
![]()

The Interactive Corpus Analysis Tool (ICAT) is an interactive machine learning (IML) dashboard for unlabeled text datasets that allows a user to iteratively and visually define features, explore and label instances of their dataset, and train a logistic regression model on the fly as they do so to assist in filtering, searching, and labeling tasks.
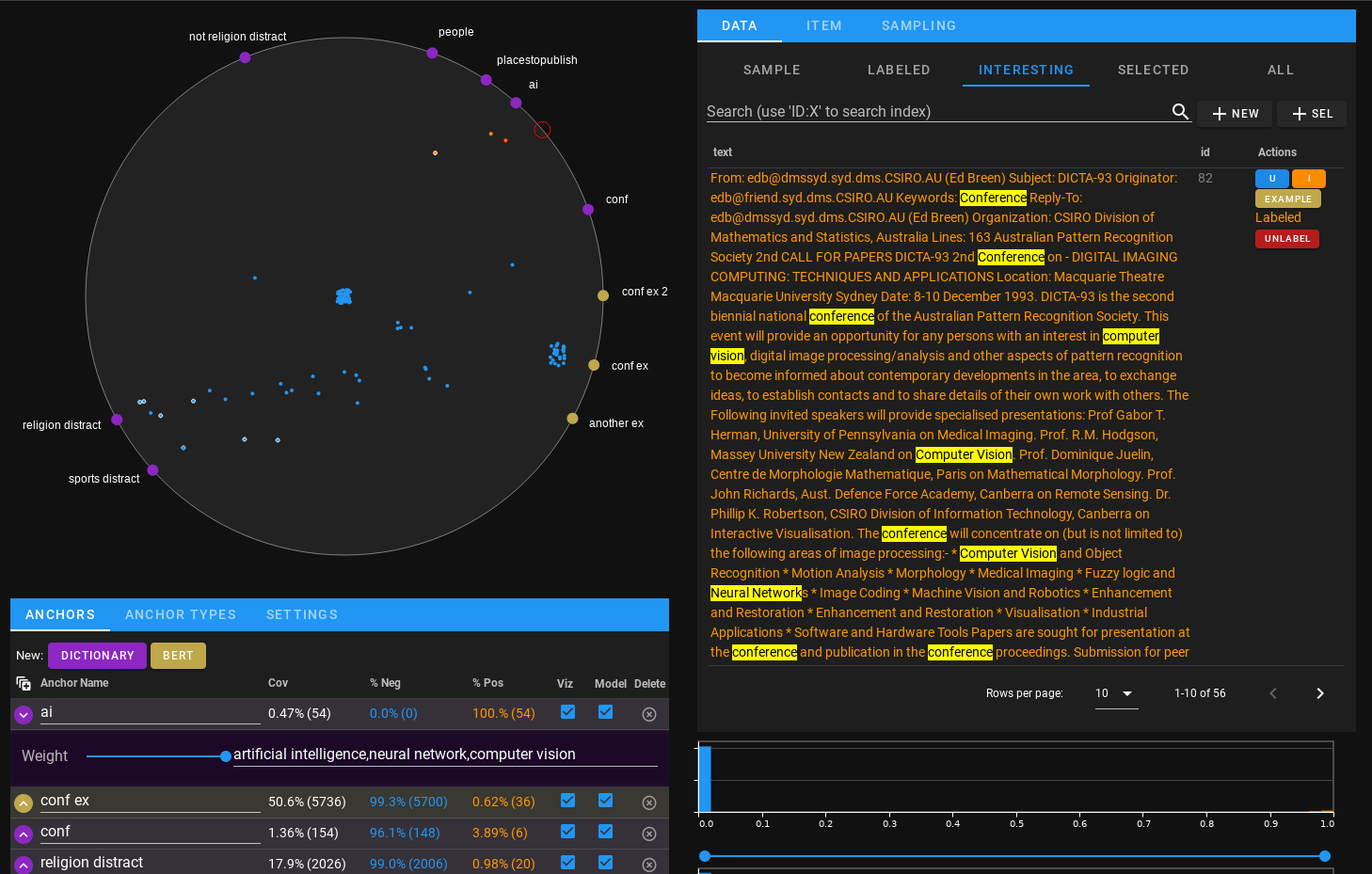
ICAT is implemented using holoviz's panel library, so it can either directly be rendered like a widget in a jupyter lab/notebook instance, or incorporated as part of a standalone panel website.
ICAT can be installed via pip with:
pip install icat-iml
The user guide and API documentation can be found at https://ornl.github.io/icat.
The primary ring visualization is called AnchorViz, a technique from IML literature. (See Chen, Nan-Chen, et al. "AnchorViz: Facilitating classifier error discovery through interactive semantic data exploration")
We implemented an ipywidget version of AnchorViz and use it in this project, it can be found separately at https://github.com/ORNL/ipyanchorviz
To cite usage of ICAT, please use the following bibtex:
@misc{doecode_105653,
title = {Interactive Corpus Analysis Tool},
author = {Martindale, Nathan and Stewart, Scott},
abstractNote = {The Interactive Corpus Analysis Tool (ICAT) is an interactive machine learning dashboard for unlabeled text/natural language processing datasets that allows a user to iteratively and visually define features, explore and label instances of their dataset, and simultaneously train a logistic regression model. ICAT was created to allow subject matter experts in a specific domain to directly train their own models for unlabeled datasets visually, without needing to be a machine learning expert or needing to know how to code the models themselves. This approach allows users to directly leverage the power of machine learning, but critically, also involves the user in the development of the machine learning model.},
year = {2023},
month = {apr}
}