This notebook demonstrates how to use a Stable Diffusion model for image generation with OpenVINO.
It considers two approaches of image generation using an AI method called diffusion:
Text-to-imagegeneration to create images from a text description as input.Text-guided Image-to-Imagegeneration to create an image, using text description and initial image semantic.
The complete pipeline of this demo is shown below.
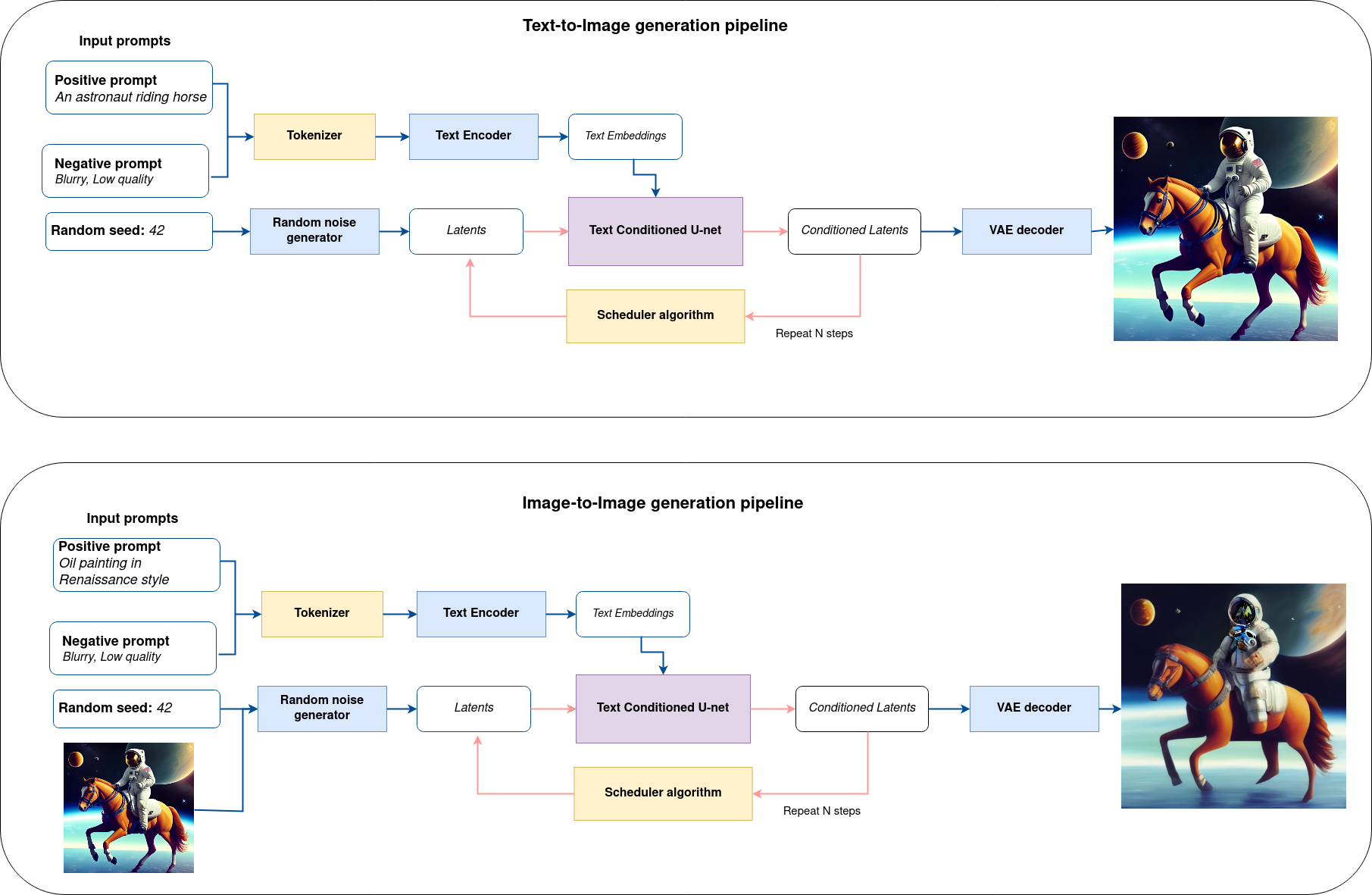
This is a demonstration in which you can type a text description (and provide input image in case of Image-to-Image generation) and the pipeline will generate an image that reflects the context of the input text. Step-by-step, the diffusion process will iteratively denoise latent image representation while being conditioned on the text embeddings provided by the text encoder.
The following image shows an example of the input sequence and corresponding predicted image.
Input text: cyberpunk cityscape like Tokyo, New York with tall buildings at dusk golden hour cinematic lighting, epic composition. A golden daylight, hyper-realistic environment. Hyper and intricate detail, photo-realistic. Cinematic and volumetric light. Epic concept art. Octane render and Unreal Engine, trending on artstation

This notebook demonstrates how to convert and run stable diffusion using OpenVINO.
Notebook contains the following steps:
- Create PyTorch models pipeline using Diffusers library.
- Convert models to OpenVINO IR format, using model conversion API.
- Run Stable Diffusion pipeline with OpenVINO.
If you have not installed all required dependencies, follow the Installation Guide.