[Bug] Decoding Semantic Segmentation output blob #6404
Comments
|
Hi, if possible can you share your model for testing purposes from our end? |
|
@Iffa-Meah were you able to access the models? |
|
Yes I can. We are investigating this and will get back to you asap. |
|
Hi @Eashwar93 , I had tested your model, and in terms of model inferencing, it seems that nothing's wrong. You may refer to my attachments. However, bear in mind that OpenVINO applications have their own scope where it could not support some layers or some model's topologies and it's hard to tell just by looking at your snippets or your given files (they are already processed into binaries where we couldn't see the src, even we could see the src how can we determine something like model's topology, unless it stated). Since you custom this, you should know better what's your model's details are. For supported topology, you may cross-check here Plus, I believe because of too many elements that could cause this, you were suggested here to use OpenVINO's official models: Image Segmentation Python Demo and Image Segmentation C++ Demo You may use that model and train it to fulfill your aim. The sample application (segmentation_demo.py) can be used as your reference for inferencing.
|
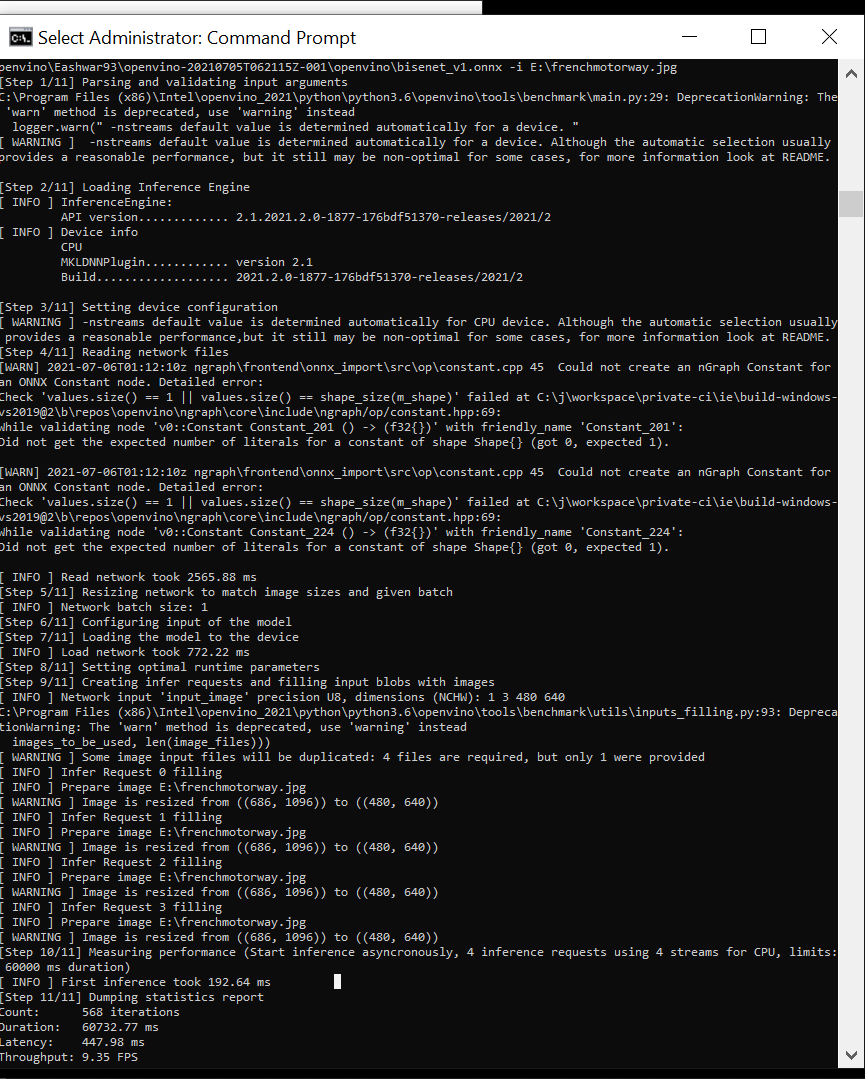

|
@Iffa-Meah Thank you for your detailed analysis. The segmentation model that I am using, exactly meets our expectations in-terms of quality and latency. I used a PyTorch model that I converted to an ONNX model which was the input for the Model Optimizer and all these files have been shared to you. In-case if you want to dig deeper into the model topology, I suggest using the the netron. You could load the ONNX model or the Openvino model and visualize the topology. The custom model I use has no fancy operation just 2Dconvs, relus, BN, Pooling, argmax, upsample. It is not a very unique model with completely different operations. Anyways thank you for your support. In-case if you find anything else that would help me in deploying the custom models please let me know. I think there is a possibility of bug in the model optimizer as far as I see. I notice two outputs from the output of Model optimizer while I have only one output from the original model. I found this using Netron as well |
|
@Eashwar93 could you please provide details how do you convert pytorch model to ONNX and then how do you convert ONNX model to IR? The issue we currently see is that your ONNX model has single output layer (which is perfectly OK), but IR model has two outputs (what is not expected in OMZ demo) |
|
@vladimir-dudnik I totally agree that your demo doesn't support models with multiple input or output and I could find the checks that you do to prevent those types of model from being used by your demo. Conversion of PyTorch to ONNX import argparse
import os.path as osp
import sys
sys.path.insert(0, '.')
import torch
from networks import model_factory
from configs import cfg_factory
torch.set_grad_enabled(False)
parse = argparse.ArgumentParser()
parse.add_argument('--model', dest='model', type=str, default='bisenetv1',)
parse.add_argument('--weight-path', dest='weight_pth', type=str, default='./res/bisenet_v1.pth')
parse.add_argument('--outpath', dest='out_pth', type=str, default='./res/bisenetv1.onnx')
args = parse.parse_args()
cfg = cfg_factory[args.model]
if cfg.use_sync_bn: cfg.us_sync_bn = False
net = model_factory[cfg.model_type](cfg.categories, aux_output=False, export=True)
net.load_state_dict(torch.load(args.weight_pth), strict=False)
net.eval()
dummy_input = torch.randn(1, 3, 480, 640)
input_names = ['input_image']
output_names = ['preds',]
torch.onnx.export(net, dummy_input, args.out_pth,
input_names=input_names, output_names=output_names,
verbose=False, opset_version=11)ONNX to IR: python3 /opt/intel/openvino_2021/deployment_tools/model_optimizer/mo.py -m ~/openvino_models/onnx/bisenet_v1.onnx\
-o ~/openvino_models/ir --input_shape [1,3,480,640] --data_type FP16 --output preds\
--input input_image --mean_values [123.675,116.28,103.52] --scale_values [58.395,57.12,57.375]I perform a normalization of image during training and hence I have used the same parameters(mean and variance/scale). |
|
Probably I can share the PyTorch model which might give a better understanding of all the operation involved. The ResNet18 module is a part of the main model as well. I think with these model file, it becomes very clear about the model creation while converting to ONNX. Let me know if you need any other details import torch
import torch.nn as nn
import torch.utils.model_zoo as modelzoo
from ptflops import get_model_complexity_info
import time
resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
from torch.nn import BatchNorm2d
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, in_chan, out_chan, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_chan, out_chan, stride)
self.bn1 = BatchNorm2d(out_chan)
self.conv2 = conv3x3(out_chan, out_chan)
self.bn2 = BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if in_chan != out_chan or stride != 1:
self.downsample = nn.Sequential(
nn.Conv2d(in_chan, out_chan, kernel_size=1, stride=stride, bias=False),
BatchNorm2d(out_chan),
)
def forward(self,x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.relu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
shortcut = x
if self.downsample is not None:
shortcut = self.downsample(x)
out = shortcut + residual
out = self.relu(out)
return out
def create_layer_basic(in_chan, out_chan, bnum, stride=1):
layers = [BasicBlock(in_chan, out_chan, stride=stride)]
for i in range (bnum-1):
layers.append(BasicBlock(out_chan, out_chan, stride=1))
return nn.Sequential(*layers)
class Resnet18(nn.Module):
def __init__(self):
super(Resnet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
self.layer3 = create_layer_basic(128,256, bnum=2, stride=2)
self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
self.init_weight()
def forward(self, x):
first_conv = self.conv1(x)
first_conv = self.bn1(first_conv)
first_conv = self.relu(first_conv)
x = self.maxpool(first_conv)
x = self.layer1(x)
feat8 = self.layer2(x)
feat16 = self.layer3(feat8)
feat32 = self.layer4(feat16)
return first_conv, feat8, feat16, feat32
def init_weight(self):
state_dict = modelzoo.load_url(resnet18_url)
self_state_dict = self.state_dict()
for k,v in state_dict.items():
if 'fc' in k: continue
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
if __name__ == "__main__":
net = Resnet18().cuda()
x = torch.randn(1, 3, 480, 640).cuda()
net.eval()
net.init_weight()
with torch.no_grad():
torch.cuda.synchronize()
_,out8,out16,out32 = net(x)
torch.cuda.synchronize()
start_ts = time.time()
for i in range(100):
_, out8, out16, out32, = net(x)
torch.cuda.synchronize()
end_ts = time.time()
t_diff = end_ts-start_ts
print("FPS: %f" % (100 / t_diff))
macs, params = get_model_complexity_info(net, (3, 480, 640), as_strings=True,
print_per_layer_stat=False, verbose=False)
print('{:<30} {:<8}'.format('Computational complexity: ', macs))
print('{:<30} {:<8}'.format('Number of parameters: ', params))
_, out8, out16, out32 = net(x)
print("Output size 8: ", out8.size())
print("Output size 16: ", out16.size())
print("Output size 32: ", out32.size())import sys
sys.path.insert(0, '.')
import torch
import torch.nn as nn
from .resnet import Resnet18
from torch.nn import BatchNorm2d
from prettytable import PrettyTable
from ptflops import get_model_complexity_info
import time
class ConvBNRelu(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride =1, padding=1, *args, **kwargs):
super(ConvBNRelu, self).__init__()
self.conv = nn.Conv2d(in_chan, out_chan, kernel_size=ks, stride=stride, padding=padding, bias=False)
self.bn = BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class UpSample(nn.Module):
def __init__(self, n_chan, factor=2):
super(UpSample, self).__init__()
out_chan = n_chan * factor * factor
self.proj = nn.Conv2d(n_chan, out_chan, 1, 1, 0)
self.up = nn.PixelShuffle(factor)
self.init_weight()
def forward(self, x):
feat = self.proj(x)
feat = self.up(feat)
return feat
def init_weight(self):
nn.init.xavier_normal_(self.proj.weight, gain=1.)
class BiseNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, up_factor=32, *args, **kwargs):
super(BiseNetOutput, self).__init__()
self.up_factor = up_factor
out_chan = n_classes * up_factor * up_factor
self.conv = ConvBNRelu(in_chan, mid_chan, ks=3, stride=1, padding=1)
self.conv_out = nn.Conv2d(mid_chan, out_chan, kernel_size=1, bias=True)
self.up = nn.PixelShuffle(up_factor)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.conv_out(x)
x = self.up(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNRelu(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = torch.mean(feat, dim=(2,3), keepdim=True)
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)
return out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
self.arm16 = AttentionRefinementModule(256,128)
self.arm32 = AttentionRefinementModule(512,128)
self.conv_head32 = ConvBNRelu(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNRelu(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNRelu(512, 128, ks=1, stride=1, padding=0)
self.up32 = nn.Upsample(scale_factor=2.)
self.up16 = nn.Upsample(scale_factor=2.)
self.init_weight()
def forward(self, x):
_, feat8, feat16, feat32 = self.resnet(x)
avg = torch.mean(feat32, dim=(2,3), keepdim=True)
avg = self.conv_avg(avg)
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm+avg
feat32_up = self.up32(feat32_sum)
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm+feat32_up
feat16_up = self.up16(feat16_sum)
feat16_up = self.conv_head16(feat16_up)
return feat16_up, feat32_up
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.weight)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNRelu(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNRelu(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNRelu(64, 64, ks=3, stride=2, padding=1)
self.conv_out = ConvBNRelu(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x)
feat = self.conv2(feat)
feat = self.conv3(feat)
feat = self.conv_out(feat)
return feat
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params =[], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear,nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class FeatureFusionModel(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModel, self).__init__()
self.convblk = ConvBNRelu(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan, out_chan//4, kernel_size=1, stride=1, padding=0, bias=False)
self.conv2 = nn.Conv2d(out_chan//4, out_chan, kernel_size=1, stride=1, padding=0, bias=False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = torch.mean(feat, dim=(2,3), keepdim=True)
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class BiSeNetV1(nn.Module):
def __init__(self, n_classes, aux_output=True, export=False, *args, **kwargs):
super(BiSeNetV1, self).__init__()
self.cp = ContextPath()
self.sp = SpatialPath()
self.ffm = FeatureFusionModel(256, 256)
self.conv_out = BiseNetOutput(256, 256, n_classes, up_factor=8)
self.aux_output = aux_output
self.export = export
if self.aux_output:
self.conv_out16 = BiseNetOutput(128, 64, n_classes, up_factor=8)
self.conv_out32 = BiseNetOutput(128, 64, n_classes, up_factor=16)
self.init_weight()
def forward(self, x):
H, W = x.size()[2:]
feat_cp8, feat_cp16 = self.cp(x)
feat_sp = self.sp(x)
feat_fuse = self.ffm(feat_sp, feat_cp8)
feat_out = self.conv_out(feat_fuse)
if self.export:
feat_out = feat_out.argmax(dim=1)
return feat_out
if self.aux_output:
feat_out16 = self.conv_out16(feat_cp8)
feat_out32 = self.conv_out32(feat_cp16)
return feat_out, feat_out16, feat_out32
return feat_out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
for name, child in self.named_children():
child_wd_params, child_nowd_params = child.get_params()
if isinstance(child, (FeatureFusionModel, BiseNetOutput)):
lr_mul_wd_params += child_wd_params
lr_mul_nowd_params += child_nowd_params
else:
wd_params += child_wd_params
nowd_params += child_nowd_params
return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
def count_parameters(model):
table = PrettyTable(["Modules", "Parameters"])
total_params = 0
for name, parameter in model.named_parameters():
if not parameter.requires_grad: continue
param = parameter.numel()
table.add_row([name, param])
total_params+=param
print(table)
print(f"Total Trainable Params: {total_params}")
return total_params
if __name__ == "__main__":
net = BiSeNetV1(2, False).cuda()
x = torch.randn(1, 3, 480, 640).cuda()
net.eval()
net.init_weight()
with torch.no_grad():
torch.cuda.synchronize()
out = net(x)
torch.cuda.synchronize()
start_ts = time.time()
for i in range(100):
out = net(x)
torch.cuda.synchronize()
end_ts = time.time()
t_diff = end_ts-start_ts
print("FPS: %f" % (100 / t_diff))
macs, params = get_model_complexity_info(net, (3, 480, 640), as_strings=True,
print_per_layer_stat=False, verbose=False)
print('{:<30} {:<8}'.format('Computational complexity: ', macs))
print('{:<30} {:<8}'.format('Number of parameters: ', params))
out = net(x)
print("Output size: ", out.size())
count_parameters(net) |
|
@Eashwar93 thanks, there was an issue with MO in OpenVINO 2021.3 which cause generating IR with two outputs. This was fixed in the latest OpenVINO 2021.4 release, which you can try. On our side, we tried to convert your ONNX model to IR with 2021.4 release and IR contain single output, which allow to run inference with OMZ demo (although, I do not know what object classes it was trained for, it seems for generic street scene it does not detect anything meaningful). |
|
@vladimir-dudnik |
|
@Eashwar93 sure, that is OMZ Python segmentation demo output for some random "industrial" picture (we do understand that this is not a target scene, but at least model detected class 0 and class 2 on it) |

|
@vladimir-dudnik I think this looks promising, 2 represents class 'person' but with specific uniforms and 1 represents our object of interest which is not very common and 0 is the background class. Technically its a 3 class problem, sorry that I mentioned it as a 2 class problem earlier. Thanks once again. |
|
@vladimir-dudnik I have tested it in my application and it works fine. Thank you for your support. I am closing the issue. I'm also posting a very simple segmentation example in-case if anyone needs a very simple example. #include <iostream>
#include "inference_engine.hpp"
#include "opencv2/opencv.hpp"
#include <random>
#include "ie_blob.h"
#include "ocv_common.h"
/// Random color palette ///
std::vector<std::vector<uint8_t>> get_color_map()
{
std::vector<std::vector<uint8_t>> color_map(256, std::vector<uint8_t>(3));
std::minstd_rand rand_engg(123);
std::uniform_int_distribution<uint8_t> u(0, 255);
for (int i{0}; i < 256; ++i) {
for (int j{0}; j < 3; j++) {
color_map[i][j] = u(rand_engg);
}
}
return color_map;
}
int main(int argc, char* argv[] ) {
try {
if (argc != 5){
std::cout << "Usage :" << argv[0] << "<path_to_model> <path_to_image> <device_name> <path_to_store_result>" << std::endl;
}
const std::string input_model {argv[1]};
const std::string input_image_path {argv[2]};
const std::string device_name = {argv[3]};
const std::string save_pth = {argv[4]};
/// Inference Engine setup ///
InferenceEngine::Core core;
InferenceEngine::CNNNetwork network;
InferenceEngine::ExecutableNetwork executable_network;
network = core.ReadNetwork(input_model);
if (network.getOutputsInfo().size() != 1)
throw std::logic_error("Inference Engine supports only single frame inference output");
if (network.getInputsInfo().size() != 1)
throw std::logic_error("Inference Engine supports only single input");
InferenceEngine::InputInfo::Ptr input_info = network.getInputsInfo().begin()->second;
std::string input_name = network.getInputsInfo().begin()->first;
input_info->setPrecision(InferenceEngine::Precision::U8);
input_info->setLayout(InferenceEngine::Layout::NCHW);
input_info->getPreProcess().setColorFormat(InferenceEngine::ColorFormat::RGB);
if (network.getOutputsInfo().empty()){
std::cerr << "Network outputs info is empty" << std::endl;
return EXIT_FAILURE;
}
InferenceEngine::DataPtr output_info = network.getOutputsInfo().begin()->second;
std::string output_name = network.getOutputsInfo().begin()->first;
output_info->setPrecision(InferenceEngine::Precision::I32);
output_info->setLayout(InferenceEngine::Layout::CHW);
///Load Network and Synchronous Infer Request Creation///
executable_network = core.LoadNetwork(network, device_name);
InferenceEngine::InferRequest infer_request = executable_network.CreateInferRequest();
///Read image and convert to Blob ///
cv::Mat image = cv::imread(input_image_path);
InferenceEngine::Blob::Ptr imgBlob = wrapMat2Blob(image);
imgBlob->allocate();
///Inference ///
infer_request.SetBlob(input_name, imgBlob);
infer_request.Infer();
imgBlob->deallocate();
InferenceEngine::Blob::Ptr output = infer_request.GetBlob(output_name);
///Decoding and applying color map///
auto const memLocker = output->cbuffer();
const auto *res = memLocker.as<const int *>();
auto oH = output_info->getTensorDesc().getDims()[1];
auto oW = output_info->getTensorDesc().getDims()[2];
cv::Mat pred(cv::Size(oW, oH), CV_8UC3);
std::vector<std::vector<uint8_t>> color_map = get_color_map();
int idx{0};
for (int i = 0; i < oH; ++i)
{
auto *ptr = pred.ptr<uint8_t>(i);
for (int j = 0; j < oW; ++j)
{
ptr[0] = color_map[res[idx]][0];
ptr[1] = color_map[res[idx]][1];
ptr[2] = color_map[res[idx]][2];
ptr += 3;
++idx;
}
}
/// Saving the output ///
cv::imwrite(save_pth, pred);
output->deallocate();
} catch (const std::exception& ex){
std::cerr << ex.what() << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
} |
System information (version)
Detailed description
I have been working on a semantic segmentation model for a custom industrial application. The results from the Openvino framework is very different from the results i get from Pytorch. Please refer to the images, the first image is the segmentation result of Pytorch and the second is the segmentation results from OpenVino C++ API:
Please refer to the usage of Model Optimizer as shown below:
I perform a normalization of image during training and hence I have used the same parameters(mean and variance/scale). I did a quick analysis of the onnx model and IR model from Openvino. I found one striking difference which is a bit weird. The ONNX model has only one output as in the original model while the IR format has 2 outputs.
My Inference Engine integration code:
InferenceEngine::Core core; InferenceEngine::CNNNetwork network; InferenceEngine::ExecutableNetwork executable_network; network = core.ReadNetwork(input_model); /// input_model is a string path to the .xml fileInput Settings: Since my network work on RGB colour format, I perform a conversion from BGR -> RGB
Output Settings: I use the
rbegin()function instead ofbegin()to access the second output of the network as it is the desired output and the first output is just created during the model optimization step which I don't understand :(. The model has a 64 bit integer output but I set it to 32-bit int. The ouput layout is CHW with C always one and the values of the H x W represent the corresponding class of the that pixel.InferenceEngine::DataPtr output_info = network.getOutputsInfo().rbegin()->second; std::string output_name = network.getOutputsInfo().rbegin()->first; output_info->setPrecision(InferenceEngine::Precision::I32); ///The model has a 64 bit integer output but I set it to 32-bit int output_info->setLayout(InferenceEngine::Layout::CHW);Creation of Infer-request and input blob and inference
InferenceEngine::InferRequest infer_request = executable_network.CreateInferRequest(); cv::Mat image = cv::imread(input_image_path); InferenceEngine::TensorDesc tDesc( InferenceEngine::Precision::U8, input_info->getTensorDesc().getDims(), input_info->getTensorDesc().getLayout() ); InferenceEngine::Blob::Ptr imgBlob = InferenceEngine::make_shared_blob<unsigned char>(tDesc, image.data); infer_request.SetBlob(input_name, imgBlob); infer_request.Infer();Random Color palette for visualization of the result
Decoding of the output blob
Could you please tell me if I am doing something wrong? Please feel free to ask for more details.
The text was updated successfully, but these errors were encountered: