- Correlation is between -1 to 1, covariance is -inf to inf, units in covariance affect the scale, so correlation is preferred, it is normalized.
Correlation is a measure of association. Correlation is used for bivariate analysis. It is a measure of how well the two variables are related.
Covariance is also a measure of association. Covariance is a measure of the relationship between two random variables.
-
Association vs correlation - correlation is a measure of association and a yes no question without assuming linearity
-
A great article in medium, covering just about everything with great detail and explaining all the methods plus references.
-
Heat maps for categorical vs target - groupby count per class, normalize by total count to see if you get more grouping in a certain combination of cat/target than others.
-
Anova/log regression 2*, git, 3, for numeric/cont vs categorical - high F score from anova hints about association between a feature and a target, i.e., the importance of the feature to separating the target.
-
image by multiple possible sources, rayhanul islam, statistics for fun.
-
Cat vs cat, many metrics - on medium
Is an asymmetric, data-type-agnostic score for predictive relationships between two columns that ranges from 0 to 1. github

Too many scenarios where the correlation is 0. This makes me wonder if I missed something… (Excerpt from the image by Denis Boigelot)\
Regression
In case of an regression, the ppscore uses the mean absolute error (MAE) as the underlying evaluation metric (MAE_model). The best possible score of the MAE is 0 and higher is worse. As a baseline score, we calculate the MAE of a naive model (MAE_naive) that always predicts the median of the target column. The PPS is the result of the following normalization (and never smaller than 0):\
PPS = 1 - (MAE_model / MAE_naive)\
Classification
If the task is a classification, we compute the weighted F1 score (wF1) as the underlying evaluation metric (F1_model). The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal. The weighted F1 takes into account the precision and recall of all classes weighted by their support as described here. As a baseline score (F1_naive), we calculate the weighted F1 score for a model that always predicts the most common class of the target column (F1_most_common) and a model that predicts random values (F1_random). F1_naive is set to the maximum of F1_most_common and F1_random. The PPS is the result of the following normalization (and never smaller than 0):\
PPS = (F1_model - F1_naive) / (1 - F1_naive)\
Paper - we present a measure of dependence for two-variable relationships: the maximal information coefficient (MIC). MIC captures a wide range of associations both functional and not, and for functional relationships provides a score that roughly equals the coefficient of determination (R2) of the data relative to the regression function.\
Computing MIC
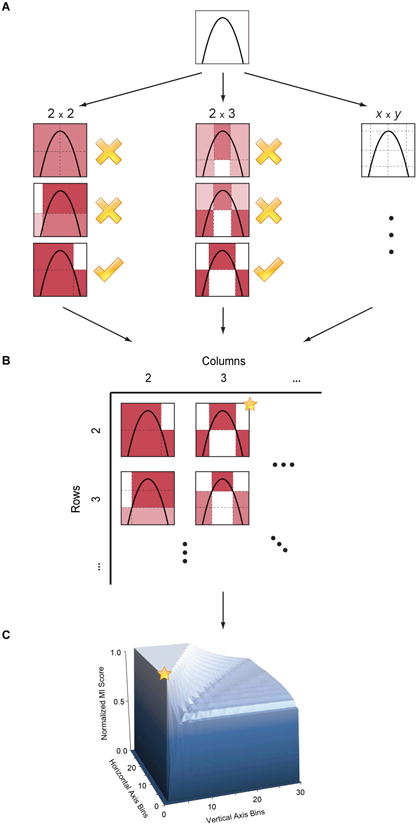
(A) For each pair (x,y), the MIC algorithm finds the x-by-y grid with the highest induced mutual information. (B) The algorithm normalizes the mutual information scores and compiles a matrix that stores, for each resolution, the best grid at that resolution and its normalized score. (C) The normalized scores form the characteristic matrix, which can be visualized as a surface; MIC corresponds to the highest point on this surface. \
In this example, there are many grids that achieve the highest score. The star in (B) marks a sample grid achieving this score, and the star in (C) marks that grid's corresponding location on the surface.\
Mutual information classifier - Estimate mutual information for a discrete target variable.
Mutual information (MI) [1] between two random variables is a non-negative value, which measures the dependency between the variables. It is equal to zero if and only if two random variables are independent, and higher values mean higher dependency.
The function relies on nonparametric methods based on entropy estimation from k-nearest neighbors distances as described in [2] and [3]. Both methods are based on the idea originally proposed in [4].\
MI score - Mutual Information between two clusterings.
The Mutual Information is a measure of the similarity between two labels of the same data. \
Adjusted MI score - Adjusted Mutual Information between two clusterings.
Adjusted Mutual Information (AMI) is an adjustment of the Mutual Information (MI) score to account for chance. It accounts for the fact that the MI is generally higher for two clusterings with a larger number of clusters, regardless of whether there is actually more information shared.
This metric is furthermore symmetric: switching label_true with label_pred will return the same score value. This can be useful to measure the agreement of two independent label assignments strategies on the same dataset when the real ground truth is not known\
Normalized MI score - Normalized Mutual Information (NMI) is a normalization of the Mutual Information (MI) score to scale the results between 0 (no mutual information) and 1 (perfect correlation). In this function, mutual information is normalized by some generalized mean of H(labels_true) and H(labels_pred)), defined by the average_method.\
A series of good articles that explain about several techniques for feature selection
- How to parallelize feature selection on several CPUs, do it per label on each cpu and average the results.
- A great notebook about feature correlation and manytypes of visualization, what to drop what to keep, using many feature reduction and selection methods (quite a lot actually). Its a really good intro
- Multi class classification, feature selection, model selection, co-feature analysis
- Text analysis for sentiment, doing feature selection a tutorial with chi2(IG?), part 2 with bi-gram collocation in ntlk
- What is collocation? - “the habitual juxtaposition of a particular word with another word or words with a frequency greater than chance.”
- Sklearn feature selection methods (4) - youtube
- Univariate and independent features
- Linear models and regularization, doing feature ranking
- Random forests and feature ranking
- Random Search for focus and only then grid search for Random Forest, code
- Stability selection and recursive feature elimination (RFE). are wrapper methods in sklearn for the purpose of feature selection. RFE in sklearn
- Kernel feature selection via conditional covariance minimization (netanel d.)
- Github class that does the following:
- Features with a high percentage of missing values
- Collinear (highly correlated) features
- Features with zero importance in a tree-based model
- Features with low importance
- Features with a single unique value
- Machinelearning mastery on FS:
- Univariate Selection.
- Recursive Feature Elimination.
- Principle Component Analysis.
- Feature Importance.
- Sklearn tutorial on FS:
- Low variance
- Univariate kbest
- RFE
- selectFromModel using _coef _important_features
- Linear models with L1 (svm recommended L2)
- Tree based importance
- A complete overview of many methods
- (reduction) LDA: Linear discriminant analysis is used to find a linear combination of features that characterizes or separates two or more classes (or levels) of a categorical variable.
- (selection) ANOVA: ANOVA stands for Analysis of variance. It is similar to LDA except for the fact that it is operated using one or more categorical independent features and one continuous dependent feature. It provides a statistical test of whether the means of several groups are equal or not.
- (Selection) Chi-Square: It is a is a statistical test applied to the groups of categorical features to evaluate the likelihood of correlation or association between them using their frequency distribution.
- Wrapper methods:
- Forward Selection: Forward selection is an iterative method in which we start with having no feature in the model. In each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
- Backward Elimination: In backward elimination, we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.
- Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset. It repeatedly creates models and keeps aside the best or the worst performing feature at each iteration. It constructs the next model with the left features until all the features are exhausted. It then ranks the features based on the order of their elimination.
- Relief - GIT git2 a new family of feature selection trying to optimize the distance of two samples from the selected one, one which should be closer the other farther.
“The weight updation of attributes works on a simple idea (line 6). That if instance Rᵢ and H have different value (i.e the diff value is large), that means that attribute separates two instance with the same class which is not desirable, thus we reduce the attributes weight. On the other hand, if the instance Rᵢ and M have different value, that means the attribute separates the two instance with different class, which is desirable.”
Feature selection using entropy, information gain, mutual information and … in sklearn.
Entropy, mutual information and KL Divergence by AurelienGeron\
- Vidhya on FE, anomalies, engineering, imputing
- Many types of FE, including log and box cox transform - a very useful explanation.
- Categorical Data
- Dummy variables and feature hashing - hashing is really cool.
- Text data - unigrams, bag of words, N-grams (2,3,..), tfidf matrix, cosine_similarity(tfidf) ontop of a tfidf matrix, unsupervised hierarchical clustering with similarity measures on top of (cosine_similarity), LDA for topic modelling in sklearn - pretty awesome, Kmeans(lda),.
- Deep learning data for FE - Word embedding using keras, continuous BOW - CBOW, SKIPGRAM, word2vec - really good.
- Topic Modelling - a fantastic slide show about topic modelling using LDA etc.
- Dipanjan on feature engineering 1 - cont numeric 2 - categorical 3 - traditional methods
- Target encoding git
- Category encoding git
- Max_features in tf idf -Sometimes it is not effective to transform the whole vocabulary, as the data may have some exceptionally rare words, which, if passed to TfidfVectorizer().fit(), will add unwanted dimensions to inputs in the future. One of the appropriate techniques in this case, for instance, would be to print out word frequences accross documents and then set a certain threshold for them. Imagine you have set a threshold of 50, and your data corpus consists of 100 words. After looking at the word frequences 20 words occur less than 50 times. Thus, you set max_features=80 and you are good to go. If max_features is set to None, then the whole corpus is considered during the TF-IDFtransformation. Otherwise, if you pass, say, 5 to max_features, that would mean creating a feature matrix out of the most 5 frequent words accross text documents.
- Understanding Term based retrieval - TFIDF Bm25
- understanding TFIDF and BM25
- Cosine similarity tutorial
- Cosine vs dot product
- Cosine vs dot product 2
- Fast cosine similarity implementation
- Edit distance similarity
- Diff lib similarity and soundex
- Soft cosine and cosine
- Pearson also used to detect similar vectors
- Mastery on distance formulas
- Role of Distance Measures
- Hamming Distance
- Euclidean Distance
- Manhattan Distance (Taxicab or City Block)
- Minkowski Distance
- Cosine distance = 1 - cosine similarity
- Haversine distance
Note: point 2, about lime is used for explainability, please also check that topic, down below.
- Using RF and other methods, really good
- Non parametric feature impact and importance - while there are nonparametric feature selection algorithms, they typically provide feature rankings, rather than measures of impact or importance.In this paper, we give mathematical definitions of feature impact and importance, derived from partial dependence curves, that operate directly on the data.
- Paper (pdf, blog post): (GITHUB) how to "explain the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally around the prediction."
they want to understand the reasons behind the predictions, it’s a new field that says that many 'feature importance' measures shouldn’t be used. i.e., in a linear regression model, a feature can have an importance rank of 50 (for example), in a comparative model where you duplicate that feature 50 times, each one will have 1/50 importance and won’t be selected for the top K, but it will still be one of the most important features. so new methods needs to be developed to understand feature importance. this one has git code as well.
Several github notebook examples: binary case, multi class, cont and cat features, there are many more for images in the github link.\
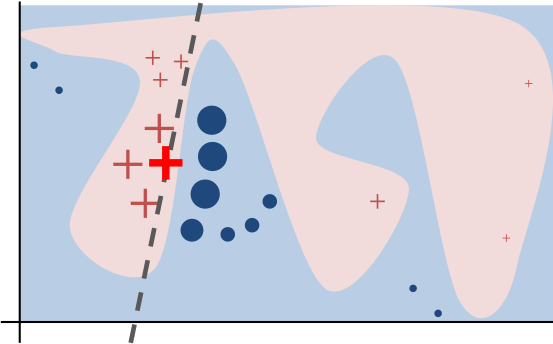
“Intuitively, an explanation is a local linear approximation of the model's behaviour. While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance. While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation. The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear. The bright red cross is the instance being explained (let's call it X). We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size). We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, read our paper, or take a look at this blog post.”
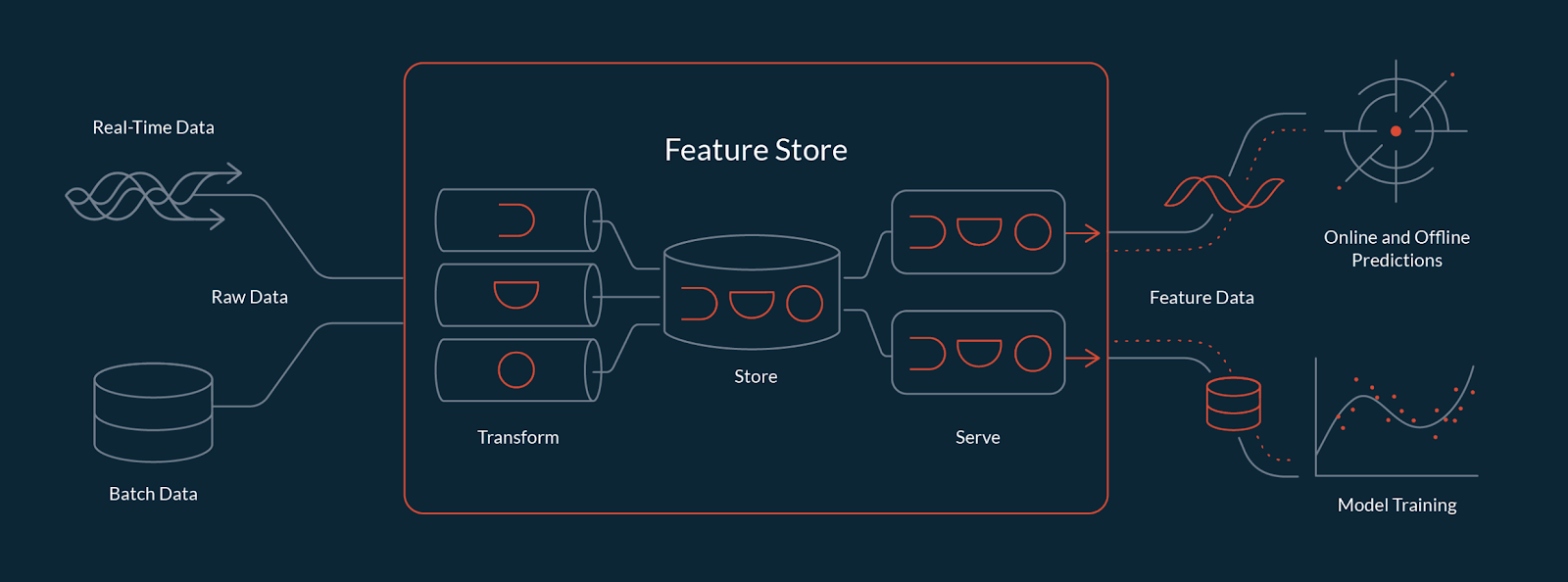
- The importance of having one - medium
- What is?
- Feature store vs data warehouse
- Why feature store is not enough
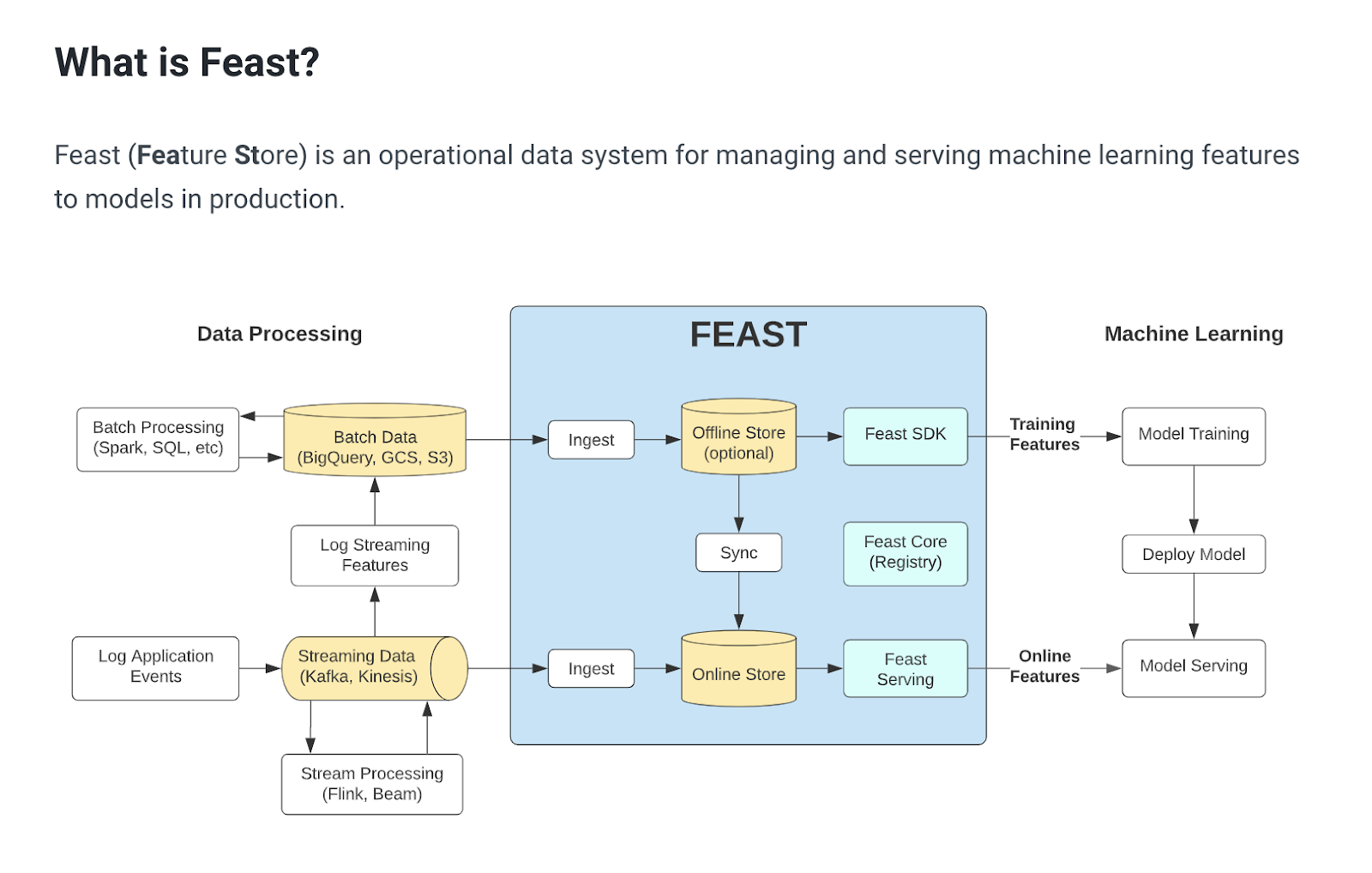
- Feast what is 1 what is 2
- Tecton.ai (managed feature store)
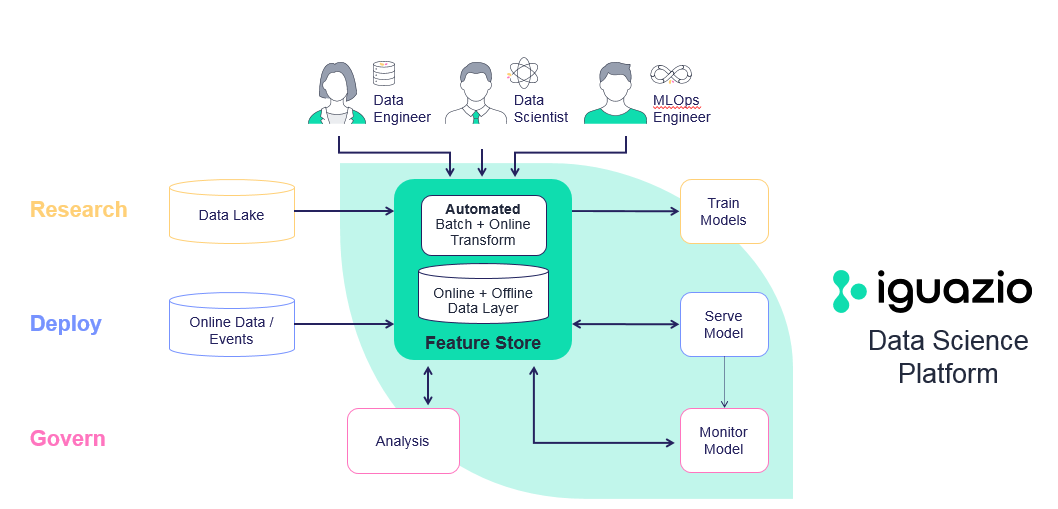
- Iguazio feature store