NDM Memory Leak #3564
Comments
|
I am getting the same error in my home lab every 12 hrs! |
|
Same error occured in my cluster, 8 nodes using ubuntu server 22.04 LTS. In my cluster, openebs enabled localpv-hostpath and nfs.
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
NAME CPU(cores) MEMORY(bytes)
NAME READY STATUS RESTARTS AGE IP NODE |
|
I have the same problem here. Running Ubuntu 22.10 (64bit) and Kubernetes 1.23.6 (k3s) on my Rasperry PI 4 4GB. Using openebs cstor. Every x time my cluster crashes and i can't find a solution. |
|
I have the same problem on Ubuntu 20.04 and Kubernetes 1.21.14. openebs-localpv-provisioner-657db975-bzqcr 1m 27Mi
openebs-ndm-operator-55cb587666-sc5kw 1m 24Mi
openebs-ndm-qw7cr 438m 10073Mi |
|
I encountered this problem on regular k8s (not microk8s) on a single-node k8s installation on my home "lab". TL;DR: openebs ndm started eating 5-15% CPU and it's memory grew to 5GB before it killed my server. |
|
I'm also seeing high memory usage. I have only 1 pod with a pv that was provisioned by openebs. |
|
Had the same problem, raised the version of ndm and ndm operator to 2.1 and started ndm with the following arguments until I see more than 50 MB of RAM consumption was not. also added 512 MB limit.
|
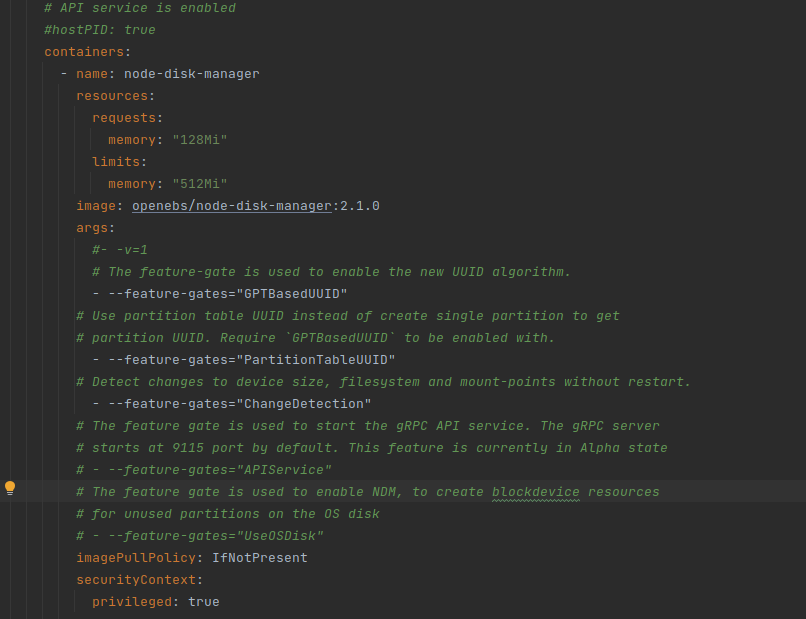
|
Same memory leak here. Only 1 node is affected that has been restarted recently. According to the logs it tries to use a RAID partition as a block device again and again in a fast loop. |
|
It looks like ndm 2.1.0 solved the problem (upgraded from 2.0). helm repo update
helm upgrade openebs openebs/openebs --namespace openebs(NB! I only had local volumes in a test cluster, no Jiva, cStore, etc. which would require further steps. See docs!) |
I was wrong, now all nodes have this memory leak problem. 🙄 |
|
4 GB RES consumed after 4 days since fresh install. I have only one volume with openebs-hostpath for nearly-clean installation of postgres. Why does this process consume more memory than the image and disk contents together? Please fix this :( |
|
I could solve this issue by excluding the devices which were perpetually tried to be used without success. I guess the logging filled up the memory. |
|
Here are the last 2k lines from the log: https://gist.github.com/daliborfilus/867558d6573b4836fc1447f7d92fdaa1 The server has these disks in it: /dev/sda is SSD, /dev/sd{b,c} are HDDs. |
|
It's repeating all over again. Just search for "Processing details for /dev/sda2". Add all device paths in between to exclude list: /dev/sda*, /dev/sdb*, /dev/sdc*, /dev/loop* |
|
Before config edit: My server restarted (because memory filled up). 5 hours after restart ndm consumed 3 GB of RAM. I've edited the config 15 minutes ago (currently 300MB RAM RES and counting): (I assume the exclusion list is a list of prefixes / partial matches, because Then I killed NDM. Logs are still spammed the same, I can see only one change (if it wasn't there previously): where previously (from the gist link above) it was: Old log: https://gist.github.com/daliborfilus/867558d6573b4836fc1447f7d92fdaa1 Btw why would log spam result in memory consumption? I would understand that if the memory was consumed by some k8s parent process (even though it would be weird too), but the logs in Go are just printed to stdout, why would it consume memory? |
|
Still no resolution on this? It's been almost a year? |
|
I'm running into this on a fresh install. |
|
Same here with openebs 3.4.0, ndm 2.1.0 and thanks @tothandor this works for me.
|
|
@snipking Can you please provide more details on how to evaluate logs? I getting that error again but never finish the |
just find out which device scan loop and exclude it. |
|
@snipking I can't figure it out. Here are my logs. Please review and point me to what is wrong. It keeps oom for one node. ======= |
These are your physical disks. Try exclude them in the openebs configmap |
|
i have meet same problem , memory leak. I1109 01:48:45.364673 7 addhandler.go:466] existingBD state Unclaimed so i trace to this code, and modify like this to avoid loop repeat scan
|

|
It should not be excluded as follows:
|

|
Request interested users to contribute for fixing this issue. |
Description
I have a microk8s cluster composed of 4 nodes.
3 master nodes are arm64, 1 worker only node is amd_64 node.
openebs has been installed as a microk8s addon.
Only on the amd64 node i see NDM leaking memory causing the node to crash after around 4 days with all the memory consumed by NDM
Expected Behavior
no memory leak
Current Behavior
leaking memory
Steps to Reproduce
microk8s enable openebs
Your Environment
The text was updated successfully, but these errors were encountered: