server resets connection after client hello (4 extra timestamp bytes) (v1.1.1f,g,k; but not on debian 11; really weird) #17140
Comments
|
In TLSv1.3 the Random field is defined as a 32-bit random number. In TLSv1.2 and below it is defined as a 4 byte time value followed by 28 bytes of random data. However the standard is explicit that the 4 byte time value does not have to be correct! From RFC5246
So it would be incorrect for an implementation to reject a handshake on the basis of an unexpected time value in the random. In fact I tried hacking s_client to set the |
|
I believe that the browsers are not able to connect to bmbwf.gv.at:443 either. But they automatically try www.bmbwf.gv.at:443 and that works and it works with s_client as well. |
|
I can confirm I can connect to www.bmbwf.gv.at on all hosts that do not work without the www subdomain.
|
|
The actual error in linkchecker somehow seems to indicate it does use the www subdomain and still it does not work: (Linkchecker - again, using the same version - does work on my Debian 11 host) Update: @t8m: Which OS do you use to successfully connect to the www subdomain? And do you get the error when connecting without the www subdomain on the same host? I only have two kinds of host:
I can officially pronounce I'm thoroughly confused now. |
|
Could it be that that server has a server farm with load balancer servicing it? If one server in the farm has a different configuration to the others then it could be that if you happen to connect to the "correct" one then it works. Otherwise it fails. Are you sure debian 11 always works? You might like to try it again and see if it still works. I have seen strange scenarios where different people get different results with the same configuration due to this kind of thing. |
|
Yes, this might cause such issues, I know. |
As I mentioned above:
So, I'm confident that it is not related to the time value in the random. |
|
I just copied over the slightly differing openssl.cnf from Debian 11, but it does not make a difference. The only explanation that comes to mind is that I somehow always get loadbalanced to the same (group of correctly configured) server(s) from my Debian 11 host, probably because the allocation algorithm takes the source IP or something else specific to this host into account and always directs my traffic to the working host(s), though this is just a wild guess. I'll try to contact the relevant persons in charge to try to get a fix. I'll get back to this issue if there's a fix on server side, thanks for your great support guys! |
|
Seems to be fixed on server side, though I never got an answer. |
This issue is so strange I don't know where to look next.
On Debian 10 (
1.1.1g-1+0~20200421.17+debian9~1.gbpf6902f) and Ubuntu 20.04.3 LTS (1.1.1f-1ubuntu2.9) , if I issueI always get a connection reset directly after the client hello(
write:errno=104). So does curl (curl: (35) Unknown SSL protocol error in connection to www.bmbwf.gv.at:443orcurl: (35) OpenSSL SSL_connect: Connection reset by peer in connection to www.bmbwf.gv.at:443)Browsers are happy with the site, however, and so is Debian 11 with
1.1.1k-1+deb11u1.The weird part is this: if I install the exact same version of openssl (Debian 11's 1.1.1k) from the exact same .deb on Ubuntu 20.04 as a test as well, along with libssl1.1, I still get the error on Ubuntu!
I cannot wrap my head around this.
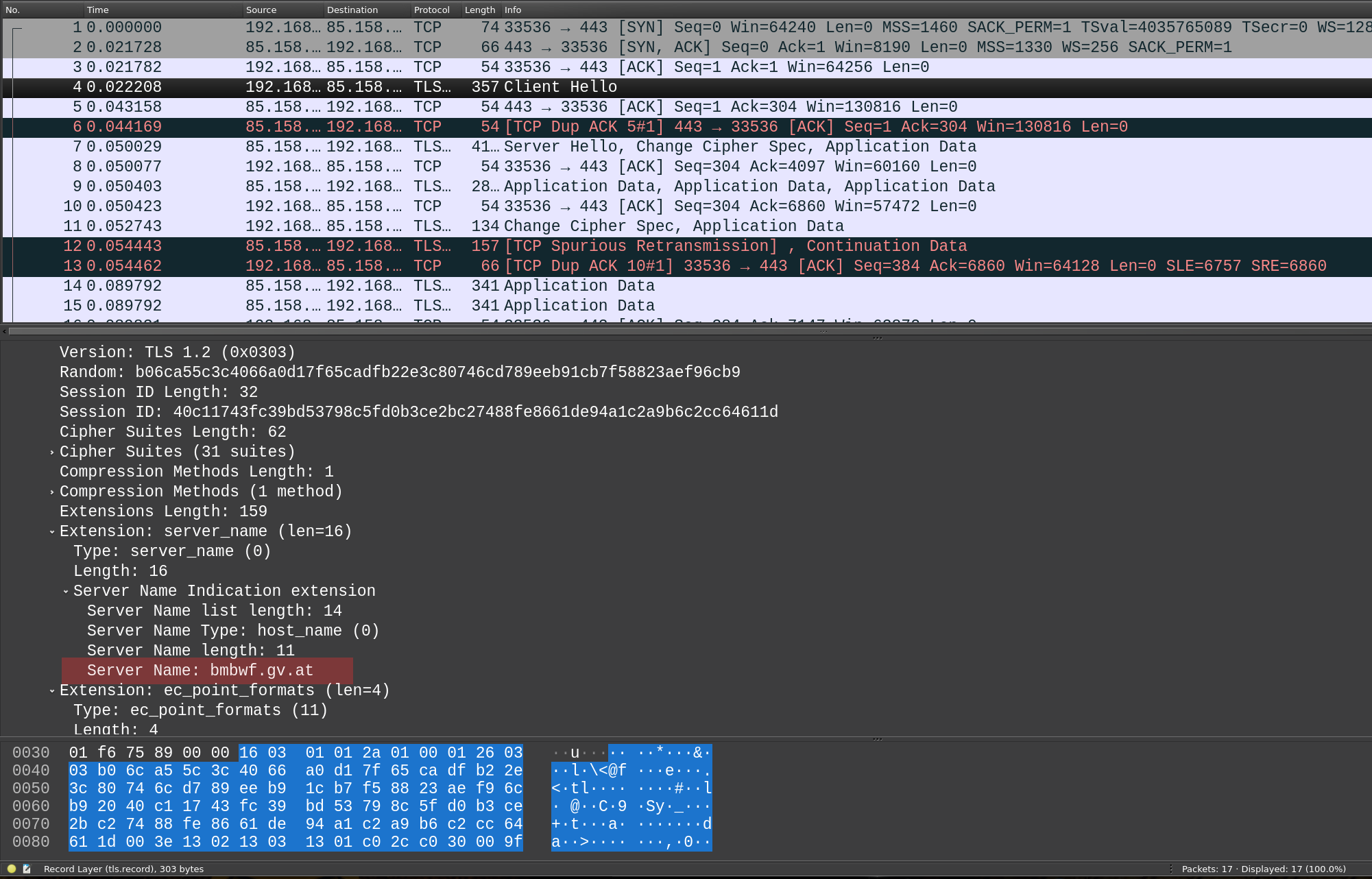
The only difference I see in packet captures is an invalid
GMT Unix Timestamp, and the request on every OS but Debian 11 has these 4 extra bytes!What's also strange is that
TLSv1vsTLSv1.3foldout identifier (highlighted; it's no actual field I think but some deduction done by wireshark) although the actualVersionfields below it do not differ. Maybe that's a consequence of these 4 extra bytes?Is it somehow configurable system-wide to use the timestamp?
I only found SSL_MODE_SEND_CLIENTHELLO_TIME in older sources but I am not sure how this could be (un)set system wide?
Can anyone not on a Debian 11 (based distros) reproduce this?
It must be something server-specific because I don't see this with any other server, but on the other hand, browsers seem happy so the server can't be configured in a wrong way. ssllabs.com output is also good.
On the other hand it's clearly a client problem as well. It seems the server is the only one being stricter when presented with a(n invalid) timestamp field (and rightly so).
Thanks in advance!
The text was updated successfully, but these errors were encountered: