[Errno 21] Is a directory: 'data/mixture/Syn90k/label.lmdb' #1105
Comments
|
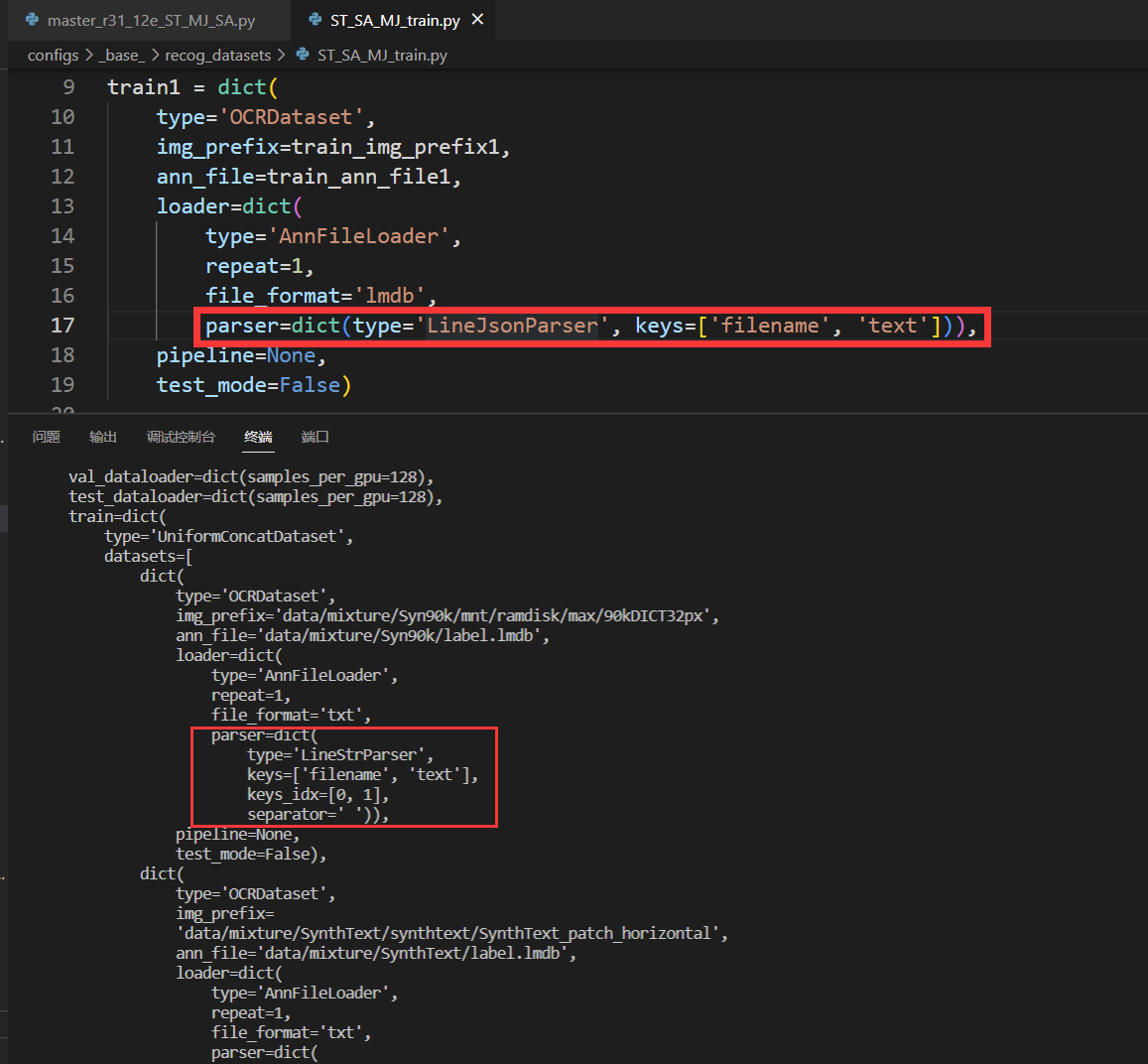
Hi @MingyuLau It seems to be the problem of dataset config. Try replacing the code as below. mmocr/configs/_base_/recog_datasets/ST_SA_MJ_train.py Lines 9 to 23 in 1f888c9
train1 = dict(
type='OCRDataset',
img_prefix=train_img_prefix1,
ann_file=train_ann_file1,
loader=dict(
type='AnnFileLoader',
repeat=1,
file_format='lmdb',
parser=dict(
type='LineJsonParser',
keys=['filename', 'text']),
pipeline=None,
test_mode=False) |
|
Thank you for dealing the problem for me immediately, and it is effective that the previos error is fixed,but this time a new "pipeline" error is raised. |

|
Maybe we need to fix more, try mmocr/configs/_base_/recog_datasets/ST_SA_MJ_train.py Lines 39 to 41 in 1f888c9
train3['loader']['file_format'] = 'txt'
tran3['loader']['parser'] = dict(
type='LineStrParser',
keys=['filename', 'text'],
keys_idx=[0, 1],
separator=' ')
train_list = [train1, train2, train3] |
|
I replace it but it raise the same error,I will check my code again |
|
@Mountchicken Sorry for bothering, I found a typo in your code yesterday, there is a missing ")" for the "loader=dict(......)", after I fix the typo, the console raise the same error "is a directory" as before |
|
@MingyuLau |
# Text Recognition Training set, including:
# Synthetic Datasets: SynthText, Syn90k
train_root = 'data/mixture'
train_img_prefix1 = f'{train_root}/Syn90k/mnt/ramdisk/max/90kDICT32px'
train_ann_file1 = f'{train_root}/Syn90k/label.lmdb'
train1 = dict(
type='OCRDataset',
img_prefix=train_img_prefix1,
ann_file=train_ann_file1,
loader=dict(
type='AnnFileLoader',
repeat=1,
file_format='lmdb',
parser=dict(
type='LineJsonParser',
keys=['filename', 'text'])),
pipeline=None,
test_mode=False)
train_img_prefix2 = f'{train_root}/SynthText/' + \
'synthtext/SynthText_patch_horizontal'
train_ann_file2 = f'{train_root}/SynthText/label.lmdb'
train_img_prefix3 = f'{train_root}/SynthText_Add'
train_ann_file3 = f'{train_root}/SynthText_Add/label.txt'
train2 = {key: value for key, value in train1.items()}
train2['img_prefix'] = train_img_prefix2
train2['ann_file'] = train_ann_file2
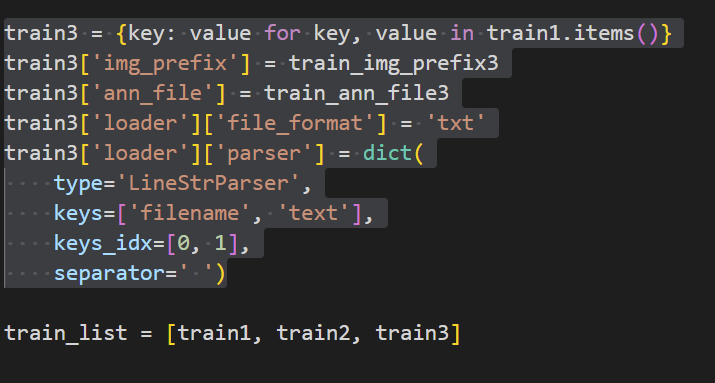
train3 = {key: value for key, value in train1.items()}
train3['img_prefix'] = train_img_prefix3
train3['ann_file'] = train_ann_file3
train3['loader']['file_format'] = 'txt'
train_list = [train1, train2, train3] |
|
@MingyuLau train_root = 'data/mixture'
train_img_prefix1 = f'{train_root}/Syn90k/mnt/ramdisk/max/90kDICT32px'
train_ann_file1 = f'{train_root}/Syn90k/label.lmdb'
train1 = dict(
type='OCRDataset',
img_prefix=train_img_prefix1,
ann_file=train_ann_file1,
loader=dict(
type='AnnFileLoader',
repeat=1,
file_format='lmdb',
parser=dict(type='LineJsonParser', keys=['filename', 'text'])),
pipeline=None,
test_mode=False)
train_img_prefix2 = f'{train_root}/SynthText/' + \
'synthtext/SynthText_patch_horizontal'
train_ann_file2 = f'{train_root}/SynthText/label.lmdb'
train_img_prefix3 = f'{train_root}/SynthText_Add'
train_ann_file3 = f'{train_root}/SynthText_Add/label.txt'
train2 = {key: value for key, value in train1.items()}
train2['img_prefix'] = train_img_prefix2
train2['ann_file'] = train_ann_file2
train3 = {key: value for key, value in train1.items()}
train3['img_prefix'] = train_img_prefix3
train3['ann_file'] = train_ann_file3
train3['loader']['file_format'] = 'txt'
train3['loader']['parser'] = dict(
type='LineStrParser',
keys=['filename', 'text'],
keys_idx=[0, 1],
separator=' ')
train_list = [train1, train2, train3] |
|
SA is in |
|
@Mountchicken |

|
And this is my structure of dataset, orgnised as the official document |

|
@MingyuLau |
|
@Mountchicken |
|
Try |
|
It makes no difference |
|
@Mountchicken |
|
@MingyuLau Are you training with master_r31_12e_ST_MJ_SA.py ? |
|
@Mountchicken _base_ = [
'../../_base_/default_runtime.py', '../../_base_/recog_models/master.py',
'../../_base_/schedules/schedule_adam_step_12e.py',
'../../_base_/recog_pipelines/master_pipeline.py',
'../../_base_/recog_datasets/ST_SA_MJ_train.py',
'../../_base_/recog_datasets/academic_test.py'
]
train_list = {{_base_.train_list}}
test_list = {{_base_.test_list}}
train_pipeline = {{_base_.train_pipeline}}
test_pipeline = {{_base_.test_pipeline}}
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
val_dataloader=dict(samples_per_gpu=8),
test_dataloader=dict(samples_per_gpu=8),
train=dict(
type='UniformConcatDataset',
datasets=train_list,
pipeline=train_pipeline),
val=dict(
type='UniformConcatDataset',
datasets=test_list,
pipeline=test_pipeline),
test=dict(
type='UniformConcatDataset',
datasets=test_list,
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='acc') |
|
@Mountchicken |
|
@MingyuLau # Text Recognition Training set, including:
# Synthetic Datasets: SynthText, Syn90k
train_root = 'data/mixture'
train_img_prefix1 = f'{train_root}/Syn90k/mnt/ramdisk/max/90kDICT32px'
train_ann_file1 = f'{train_root}/Syn90k/label.lmdb'
train1 = dict(
type='OCRDataset',
img_prefix=train_img_prefix1,
ann_file=train_ann_file1,
loader=dict(
type='AnnFileLoader',
repeat=1,
file_format='lmdb',
parser=dict(type='LineJsonParser', keys=['filename', 'text'])),
pipeline=None,
test_mode=False)
train_img_prefix2 = f'{train_root}/SynthText/' + \
'synthtext/SynthText_patch_horizontal'
train_ann_file2 = f'{train_root}/SynthText/label.lmdb'
train_img_prefix3 = f'{train_root}/SynthText_Add'
train_ann_file3 = f'{train_root}/SynthText_Add/label.txt'
train2 = {key: value for key, value in train1.items()}
train2['img_prefix'] = train_img_prefix2
train2['ann_file'] = train_ann_file2
train3 = dict(
type='OCRDataset',
img_prefix=train_img_prefix3,
ann_file=train_ann_file3,
loader=dict(
type='AnnFileLoader',
repeat=1,
file_format='txt',
parser=dict(
type='LineStrParser',
keys=['filename', 'text'],
keys_idx=[0, 1],
separator=' ')),
pipeline=None,
test_mode=False)
train_list = [train1, train2, train3] |
|
BTW, it will be appreciate if you can also raise a PR to help us fix it. |
|
It's my pleasure, and I'm sincerely grateful for all your help in this problem! |
When I tried to train MASTER on GPUs, it raised the error as below, however, I had orgnaized my data right and the directory "label.lmdb" surely had two files named "data.mdb" and "lock.mdb"
The text was updated successfully, but these errors were encountered: