questions/issues on training segfix with own data #30
Comments
|
Could you share more details of your training details on your own dataset, e.g., batch-size, training crop-size? @hsfzxjy Please help to check the mentioned issues. |
|
I don't use crop (image same size as crop since) since the object is always on the same position it increases results and I have such a big amount of training data, its not needed as a augmentation. { |
|
@marcok Hi. I could not well understand what your problem is. What do you mean by "But on the validation the IoU is more or less random"? I cannot see the phenomenon from your log posted. |
|
@hsfzxjy simply said, /run_h_48_d_4_segfix.sh segfix_pred_val doesn't generate reasonable mat files. class Tester(object): |
|
@marcok thanks for your feedback. Does your problem still exist? We could help you figure out it. |
|
Hi @hsfzxjy thanks for fixing it! |
All of them print out mIoU too but only the accuracy / FScore is useful. |
|
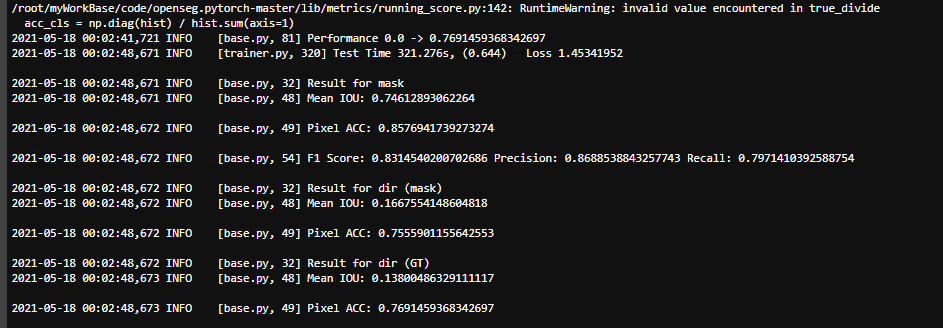
Hey @hsfzxjy I was able to train segfix on a binary segmentation data. Both Mask loss and direction loss converged well. But there wasn't any improvement in Pixel ACC of either dir (mask) or dir (GT). They just kept jumping around 0.4 +-0.04 even though direction loss converged from 2.09 to 0.8. I trained for about 50000 iterations. Is it okay for this to happen? And can you share any of your training log? |
|
Hi @i-amgeek I think it's a little strange. The ACC should be increased along with the training process. The attachment is SegFix's training log for only 20k iters. The log is in some old format, where "Result for 1" is dir (mask) and "Result for 3" is dir (GT). You may check it for comparison. btw, Did you generate the ground truth offset correctly? It may also due to incorrect supervision. |
|
Thanks for sharing log. I will look into it. I used this script to generate offsets - lib/datasets/preprocess/cityscapes/dt_offset_generator.py after changing |
|
@i-amgeek would you mind tell me how to change the H_SEGFIX.json |

|
@YAwei666 It's already specified in the Bash script so there's no need to edit config file. |
|
hi,@hsfzxjy @PkuRainBow PkuRainBow @LayneH
the result of first test on validation set is : after 54000 iteration training ,the result is the test result in 54000 is from above ,the loss get decreased, but the test result on validation set seems not to get improved , can you help me?
|


|
@dadada101 Perhaps you can open a new issue so that we can discuss better.
|
|
oh,thanks for your instant replay @hsfzxjy . |
|
@dadada101 IoU is for measuring the quality of area prediction, whilst directions have no such a concept of area, especially at some complicated edges some direction classes may be very fragmented. Of course IoU has a positive correlation with accuracy and should be as high as possible, but currently our models cannot perform so accurate and the value of IoU gets very degraded, and is not a useful reference for (roughly) evaluating the quality of direction prediction. In contrast the value of pixel accuracy is more sensitive to small boost of direction quality, but I have to admit that it's still not an appropriate metric. After all, the metrics mentioned above are just as references for picking a better SegFix model, the quality of a SegFix model should be evaluated as how much improvement it can bring to a segmentation baseline. BTW, if you want to tune SegFix models on a different dataset, we have observed that LR and crop size matters more. For LR you may try 0.01 to 0.04. For crop size you may try a smaller one than segmentation models use, e.g. on Cityscapes, segmentation models may use 769x769 or 512x1024, while SegFix adopts 512x512. |
|
@hsfzxjy ,really thanks for your prompt and detailed reply!!! |
1 similar comment
|
@hsfzxjy ,really thanks for your prompt and detailed reply!!! |
I was excited to try segfix training on my own data.
I could produce the mat files for train and val data.
Training works with run_h_48_d_4_segfix.sh and loss convergences. But on the validation the IoU is more or less random (I have 2 classes)
2020-08-20 10:47:41,932 INFO [base.py, 32] Result for mask
2020-08-20 10:47:41,932 INFO [base.py, 48] Mean IOU: 0.7853758111568029
2020-08-20 10:47:41,933 INFO [base.py, 49] Pixel ACC: 0.9692584678389714
2020-08-20 10:47:41,933 INFO [base.py, 54] F1 Score: 0.7523384841507573 Precision: 0.7928424176432377 Recall: 0.7157718538603068
2020-08-20 10:47:41,933 INFO [base.py, 32] Result for dir (mask)
2020-08-20 10:47:41,933 INFO [base.py, 48] Mean IOU: 0.5390945167184129
2020-08-20 10:47:41,933 INFO [base.py, 49] Pixel ACC: 0.7248566725097775
2020-08-20 10:47:41,933 INFO [base.py, 32] Result for dir (GT)
2020-08-20 10:47:41,934 INFO [base.py, 48] Mean IOU: 0.41990305666871003
2020-08-20 10:47:41,934 INFO [base.py, 49] Pixel ACC: 0.6007717101395131
to investigate the issue further I tried to analyse the predicted mat files with
bash scripts/cityscapes/segfix/run_h_48_d_4_segfix.sh segfix_pred_val 1
with "input_size": [640, 480] this exception happens:
File "/home/rsa-key-20190908/openseg.pytorch/lib/datasets/tools/collate.py", line 108, in collate
assert pad_height >= 0 and pad_width >= 0
after fixing it more or less, iv got similar results as val during training
They were around 3Kb instead of ~70kb
btw, it took "input_size": [640, 480] config from "test": { leave instead "val": {
is it possible validation only works with "input_size": [2048, 1024],?
Can you give me any hints how to manually verify the .mat files of there correctness? Currently I'm diving into 2007.04269.pdf and the code of dt_offset_generator.py to get an understanding.
The text was updated successfully, but these errors were encountered: