Thanks You & Reproducing Baselines #1
Comments
|
Hi @ednussi, thanks for expressing interest in our work! |
|
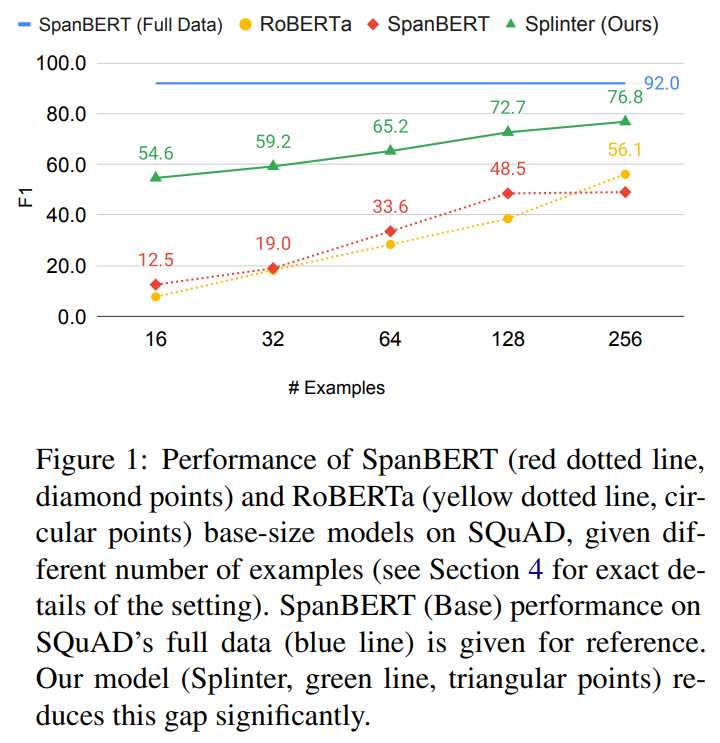
Is there a way to reproduce the RoBERTa & SpanBERT baseline reported and shown in your paper from figure 1 (and figure 4) from the given repo? If so how would I run it? As of now, I've tried to reproduce it by creating a very simplified and standalone code as mentioned above in https://github.com/ednussi/thesis_public , following your paper. My setup is as follow: Model: RoBERTa (Liu et al., 2019) (huggingface implementation) FineTuning Setup: Steps: max(10 epochs, 200 steps) As you can see in my repo, my current setup reaches only about 28 average F1 score over 256 samples (max /min shown in the grayed areas). Could you please help me identify if I incorrectly understood or am missing something in my configuration to reproduce the baseline? For now, I have already noticed my implementation differs from your in some parts (e.g. lr_scheduler assignment with AdamW) and currently trying to match as many code components as possible. |

|
Hi @ednussi , |
|
Thanks, switched to tried preproducing w/ your repo. Currently cloned and tried running: But fails with: Full log preceding fail: |
|
Are you using our finetuning/requirements.txt file? |
|
Good point, recreating a fresh |
|
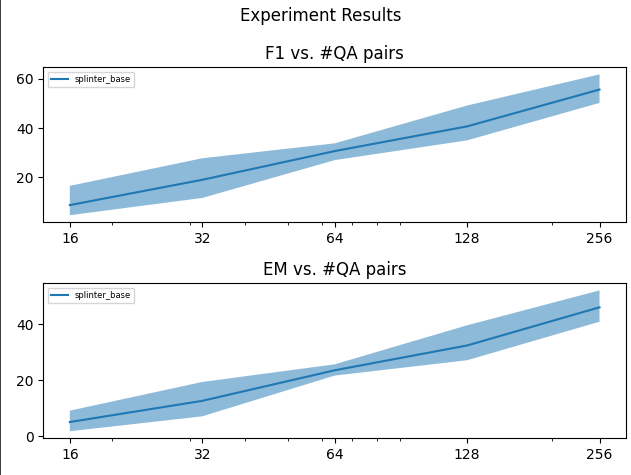
Just quickly reopening to share I was able to reproduce the roberta-base results, running on a single rtx2080 by running this shell script: Thanks for all the help! |
|
Lastly, since you have not provided a license, I wanted to kindly inquire if I may use the code in my research. |
|
Happy to see you managed to reproduce our results! |
Thank you very much for posting this code!
It is extremely helpful in reproducing the results.
I wanted to inquire if you can share details about reproducing the baselines provided in the paper, as we've been having some troubles with reproducing those numbers, specifically over the roberta-base vanilla experiment.
See here for more details.
Thanks!
The text was updated successfully, but these errors were encountered: