This repository contains the dataset CoQAR and the code for training and evaluating question rewriting models. The datasets, as well as model training and evaluation methods are presented in the paper: CoQAR Question Rewriting on CoQA. Quentin Brabant, Gwenole Lecorve and Lina Rojas-Barahona, to be published in LREC2022
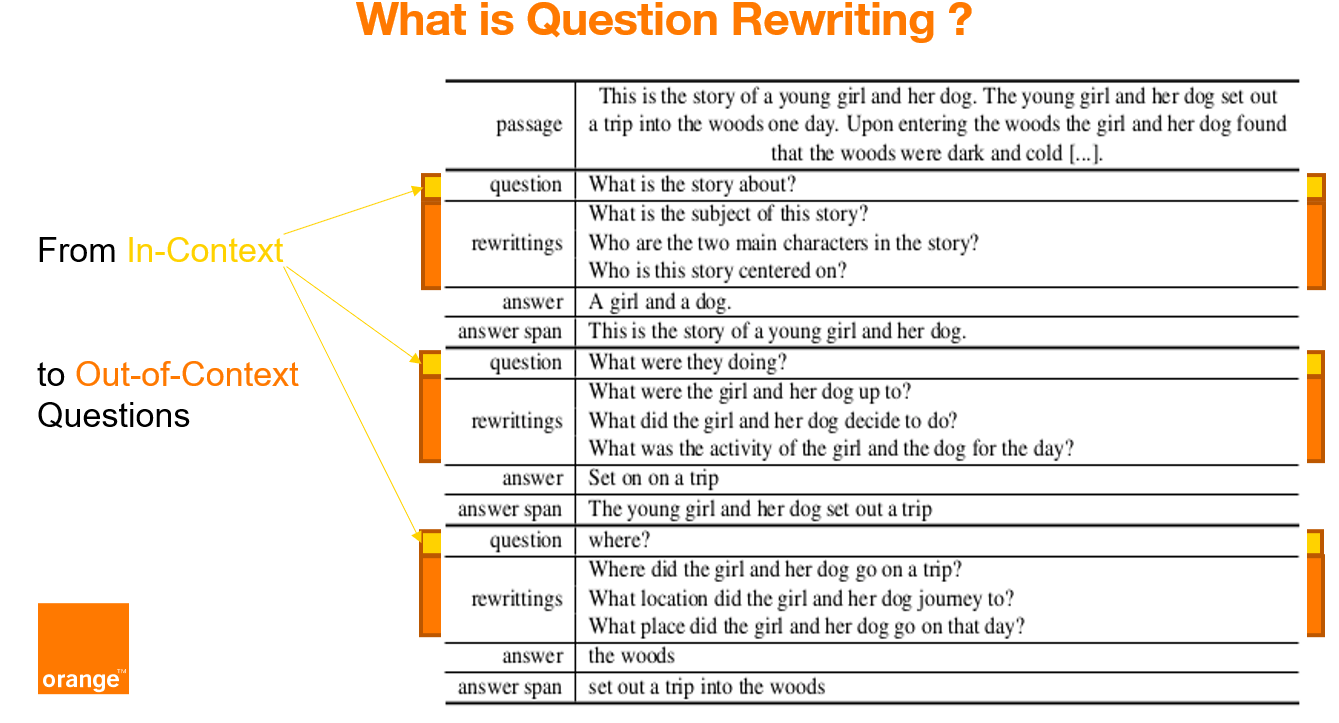
CoQAR is a corpus containing 4.5K conversations from the open-source dataset Conversational Question-Answering dataset CoQA, for a total of 53K follow-up question-answer pairs. In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
We assessed the quality of COQAR's annotations by conducting several experiments for question paraphrasing, question rewriting and conversational question answering. Our results support the idea that question rewriting can be used as a preprocessing step for non-conversational question answering models, thereby increasing their performances.
The code for training and evaluation question rewriting models is in the rewriting folder.
The code is published under the licence Apache 2.0, as the models are taken from HuggingFace. The annotations are published under the licence CC-BY-SA 4.0. The original content of the dataset CoQA is under the distinct licences described below.
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
- Children's stories are collected from MCTest which comes with MSR-LA license.
- Middle/High school exam passages are collected from RACE which comes with its own license.
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015).