | R-50 | IN+COCO-20e | 20e | 8.9 | 52.8 | 42.2 | model | log |
| Cascade Mask R-CNN | R-101 | IN | 1x | 12.5 | 51.5 | 40.7 | model | log |
| Cascade Mask R-CNN | X-101_32x4d | IN | 1x | 14.9 | 52.8 | 41.6 | model | log |
| HTC w/o semantic | R-50 | IN | 1x | model | log | |||
| HTC | R-50 | IN | 1x | model | log | |||
| HTC | R-50 | IN+COCO-20e | 1x | 11.6 | 53.8 | 43.8 | model | log |
| HTC | R-50 | IN+COCO-20e | 20e | 11.6 | 54.8 | 44.4 | model | log |
| HTC | X-101_64x4d + DCN_c3-c5 | IN+COCO-20e | 20e | 13.3 | 57.3 | 46.4 | model | log |
Note:
INmeans only using ImageNet pre-trained backbone.IN+COCO-NxandIN+COCO-Nemeans the backbone is first pre-trained on ImageNet, and then the detector is pre-trained on COCO train2017 dataset byNxandNepochs schedules, respectively.- All the training hyper-parameters follow the standard schedules on COCO dataset except that the images are resized from 1280 x 720 to 1920 x 1080 (relative ratio 0.8 to 1.2) since the images are in size 1600 x 900.
- The class order in the detectors released in v0.6.0 is different from the order in the configs because the bug in the conversion script. This bug has been fixed since v0.7.0 and the models trained by the correct class order are also released. If you used nuImages since v0.6.0, please re-convert the data through the conversion script using the above-mentioned command.