[REQUEST] Diagnostic regression tests #1051
Comments
From your tinkering you have a sense of what order of magnitude these differences tend to be? |
|
FTR we added some basic energy tests in 14c963f as part of the saga resolved in #808. This happened before #722; it's possible but not guaranteed that these would have caught that change. I don't know if differences in partial charges would be enough to be picked up there. The scope of |
|
It looks like that should have been caught between 0.8.3. and 0.8.4? Or, put more precisely, it looks like there were differences in the energies generated by each version of the toolkit. I generated the JSON files by running the below script after switching versions via https://gist.github.com/mattwthompson/fedfef08cf5728080a10f96023919c23 |
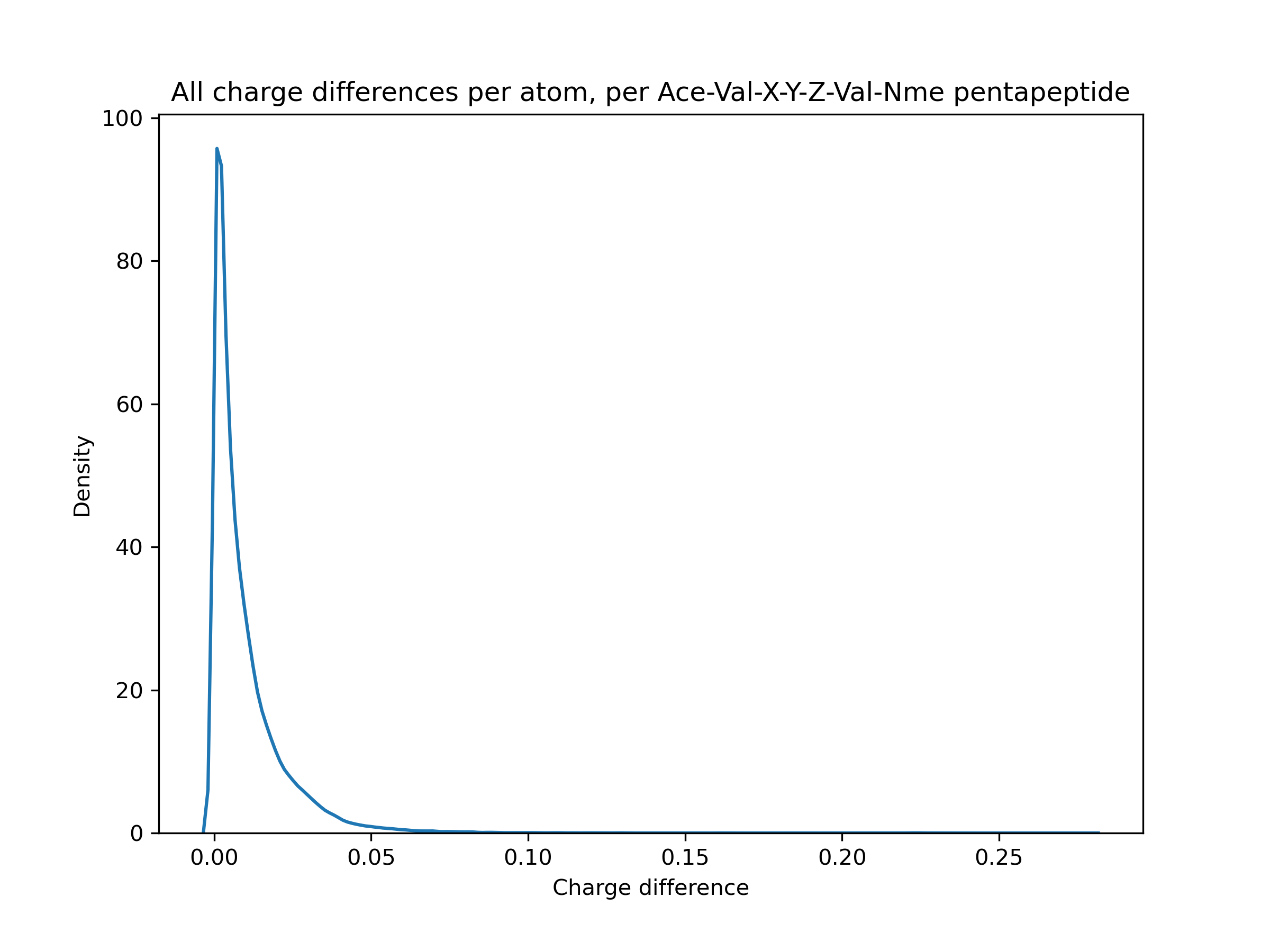
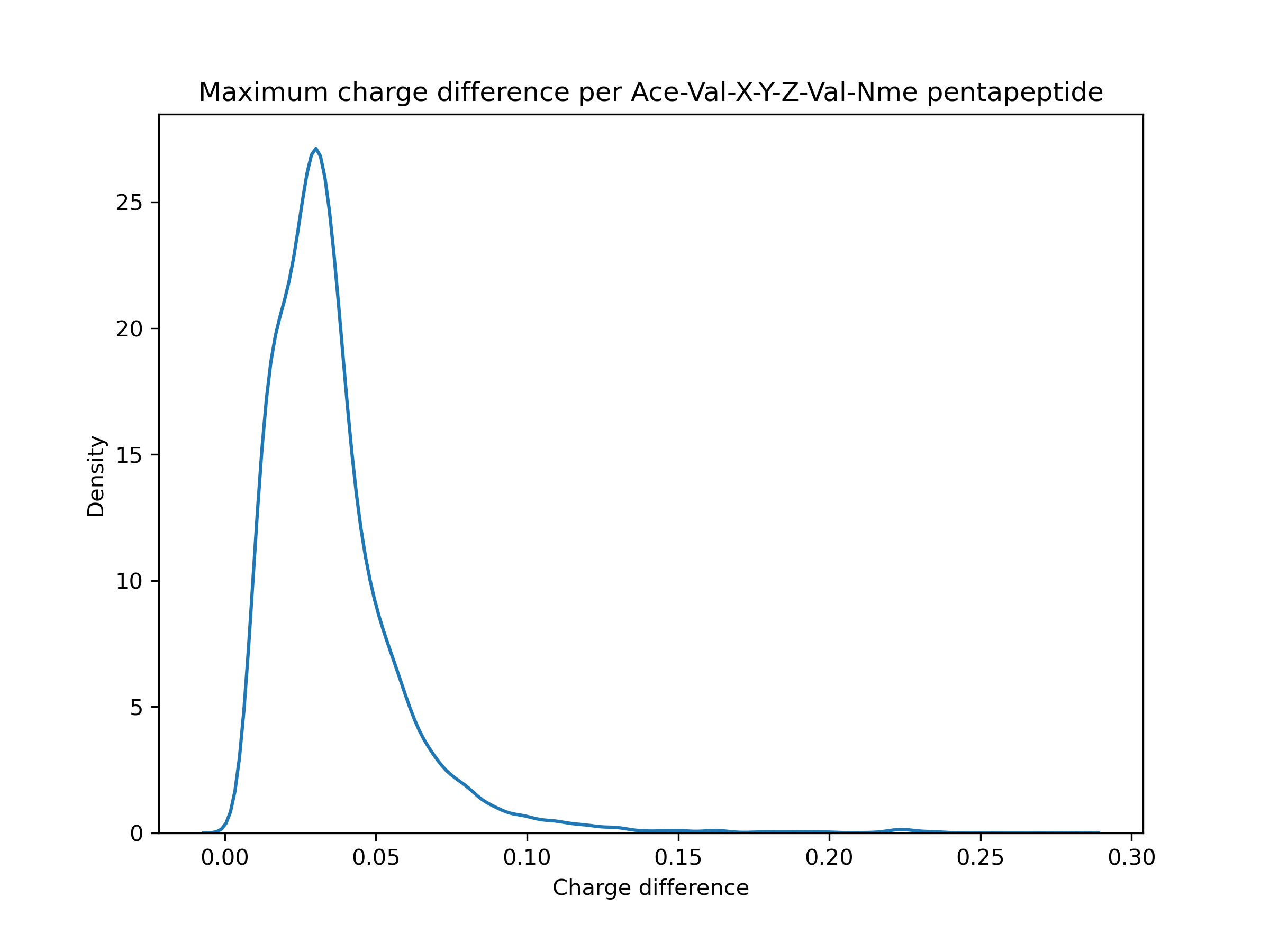
Erm, kind of. On a very specific dataset (Ace-Val-X-Y-Z-Val-Nme capped pentapeptides), mostly < 0.1 e. But that comes with caveats like only examining 1 conformer for AM1BCC instead of trying a few different ones, and I think that's a little larger than the typical molecule in the Parsley dataset. (Y is not tyrosine, just another placeholder for any amino acid). I'm still trying to figure out how high a magnitude of difference affects the energies significantly, though.
|
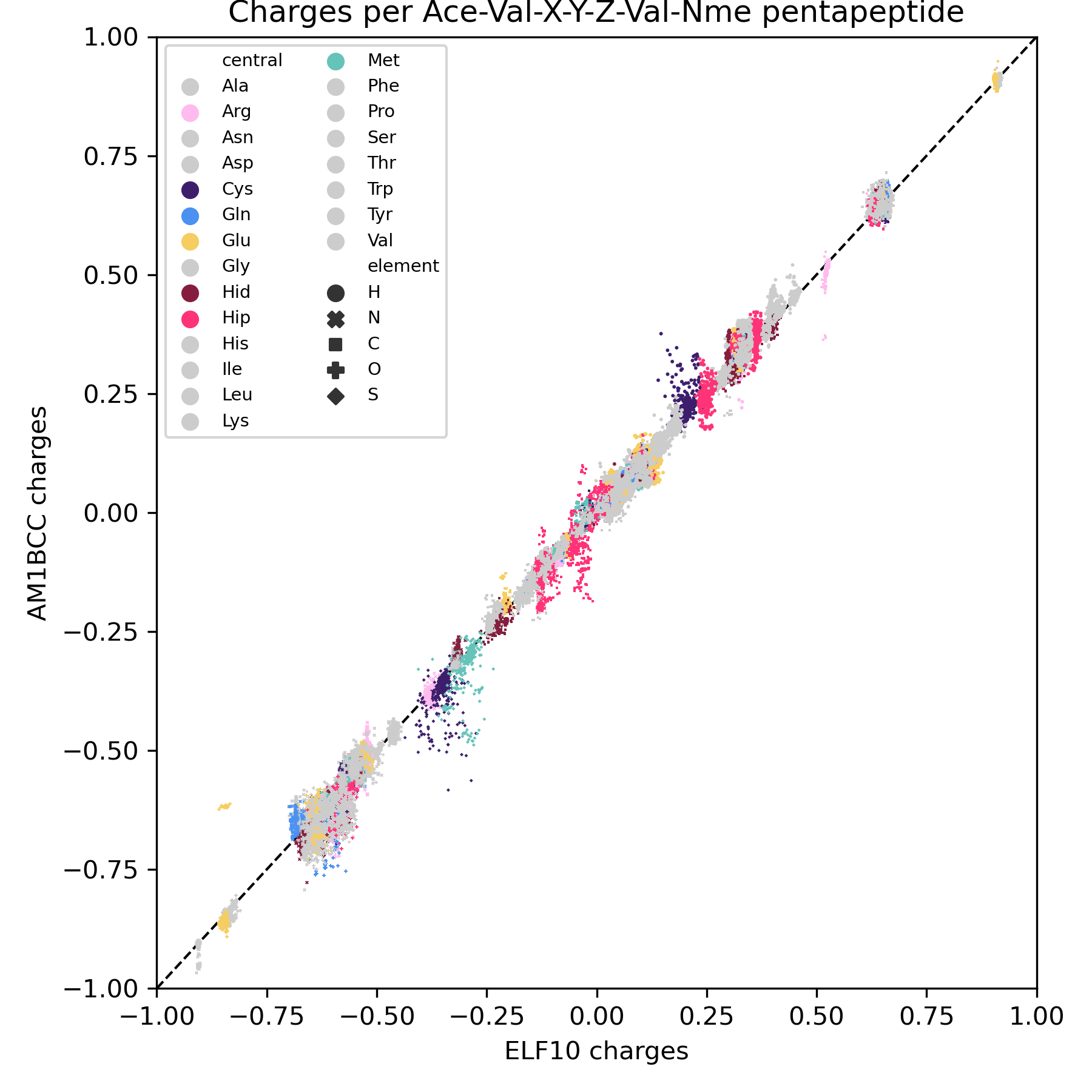
I am a little confused, #722 is tagged to be in the 0.9.1 release. Was it actually introduced in 0.8.3 or 0.8.4 ? |
|
I don't have a great feel for the lower bound of how much run-to-run/version-to-version variance is generally acceptable (mean errors of 0.1 are probably too much but tightening things to smaller errors like 0.000001 would be silly, given the other errors in MM workflows) - especially given headaches like #1019 - but my general impression here is that these errors are quite a bit bigger than we should allow silently happen. Sure, most are like 0.001 - 0.02, but there's a tail > 0.05 and even a little bump around 0.22. That seems significant.
Those milestones tend to be forward-looking, not merged into the releases they're planned on, and forgotten about after merging. I tried to infer from the dates when it was merged and when releases were made ... but I clearly did something wrong. Probably forgetting that 0.8.4 was not mainline. This S/O copy-paste says the same thing: So here's the same bit comparing 0.8.3 and 0.9.1: These (0.9.1 vs 0.8.3) are the same numbers as 0.8.4 vs. 0.8.3, which reminds me that 0.8.4 and 0.9.1 were meant to be functionally equivalent but with the old imports in order to not need to refactor the benchmarking code. Maybe I need more coffee before doing diagnostic work ... |
|
I strongly agree that we want diagnostic regression tests, such as those that would have caught this. Certainly sudden changes in charges of 0.01 or 0.1 e ought to result in issues, or energy changes of a couple of tenths of a kcal/mol ought to be caught. Some code changes will perhaps result in larger deviations than this that are OK, but we would want to know about them and assess, meaning that we really ought to have somehting in place which is flagging them for us. |
|
I'm working on a set of regression tests in another repo, which is a part of the Interchange adoption plan. Despite the naming, it's toolkit-centric and meant to test results from different conda environments, presumably with different versions of the toolkit installed. It's a work in progress and will change a few times before we want to have much faith in it, but once online it could be molded into a pre-release turnkey. A notable difference is that is mostly relies on comparing serialized representations of the OpenMM A minor annoyance is that because it's meant to test different versions of the toolkit, it compares against different Python calls, it absorbs the problems of run-to-run variance of wrapped methods. This is mostly AM1-BCC charges but can sometimes affect other things like fractional bond orders. |
|
It might be useful to put some bounds on what behavior we really must avoid regressions with, or at least split things up. If it's a matter of the charges/conformers/etc. that result from various From the other perspective, we could build things from the ground up one by one. That list of tests would be curated first from issues we've had in the past and then expanded to things we're generally worried about. |
Is your feature request related to a problem? Please describe.
Some time ago, the charge model changed from ELF10 to single-conformer AM1BCC without many people noticing, possibly unintentionally. This seems dangerous.
Describe the solution you'd like
A regression test that tests for specific "default" behaviour. I know this does not currently exist because I changed the charge model back to ELF10 and all tests passed. That means, if the model should change again, even those checking over the PR may not be fully aware. 60ce959
Describe alternatives you've considered
Perhaps the absence of failing tests means that the actual charge differences are negligible, at least in the test cases currently in the test suite. However, it would still be good for any changes to the default settings to require some change to the tests.
Additional context
The text was updated successfully, but these errors were encountered: