[UTS namespace](#UTS namespace)
[IPC(Interprocess Communication)namespace](#IPC(Interprocess Communication)namespace)
[PID namespace](#PID namespace)
[Mount namespaces](#Mount namespaces)
[Network namespace](#Network namespace)
[User namespaces](#User namespaces)
代码来自4.1.19版本。
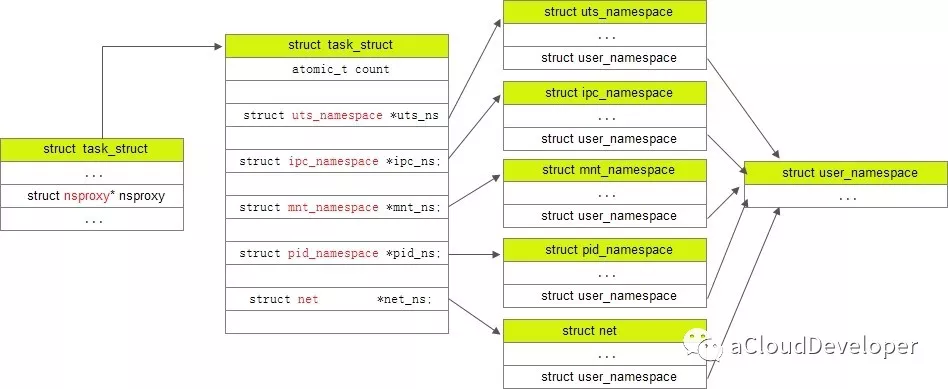
先找到namespace在task_struct中的结构,
// include/linux/sched.h
struct task_struct {
......
/* namespaces */
struct nsproxy *nsproxy;
......
}以及nsproxy的定义,
// include/linux/nsproxy.h
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct cgroup_namespace *cgroup_ns;
};
extern struct nsproxy init_nsproxy;其中 user namespace 是和其他 namespace 耦合在一起的,所以没出现在上述结构中。
task_struct,nsproxy,几种 namespace 之间的关系如下所示(这里的nsproxy应该是写错了,写成task_struct了):
同时,nsproxy.h 中还定义了一些对 namespace 的操作,包括 copy_namespaces 等,
int copy_namespaces(unsigned long flags, struct task_struct *tsk);
void exit_task_namespaces(struct task_struct *tsk);
void switch_task_namespaces(struct task_struct *tsk, struct nsproxy *new);
void free_nsproxy(struct nsproxy *ns);
int unshare_nsproxy_namespaces(unsigned long, struct nsproxy **,
struct fs_struct *);
int __init nsproxy_cache_init(void);nsproxy 有个 init_nsproxy 函数,init_nsproxy 在 task 初始化的时候会被初始化,
// include/linux/init_task.h
/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x1fffff (=2MB)
*/
#define INIT_TASK(tsk) \
{
......
.nsproxy = &init_nsproxy,
......
}// kernel/nsproxy.c
struct nsproxy init_nsproxy = {
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
#if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC)
.ipc_ns = &init_ipc_ns,
#endif
.mnt_ns = NULL,
.pid_ns_for_children = &init_pid_ns,
#ifdef CONFIG_NET
.net_ns = &init_net,
#endif
#ifdef CONFIG_CGROUPS
.cgroup_ns = &init_cgroup_ns,
#endif
};init_nsproxy 中,对 uts, ipc, pid, net 都进行了初始化,但 mount 却没有。
看看 do_fork() 函数是如何处理一个新进程的 namespace 的:
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
// 创建进程描述符指针
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
// 复制进程描述符,返回值是 task_struct
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
// 得到新进程描述符的 pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 调用 vfork() 方法,完成相关的初始化工作
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将新进程加入到调度器中,为其分配 CPU,准备执行
wake_up_new_task(p);
// fork() 完成,子进程开始运行,并让 ptrace 跟踪
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
// 如果是 vfork(),将父进程加入等待队列,等待子进程完成
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}和 namespace 相关的内容在 copy_process() 中,这个函数将父进程信息复制给子进程,
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
// 创建进程描述符指针
struct task_struct *p;
......
// !!! 复制 namespace
retval = copy_namespaces(clone_flags, p);
......
}
// ......
// 返回新进程 p
return p;
}再看 copy_namespaces(),核心函数是 create_new_namespaces(),
/*
* called from clone. This now handles copy for nsproxy and all
* namespaces therein.
*/
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
// 老的 namespace 信息是从父进程中复制过来的
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
// 在5.17.11中,此处还会另外检查两个flag:CLONE_NEWCGROUP、CLONE_NEWTIME
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))) {
get_nsproxy(old_ns);
return 0;
}
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
/*
* CLONE_NEWIPC must detach from the undolist: after switching
* to a new ipc namespace, the semaphore arrays from the old
* namespace are unreachable. In clone parlance, CLONE_SYSVSEM
* means share undolist with parent, so we must forbid using
* it along with CLONE_NEWIPC.
*/
if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) ==
(CLONE_NEWIPC | CLONE_SYSVSEM))
return -EINVAL;
// 新的 namespace 信息根据 flag 做调整
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
if (IS_ERR(new_ns))
return PTR_ERR(new_ns);
tsk->nsproxy = new_ns;
return 0;
}看 create_new_namespaces(),先给 nsproxy 结构申请了新内存,然后依次复制5个 namespace 的信息,
/*
* Create new nsproxy and all of its the associated namespaces.
* Return the newly created nsproxy. Do not attach this to the task,
* leave it to the caller to do proper locking and attach it to task.
*/
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
int err;
// 创建新的 nsproxy
new_nsp = create_nsproxy();
if (!new_nsp)
return ERR_PTR(-ENOMEM);
//创建 mnt namespace
new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
if (IS_ERR(new_nsp->mnt_ns)) {
err = PTR_ERR(new_nsp->mnt_ns);
goto out_ns;
}
//创建 uts namespace
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
if (IS_ERR(new_nsp->uts_ns)) {
err = PTR_ERR(new_nsp->uts_ns);
goto out_uts;
}
//创建 ipc namespace
new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
if (IS_ERR(new_nsp->ipc_ns)) {
err = PTR_ERR(new_nsp->ipc_ns);
goto out_ipc;
}
//创建 pid namespace
new_nsp->pid_ns_for_children =
copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns_for_children);
if (IS_ERR(new_nsp->pid_ns_for_children)) {
err = PTR_ERR(new_nsp->pid_ns_for_children);
goto out_pid;
}
//创建 network namespace
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
if (IS_ERR(new_nsp->net_ns)) {
err = PTR_ERR(new_nsp->net_ns);
goto out_net;
}
return new_nsp;
// 错误处理
out_net:
if (new_nsp->pid_ns_for_children)
put_pid_ns(new_nsp->pid_ns_for_children);
out_pid:
if (new_nsp->ipc_ns)
put_ipc_ns(new_nsp->ipc_ns);
out_ipc:
if (new_nsp->uts_ns)
put_uts_ns(new_nsp->uts_ns);
out_uts:
if (new_nsp->mnt_ns)
put_mnt_ns(new_nsp->mnt_ns);
out_ns:
kmem_cache_free(nsproxy_cachep, new_nsp);
return ERR_PTR(err);
}看 create_nsproxy(),
static inline struct nsproxy *create_nsproxy(void)
{
struct nsproxy *nsproxy;
nsproxy = kmem_cache_alloc(nsproxy_cachep, GFP_KERNEL); // 从缓存中分配内存
if (nsproxy)
atomic_set(&nsproxy->count, 1); // 如果没问题就计数+1
return nsproxy; // 返回这个新的指针
}在 create_nsproxy() 之后,就是依次复制各个 namespace 的信息了,这些代码放到下面各个 namespace 中分析。每个 copy_xxx 的函数都有两个实现,其中一个需要开启对应的编译选项,不开启的话只会默认复制父进程的信息,且使用对应的 flag 会报错。
UTS命名空间主要用于隔离系统中的主机名和域名等系统标识信息。
复制 uts_namespace 的函数 copy_utsname() 比较简单,
struct uts_namespace *copy_utsname(unsigned long flags,
struct user_namespace *user_ns, struct uts_namespace *old_ns)
{
struct uts_namespace *new_ns;
BUG_ON(!old_ns); // 使用BUG_ON()宏检查旧的UTS命名空间是否为空指针,并增加引用计数以确保该UTS命名空间不会在函数执行期间被删除
get_uts_ns(old_ns);
if (!(flags & CLONE_NEWUTS)) // 检查是否带有 CLONE_NEWUTS 标志,若无,则返回老的 ns
return old_ns;
new_ns = clone_uts_ns(user_ns, old_ns); // user_ns 和 old_ns 的关系还没弄明白
put_uts_ns(old_ns);
return new_ns;
}flags用于确定是否需要为新的UTS命名空间创建一个新的用户命名空间;如果flags参数中不包含CLONE_NEWUTS标志,则表示新的UTS命名空间将与当前进程的UTS命名空间相同。
函数的输入参数user_ns表示新的UTS命名空间所属的用户命名空间。
函数的输入参数old_ns表示需要复制的旧的UTS命名空间。该参数不能为空指针。
看 struct uts_namespace 的结构:
struct uts_namespace {
struct kref kref; // 用于对UTS命名空间进行引用计数的结构,这个结构里面只有一个变量:atomic_t refcount
struct new_utsname name; // 包含了UTS命名空间的主机名和域名等信息
struct user_namespace *user_ns; // 对该UTS命名空间进行引用的用户命名空间数量
struct ns_common ns; // 该UTS命名空间所属的用户命名空间
};
struct new_utsname {
char sysname[__NEW_UTS_LEN + 1];
char nodename[__NEW_UTS_LEN + 1]; // host name
char release[__NEW_UTS_LEN + 1];
char version[__NEW_UTS_LEN + 1];
char machine[__NEW_UTS_LEN + 1];
char domainname[__NEW_UTS_LEN + 1]; // domain name
};再看看在 sethostname 函数里 UTS namespace 是怎么被处理的。这个函数在 Linux man page 中是这么描述的:sethostname() sets the hostname to the value given in the character array name. The len argument specifies the number of bytes in name. (Thus, name does not require a terminating null byte.),
SYSCALL_DEFINE2(sethostname, char __user *, name, int, len)
{
int errno;
char tmp[__NEW_UTS_LEN];
// 检查当前进程是否具有足够权限修改 hostname
if (!ns_capable(current->nsproxy->uts_ns->user_ns, CAP_SYS_ADMIN))
return -EPERM;
// 检查传进来的长度参数 len 是否合法
if (len < 0 || len > __NEW_UTS_LEN)
return -EINVAL;
down_write(&uts_sem); // uts_sem是信号量
errno = -EFAULT;
if (!copy_from_user(tmp, name, len)) { // 把 name 从用户空间复制到内核空间
struct new_utsname *u = utsname(); // utsname() 返回 ¤t->nsproxy->uts_ns->name
memcpy(u->nodename, tmp, len); // 把需要设置的 hostname 复制到 current->nsproxy->uts_ns->name->nodename
memset(u->nodename + len, 0, sizeof(u->nodename) - len); // 末尾置0作为结束
errno = 0;
uts_proc_notify(UTS_PROC_HOSTNAME);
}
up_write(&uts_sem); // 释放写锁定
return errno;
}由 current 找到关联的 nsproxy,然后找到 uts_ns,然后直接改 hostname 就行了,大部分进程关联的都是根 uts_ns,在容器内的进程关联的是子 uts_ns。
在 gethostname 函数中,流程也差不多,先锁住信号量,然后用 utsname() 函数获取 current->nsproxy->uts_ns->name->nodename,然后复制到用户空间,
SYSCALL_DEFINE2(gethostname, char __user *, name, int, len)
{
int i, errno;
struct new_utsname *u;
if (len < 0)
return -EINVAL;
down_read(&uts_sem);
u = utsname();
i = 1 + strlen(u->nodename);
if (i > len)
i = len;
errno = 0;
if (copy_to_user(name, u->nodename, i))
errno = -EFAULT;
up_read(&uts_sem);
return errno;
}在 create_new_namespaces() 函数的流程中,再看复制 ipc_namespace 的 copy_ipcs 函数:若编译参数 CONFIG_IPC_NS 未被定义过,则 clone 时遇到 CLONE_NEWIPC 参数直接报错;若编译参数 CONFIG_IPC_NS 被定义过,且检查到 CLONE_NEWIPC 参数,则会调用 create_ipc_ns 函数来创建一个新的 namespace,
// include/linux/ipc_namespace.h
#if defined(CONFIG_IPC_NS)
extern struct ipc_namespace *copy_ipcs(unsigned long flags,
struct user_namespace *user_ns, struct ipc_namespace *ns);
......
#else
// #if defined(CONFIG_IPC_NS) 条件不满足则在执行这个函数时直接返回父进程相应的 namespace
static inline struct ipc_namespace *copy_ipcs(unsigned long flags,
struct user_namespace *user_ns, struct ipc_namespace *ns)
{
if (flags & CLONE_NEWIPC)
return ERR_PTR(-EINVAL);
return ns;
}
......
#endif
// ipc/namespace.c
// 若 #if defined(CONFIG_IPC_NS) 条件满足则允许创建新的 namespace,也即调用 create_ipc_ns 函数
struct ipc_namespace *copy_ipcs(unsigned long flags,
struct user_namespace *user_ns, struct ipc_namespace *ns)
{
if (!(flags & CLONE_NEWIPC))
return get_ipc_ns(ns); // 引用数+1并返回现有的指针 ns
return create_ipc_ns(user_ns, ns);
}看这里创建新 namespace 的核心函数 create_ipc_ns,
static struct ipc_namespace *create_ipc_ns(struct user_namespace *user_ns,
struct ipc_namespace *old_ns)
{
struct ipc_namespace *ns;
int err;
ns = kmalloc(sizeof(struct ipc_namespace), GFP_KERNEL); // 分配内存
if (ns == NULL)
return ERR_PTR(-ENOMEM);
err = ns_alloc_inum(&ns->ns);
if (err) {
kfree(ns);
return ERR_PTR(err);
}
ns->ns.ops = &ipcns_operations;
atomic_set(&ns->count, 1); // 设置计数值
err = mq_init_ns(ns); // 初始化消息队列 mq 对应的一些参数
if (err) {
ns_free_inum(&ns->ns);
kfree(ns);
return ERR_PTR(err);
}
atomic_inc(&nr_ipc_ns);
sem_init_ns(ns); // 初始化信号量 sem 对应的 idr 池和一些参数
msg_init_ns(ns); // 初始化消息 msg 对应的 idr 池和一些参数
shm_init_ns(ns); // 初始化共享内存 shm 对应的 idr 池和一些参数
ns->user_ns = get_user_ns(user_ns);
return ns;
}ipc_namespace:
struct ipc_namespace {
atomic_t count;
struct ipc_ids ids[3];
int sem_ctls[4];
int used_sems;
unsigned int msg_ctlmax;
unsigned int msg_ctlmnb;
unsigned int msg_ctlmni;
atomic_t msg_bytes;
atomic_t msg_hdrs;
size_t shm_ctlmax;
size_t shm_ctlall;
unsigned long shm_tot;
int shm_ctlmni;
/*
* Defines whether IPC_RMID is forced for _all_ shm segments regardless
* of shmctl()
*/
int shm_rmid_forced;
struct notifier_block ipcns_nb;
/* The kern_mount of the mqueuefs sb. We take a ref on it */
struct vfsmount *mq_mnt;
/* # queues in this ns, protected by mq_lock */
unsigned int mq_queues_count;
/* next fields are set through sysctl */
unsigned int mq_queues_max; /* initialized to DFLT_QUEUESMAX */
unsigned int mq_msg_max; /* initialized to DFLT_MSGMAX */
unsigned int mq_msgsize_max; /* initialized to DFLT_MSGSIZEMAX */
unsigned int mq_msg_default;
unsigned int mq_msgsize_default;
/* user_ns which owns the ipc ns */
struct user_namespace *user_ns;
struct ns_common ns;
};// v2.6.17-rc4, ipc/msg.c
// 在没有 namespace 的版本中,内核定义了三个全局的 ipc_ids 结构实例,分别代表信号量、消息队列和共享内存,其中用于消息队列的是 msg_ids
static struct ipc_ids msg_ids;
// v4.1.19, ipc/msg.c
// 这个宏定义了给定 ns 中属于消息队列的 ipc_ids 结构,这意味着不同的 IPC 命名空间不能访问彼此的 ipc_ids 成员
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])// 每一个 struct ipc_ids 结构描述了一类 IPC 资源,用这个结构就可以找到具体的消息队列结构
struct ipc_ids {
int in_use;
unsigned short seq;
struct rw_semaphore rwsem;
struct idr ipcs_idr;
int next_id;
};要理清楚 IPC 全部的逻辑还需要大量的代码,就不放在这里了。看看有没有时间新写一个专门学习 IPC 的文档吧。
| Module | Syscall | Descript |
|---|---|---|
| sem | semget() | 创建信号量 |
| - | semctl() | 初始化信号量 |
| - | semop() | 信号量的PV操作 |
| msg | msgget() | 创建消息队列 |
| - | msgctl() | 获取和设置消息队列的属性 |
| - | msgsnd() | 将消息写入到消息队列 |
| - | msgrcv() | 从消息队列读取消息 |
| shm | shmget() | 创建共享内存对象 |
| - | shmctl() | 共享内存管理 |
| - | shmat() | 把共享内存区对象映射到调用进程的地址空间 |
| - | shmdt() | 断开共享内存连接 |
SYSCALL_DEFINE2(msgget, key_t, key, int, msgflg)
{
struct ipc_namespace *ns;
// 参数初始化
// msg_ops 是一个操作集合,根据 msgflg 确定该执行集合中的哪个函数
static const struct ipc_ops msg_ops = {
.getnew = newque,
.associate = msg_security,
};
struct ipc_params msg_params;
ns = current->nsproxy->ipc_ns; // ns 是创建该消息队列的进程的 IPC namespace
msg_params.key = key;
msg_params.flg = msgflg;
// 调用 ipcget,由 IPC 模块统一处理
return ipcget(ns, &msg_ids(ns), &msg_ops, &msg_params);
}int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params); // 建立私有消息队列,自发自收
else
return ipcget_public(ns, ids, ops, params); // 主要看这个函数
}static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
/*
* Take the lock as a writer since we are potentially going to add
* a new entry + read locks are not "upgradable"
*/
down_write(&ids->rwsem);
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
/* key not used */
if (!(flg & IPC_CREAT)) // key 没找到但又不需要创建,就报错
err = -ENOENT;
else
err = ops->getnew(ns, params); // key 没找到且需要创建
} else {
/* ipc object has been locked by ipc_findkey() */
if (flg & IPC_CREAT && flg & IPC_EXCL)
err = -EEXIST; // key 指定的消息队列已存在,而 msgflg 中同时指定了 IPC_CREAT 和 IPC_EXCL 标志,会报错
else {
err = 0;
if (ops->more_checks)
err = ops->more_checks(ipcp, params);
if (!err)
/*
* ipc_check_perms returns the IPC id on
* success
*/
err = ipc_check_perms(ns, ipcp, ops, params);
}
ipc_unlock(ipcp);
}
up_write(&ids->rwsem);
return err;
}接着看 ops->getnew(ns, params) 这一步,这里的 getnew 函数被设置为 newque 函数,
/**
* newque - Create a new msg queue
* @ns: namespace
* @params: ptr to the structure that contains the key and msgflg
*
* Called with msg_ids.rwsem held (writer)
*/
static int newque(struct ipc_namespace *ns, struct ipc_params *params)
{
struct msg_queue *msq;
int id, retval;
key_t key = params->key;
int msgflg = params->flg;
msq = ipc_rcu_alloc(sizeof(*msq));
if (!msq)
return -ENOMEM;
msq->q_perm.mode = msgflg & S_IRWXUGO;
msq->q_perm.key = key;
msq->q_perm.security = NULL;
retval = security_msg_queue_alloc(msq);
if (retval) {
ipc_rcu_putref(msq, ipc_rcu_free);
return retval;
}
msq->q_stime = msq->q_rtime = 0;
msq->q_ctime = get_seconds();
msq->q_cbytes = msq->q_qnum = 0;
msq->q_qbytes = ns->msg_ctlmnb;
msq->q_lspid = msq->q_lrpid = 0;
INIT_LIST_HEAD(&msq->q_messages);
INIT_LIST_HEAD(&msq->q_receivers);
INIT_LIST_HEAD(&msq->q_senders);
/* ipc_addid() locks msq upon success. */
id = ipc_addid(&msg_ids(ns), &msq->q_perm, ns->msg_ctlmni); // 分配一个标识号;这里用到了 ipc namespace
if (id < 0) {
ipc_rcu_putref(msq, msg_rcu_free);
return id;
}
ipc_unlock_object(&msq->q_perm);
rcu_read_unlock();
return msq->q_perm.id;
}/**
* ipc_addid - add an ipc identifier
* @ids: ipc identifier set
* @new: new ipc permission set
* @size: limit for the number of used ids
*
* Add an entry 'new' to the ipc ids idr. The permissions object is
* initialised and the first free entry is set up and the id assigned
* is returned. The 'new' entry is returned in a locked state on success.
* On failure the entry is not locked and a negative err-code is returned.
*
* Called with writer ipc_ids.rwsem held.
*/
int ipc_addid(struct ipc_ids *ids, struct kern_ipc_perm *new, int size)
{
kuid_t euid;
kgid_t egid;
int id;
int next_id = ids->next_id;
if (size > IPCMNI)
size = IPCMNI;
if (ids->in_use >= size)
return -ENOSPC;
idr_preload(GFP_KERNEL);
spin_lock_init(&new->lock);
new->deleted = false;
rcu_read_lock();
spin_lock(&new->lock);
current_euid_egid(&euid, &egid);
new->cuid = new->uid = euid;
new->gid = new->cgid = egid;
id = idr_alloc(&ids->ipcs_idr, new,
(next_id < 0) ? 0 : ipcid_to_idx(next_id), 0,
GFP_NOWAIT);
idr_preload_end();
if (id < 0) {
spin_unlock(&new->lock);
rcu_read_unlock();
return id;
}
ids->in_use++;
if (next_id < 0) {
new->seq = ids->seq++;
if (ids->seq > IPCID_SEQ_MAX)
ids->seq = 0;
} else {
new->seq = ipcid_to_seqx(next_id);
ids->next_id = -1;
}
new->id = ipc_buildid(id, new->seq);
return id;
}ipc_addid函数的作用:在&msg_ids(ns)管理的idr树中找到一个空闲节点,将&msq->perm存入这个节点中,同时返回这个节点的序号,也就是这个函数的返回值给id,最后这个函数返回的msq->q_perm.id也就是节点的序号,最后msgget返回的句柄也就是这个id号,程序可以用这个id号进行发送消息。
这里其实并没有全都看懂,但关于 namespace 的主要思想就是把原有的全局变量 msg_ids 变成了各个 namespace 实例中的成员 (ns)->ids[IPC_MSG_IDS]。进程在做通信时内核会用 current 中的 ipc namespace 去替换 (ns)->ids[IPC_MSG_IDS],也就是说,当前进程能找到的全部进程间通信的消息只会是归属于同一个 ipc namespace 的进程发出的。
再看复制 pid_namespace 的 copy_pid_ns 函数,
struct pid_namespace *copy_pid_ns(unsigned long flags,
struct user_namespace *user_ns, struct pid_namespace *old_ns)
{
if (!(flags & CLONE_NEWPID)) // 检查 flag
return get_pid_ns(old_ns);
if (task_active_pid_ns(current) != old_ns) // 检查当前的 pid_namespace 和 old_ns 是否一致?
return ERR_PTR(-EINVAL);
return create_pid_namespace(user_ns, old_ns); // 创建新的 pid_namespace
}看 create_pid_namespace 函数,基本就是新建一个 struct pid_namespace 变量,然后设置它的各变量并返回的过程,
static struct pid_namespace *create_pid_namespace(struct user_namespace *user_ns,
struct pid_namespace *parent_pid_ns)
{
struct pid_namespace *ns;
unsigned int level = parent_pid_ns->level + 1; // pid namespace 的套娃层数+1?
int i;
int err;
// MAX_PID_NS_LEVEL 定义为32,说明 pid namespace 的套娃不能超过32层?
if (level > MAX_PID_NS_LEVEL) {
err = -EINVAL;
goto out;
}
err = -ENOMEM;
ns = kmem_cache_zalloc(pid_ns_cachep, GFP_KERNEL); // 申请内存?
if (ns == NULL)
goto out;
ns->pidmap[0].page = kzalloc(PAGE_SIZE, GFP_KERNEL);
if (!ns->pidmap[0].page)
goto out_free;
ns->pid_cachep = create_pid_cachep(level + 1);
if (ns->pid_cachep == NULL)
goto out_free_map;
err = ns_alloc_inum(&ns->ns);
if (err)
goto out_free_map;
ns->ns.ops = &pidns_operations;
kref_init(&ns->kref);
ns->level = level;
ns->parent = get_pid_ns(parent_pid_ns);
ns->user_ns = get_user_ns(user_ns);
ns->nr_hashed = PIDNS_HASH_ADDING;
INIT_WORK(&ns->proc_work, proc_cleanup_work);
set_bit(0, ns->pidmap[0].page);
atomic_set(&ns->pidmap[0].nr_free, BITS_PER_PAGE - 1);
for (i = 1; i < PIDMAP_ENTRIES; i++)
atomic_set(&ns->pidmap[i].nr_free, BITS_PER_PAGE);
return ns;
out_free_map:
kfree(ns->pidmap[0].page);
out_free:
kmem_cache_free(pid_ns_cachep, ns);
out:
return ERR_PTR(err);
}struct pid_namespace 的结构:
struct pid_namespace {
struct kref kref; // 引用计数
struct pidmap pidmap[PIDMAP_ENTRIES]; // pid 分配的 bitmap,为1表示已分配
struct rcu_head rcu;
int last_pid; // 记录上次分配的 pid,默认当前分配的 pid=last_pid+1
unsigned int nr_hashed;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep; // 用于分配 pid 结构的 slab 缓存
unsigned int level; // 记录该 pidns 的深度
struct pid_namespace *parent; // 父 pidns
#ifdef CONFIG_PROC_FS
struct vfsmount *proc_mnt;
struct dentry *proc_self;
struct dentry *proc_thread_self;
#endif
#ifdef CONFIG_BSD_PROCESS_ACCT
struct fs_pin *bacct;
#endif
struct user_namespace *user_ns;
struct work_struct proc_work;
kgid_t pid_gid;
int hide_pid;
int reboot; /* group exit code if this pidns was rebooted */
struct ns_common ns;
};理解 pid 还需要再了解其他几个重要结构。
一个进程对应一个 task struct,但是这个进程在多个 pidns 中可以看到不同的 pid,对于这些 pid 的管理,主要通过两个结构体来实现。
struct upid { // 这个结构记录了某个进程在某个深度下的 pid 值和对应的 pid_namespace 结构
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr; // pid 的数值
struct pid_namespace *ns; // 所在命名空间
struct hlist_node pid_chain; // 链表节点
};
struct pid // 这个结构和进程在绝大多数情况下一一对应
{
atomic_t count;
unsigned int level; // 这个 pid 结构体的深度
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; // 使用这个 pid 的进程链表
struct rcu_head rcu;
struct upid numbers[1]; // 这个 pid 在不同命名空间中的表示;这里数组大小虽然为1,但其实可以在申请内存时调整
};看一下在 getpid 函数中,进程获取 pid 时是怎么处理 pid namespace 的:
SYSCALL_DEFINE0(getpid)
{
return task_tgid_vnr(current);
}static inline pid_t task_tgid_vnr(struct task_struct *tsk)
{
// 这里 task_tgid(tsk) 函数就是获得当前进程的 group leader(进程的 task_group 就是它自己,线程的 task_group 是它的父进程,调用 pthread_create 的那个进程)的 pid 结构
// 但这里为啥是请求 group leader 的 pid 呢?
return pid_vnr(task_tgid(tsk));
}pid_t pid_vnr(struct pid *pid)
{
return pid_nr_ns(pid, task_active_pid_ns(current));
}pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
{
struct upid *upid;
pid_t nr = 0;
if (pid && ns->level <= pid->level) {
upid = &pid->numbers[ns->level]; // 取出当前 pid 在特定深度下的 upid
if (upid->ns == ns) // 如果 upid 对应的 ns 和传入的 ns(current 的 ns)一致,就返回 nr(也即该深度下的 pid 值);但什么时候这个条件会不成立呢?
nr = upid->nr;
}
return nr;
}/*
参数:
unsigned long flags: 标记位,指示如何创建新的mnt namespace。
struct mnt_namespace *ns: 要复制的mnt namespace。
struct user_namespace *user_ns: 指向新mnt namespace所属的user namespace。
struct fs_struct *new_fs: 指向将新mnt namespace的根和当前工作目录移动到不同vfsmount的进程的fs_struct。
*/
struct mnt_namespace *copy_mnt_ns(unsigned long flags, struct mnt_namespace *ns,
struct user_namespace *user_ns, struct fs_struct *new_fs)
{
struct mnt_namespace *new_ns;
struct vfsmount *rootmnt = NULL, *pwdmnt = NULL;
struct mount *p, *q;
struct mount *old;
struct mount *new;
int copy_flags;
BUG_ON(!ns); // 检查ns指针是否非空,如果不是则触发BUG(错误检测)
if (likely(!(flags & CLONE_NEWNS))) {
get_mnt_ns(ns);
return ns;
}
old = ns->root;
new_ns = alloc_mnt_ns(user_ns); // 为新的 mnt namespace 分配内存空间,并在创建失败时返回错误指针
if (IS_ERR(new_ns))
return new_ns;
namespace_lock(); // 锁定mnt namespace链表
/* 第一遍扫描:拷贝整个 mnt namespace 树的拓扑结构 */
copy_flags = CL_COPY_UNBINDABLE | CL_EXPIRE;
if (user_ns != ns->user_ns)
copy_flags |= CL_SHARED_TO_SLAVE | CL_UNPRIVILEGED;
new = copy_tree(old, old->mnt.mnt_root, copy_flags); // copy_tree函数复制原始mnt namespace的根vfsmount,其中copy_flags参数指定了在复制期间要执行的操作
if (IS_ERR(new)) {
namespace_unlock();
free_mnt_ns(new_ns);
return ERR_CAST(new);
}
new_ns->root = new;
list_add_tail(&new_ns->list, &new->mnt_list);
/*
* Second pass: switch the tsk->fs->* elements and mark new vfsmounts
* as belonging to new namespace. We have already acquired a private
* fs_struct, so tsk->fs->lock is not needed.
*/
// 深度复制挂载树,把原namespace的挂载内容复制到新的namespace中?
p = old;
q = new;
while (p) {
q->mnt_ns = new_ns;
if (new_fs) {
if (&p->mnt == new_fs->root.mnt) {
new_fs->root.mnt = mntget(&q->mnt);
rootmnt = &p->mnt;
}
if (&p->mnt == new_fs->pwd.mnt) {
new_fs->pwd.mnt = mntget(&q->mnt);
pwdmnt = &p->mnt;
}
}
p = next_mnt(p, old);
q = next_mnt(q, new);
if (!q)
break;
while (p->mnt.mnt_root != q->mnt.mnt_root)
p = next_mnt(p, old);
}
namespace_unlock();
if (rootmnt)
mntput(rootmnt);
if (pwdmnt)
mntput(pwdmnt);
return new_ns; // 返回新的 mnt namespace
}struct mnt_namespace {
atomic_t count; // 用于引用计数,表示当前结构体被引用的次数,当计数为0时,结构体可以被释放
struct ns_common ns; // 用于实现命名空间的公共成员,包括命名空间类型和指向命名空间的引用计数
struct mount * root; // 当前namespace下的根文件系统
struct list_head list; // //当前namespace下的文件系统链表(vfsmount list)
struct user_namespace *user_ns; // 指向该命名空间关联的用户命名空间,以限制命名空间中的权限
u64 seq; // 用于防止死循环的序列号,防止在命名空间的重复引用中发生死循环
wait_queue_head_t poll; // 一个等待队列头,用于将等待挂载事件的进程链接在一起,以便挂载事件完成后通知它们
u64 event; // 一个表示挂载事件类型的标志,用于在多个进程之间共享挂载事件
};// 安装的文件系统描述符
struct vfsmount {
struct list_head mnt_hash;
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct dentry *mnt_mountpoint; /* dentry of mountpoint,挂载点目录 */
struct dentry *mnt_root; /* root of the mounted tree,文件系统根目录 */
struct super_block *mnt_sb; /* pointer to superblock */
struct list_head mnt_mounts; /* list of children, anchored here,子文件系统链表 */
struct list_head mnt_child; /* and going through their mnt_child,构成mnt_mounts list*/
int mnt_flags;
__u32 rh_reserved; /* for use with fanotify */
struct hlist_head rh_reserved2; /* for use with fanotify */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list; ///构成mnt_namespace->list
struct list_head mnt_expire; /* link in fs-specific expiry list */
struct list_head mnt_share; /* circular list of shared mounts,构成shared mount list */
struct list_head mnt_slave_list;/* list of slave mounts, 所有slave mount组成的链表 */
struct list_head mnt_slave; /* slave list entry,构成slave mount list */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace,所属的namespace */
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
/*
* We put mnt_count & mnt_expiry_mark at the end of struct vfsmount
* to let these frequently modified fields in a separate cache line
* (so that reads of mnt_flags wont ping-pong on SMP machines)
*/
atomic_t mnt_count;
int mnt_expiry_mark; /* true if marked for expiry */
int mnt_pinned;
int mnt_ghosts;
#ifdef CONFIG_SMP
int *mnt_writers;
#else
int mnt_writers;
#endif
};mount() 里到底在哪处理 mnt namespace 的还没看到,这部分尚未完成。
// fs/namespace.c
// 参数:dev_name表示要挂载的设备名称,dir_name表示挂载点目录名称,type表示文件系统类型,flags表示挂载标志,data表示用于挂载的数据
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
int ret;
char *kernel_type;
char *kernel_dev;
unsigned long data_page;
kernel_type = copy_mount_string(type); // 将type参数从用户空间复制到内核空间中
ret = PTR_ERR(kernel_type);
if (IS_ERR(kernel_type))
goto out_type;
kernel_dev = copy_mount_string(dev_name); // 将dev_name参数从用户空间复制到内核空间中
ret = PTR_ERR(kernel_dev);
if (IS_ERR(kernel_dev))
goto out_dev;
ret = copy_mount_options(data, &data_page); // 将data参数从用户空间复制到内核空间中,并返回一个指向新分配的内存页面的指针
if (ret < 0)
goto out_data;
ret = do_mount(kernel_dev, dir_name, kernel_type, flags,
(void *) data_page); // 进行实际的挂载操作
free_page(data_page);
out_data:
kfree(kernel_dev);
out_dev:
kfree(kernel_type);
out_type:
return ret;
}/*
dev_name: 字符串类型,表示要挂载的设备名,如果不需要设备名,则该参数为 NULL。
dir_name: 字符串类型,表示要挂载的目录路径。
type_page: 字符串类型,表示要挂载的文件系统类型,以 NULL 结尾,如果为 NULL,则表示需要自动检测文件系统类型。
flags: 一个位掩码,表示挂载时的选项。各个选项可以通过按位或(|)的方式组合使用。
data_page: 挂载选项的数据。它是一个指针,指向用于传递挂载选项的数据缓冲区。如果不需要挂载选项,则该参数为 NULL。
*/
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct path path;
int retval = 0;
int mnt_flags = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
// 检查目录名是否为空或者是否超出了内存限制
if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE))
return -EINVAL;
// 将缓冲区的最后一个字节设置为 0
if (data_page)
((char *)data_page)[PAGE_SIZE - 1] = 0;
/* ... and get the mountpoint */
retval = kern_path(dir_name, LOOKUP_FOLLOW, &path);
if (retval)
return retval;
retval = security_sb_mount(dev_name, &path,
type_page, flags, data_page);
if (retval)
goto dput_out;
/* Default to relatime unless overriden */
if (!(flags & MS_NOATIME))
mnt_flags |= MNT_RELATIME;
/* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY;
flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN |
MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT |
MS_STRICTATIME);
if (flags & MS_REMOUNT)
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags,
data_page);
else if (flags & MS_BIND)
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name);
else
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}static int do_new_mount(struct path *path, const char *fstype, int flags,
int mnt_flags, const char *name, void *data)
{
struct file_system_type *type;
struct user_namespace *user_ns = current->nsproxy->mnt_ns->user_ns;
struct vfsmount *mnt;
int err;
......
err = do_add_mount(real_mount(mnt), path, mnt_flags);
if (err)
mntput(mnt);
return err;
}static int do_add_mount(struct mount *newmnt, struct path *path, int mnt_flags)
{
struct mountpoint *mp;
struct mount *parent;
int err;
mnt_flags &= ~MNT_INTERNAL_FLAGS;
mp = lock_mount(path);
if (IS_ERR(mp))
return PTR_ERR(mp);
parent = real_mount(path->mnt);
err = -EINVAL;
if (unlikely(!check_mnt(parent))) {
/* that's acceptable only for automounts done in private ns */
if (!(mnt_flags & MNT_SHRINKABLE))
goto unlock;
/* ... and for those we'd better have mountpoint still alive */
if (!parent->mnt_ns)
goto unlock;
}
/* Refuse the same filesystem on the same mount point */
err = -EBUSY;
if (path->mnt->mnt_sb == newmnt->mnt.mnt_sb &&
path->mnt->mnt_root == path->dentry)
goto unlock;
err = -EINVAL;
if (d_is_symlink(newmnt->mnt.mnt_root))
goto unlock;
newmnt->mnt.mnt_flags = mnt_flags;
err = graft_tree(newmnt, parent, mp);
unlock:
unlock_mount(mp);
return err;
}struct net *copy_net_ns(unsigned long flags,
struct user_namespace *user_ns, struct net *old_net)
{
struct net *net;
int rv;
if (!(flags & CLONE_NEWNET)) // 没 CLONE_NEWNET 标志就用老的 net namespace
return get_net(old_net);
net = net_alloc(); // 分配内存
if (!net)
return ERR_PTR(-ENOMEM);
get_user_ns(user_ns);
mutex_lock(&net_mutex); // 这里为什么要上锁啊?
rv = setup_net(net, user_ns); // 应该主要是这个函数来设置 net namespace
if (rv == 0) {
rtnl_lock();
list_add_tail_rcu(&net->list, &net_namespace_list);
rtnl_unlock();
}
mutex_unlock(&net_mutex); // 解锁
if (rv < 0) {
put_user_ns(user_ns);
net_drop_ns(net);
return ERR_PTR(rv);
}
return net;
}/*
* setup_net runs the initializers for the network namespace object.
*/
static __net_init int setup_net(struct net *net, struct user_namespace *user_ns)
{
/* Must be called with net_mutex held */
const struct pernet_operations *ops, *saved_ops;
int error = 0;
LIST_HEAD(net_exit_list);
atomic_set(&net->count, 1);
atomic_set(&net->passive, 1); // 表示网络命名空间是否处于被动模式(仅用于 IPv6)
net->dev_base_seq = 1; // 设备编号的起始值
net->user_ns = user_ns;
idr_init(&net->netns_ids);
// 遍历 pernet_list 链表中的每个网络子系统,并调用其 ops_init 函数初始化网络子系统
list_for_each_entry(ops, &pernet_list, list) {
error = ops_init(ops, net);
if (error < 0)
goto out_undo;
}
out:
return error;
out_undo:
/* Walk through the list backwards calling the exit functions
* for the pernet modules whose init functions did not fail.
*/
list_add(&net->exit_list, &net_exit_list);
saved_ops = ops;
list_for_each_entry_continue_reverse(ops, &pernet_list, list)
ops_exit_list(ops, &net_exit_list);
ops = saved_ops;
list_for_each_entry_continue_reverse(ops, &pernet_list, list)
ops_free_list(ops, &net_exit_list);
rcu_barrier();
goto out;
}// file: include/linux/netdevice.h
struct net_device{
//设备名
char name[IFNAMSIZ];
//网络命名空间
possible_net_t *nd_net;
...
}//file:include/net/net_namespace.h
struct net {
atomic_t passive; /* To decided when the network
* namespace should be freed.
*/
atomic_t count; /* To decided when the network
* namespace should be shut down.
*/
spinlock_t rules_mod_lock;
atomic64_t cookie_gen;
struct list_head list; /* list of network namespaces 链表头,用于连接所有网络命名空间 */
struct list_head cleanup_list; /* namespaces on death row 链表头,用于管理即将销毁的网络命名空间 */
struct list_head exit_list; /* Use only net_mutex */
struct user_namespace *user_ns; /* Owning user namespace */
struct idr netns_ids; // IDR,用于管理网络命名空间的唯一标识符
struct ns_common ns;
struct proc_dir_entry *proc_net; // 指向 procfs 中 /proc/net 目录的指针
struct proc_dir_entry *proc_net_stat; // 指向 procfs 中 /proc/net/stat 目录的指针
#ifdef CONFIG_SYSCTL
struct ctl_table_set sysctls;
#endif
struct sock *rtnl; /* rtnetlink socket */
struct sock *genl_sock;
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
unsigned int dev_base_seq; /* protected by rtnl_mutex */
int ifindex;
unsigned int dev_unreg_count;
/* core fib_rules */
struct list_head rules_ops;
// 每个 net 中都有一个回环设备
struct net_device *loopback_dev; /* The loopback */
struct netns_core core;
struct netns_mib mib;
struct netns_packet packet;
struct netns_unix unx;
// 在这个数据结构里,定义了每一个网络空间专属的路由表、ipfilter 以及各种内核参数
struct netns_ipv4 ipv4;
#if IS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
#if IS_ENABLED(CONFIG_IEEE802154_6LOWPAN)
struct netns_ieee802154_lowpan ieee802154_lowpan;
#endif
#if defined(CONFIG_IP_SCTP) || defined(CONFIG_IP_SCTP_MODULE)
struct netns_sctp sctp;
#endif
#if defined(CONFIG_IP_DCCP) || defined(CONFIG_IP_DCCP_MODULE)
struct netns_dccp dccp;
#endif
#ifdef CONFIG_NETFILTER
struct netns_nf nf;
struct netns_xt xt;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct netns_ct ct;
#endif
#if defined(CONFIG_NF_TABLES) || defined(CONFIG_NF_TABLES_MODULE)
struct netns_nftables nft;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
struct netns_nf_frag nf_frag;
#endif
struct sock *nfnl;
struct sock *nfnl_stash;
#endif
#ifdef CONFIG_WEXT_CORE
struct sk_buff_head wext_nlevents;
#endif
struct net_generic __rcu *gen;
/* Note : following structs are cache line aligned */
#ifdef CONFIG_XFRM
struct netns_xfrm xfrm;
#endif
#if IS_ENABLED(CONFIG_IP_VS)
struct netns_ipvs *ipvs;
#endif
#if IS_ENABLED(CONFIG_MPLS)
struct netns_mpls mpls;
#endif
struct sock *diag_nlsk;
atomic_t fnhe_genid;
};socket 创建:
// net/socket.c
// socket 创建
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}// include/net/sock.h
// 调用流程:__sock_create => inet_create => sk_alloc
static inline
void sock_net_set(struct sock *sk, struct net *net)
{
write_pnet(&sk->sk_net, net); // 设置新 socket 和 netns 的关联关系
}// include/net/net_namespace.h
static inline void write_pnet(possible_net_t *pnet, struct net *net)
{
#ifdef CONFIG_NET_NS
pnet->net = net;
#endif
}User namespace 不和其他 namespace 放在一起可能是因为 user namespace 会影响其他 namespace 的执行结果。具体的例子还没看到。
user namespace 的内容和其他5个 namespace 比起来有点特殊,所以很多东西就放在这里单独看。先来一张结构图:
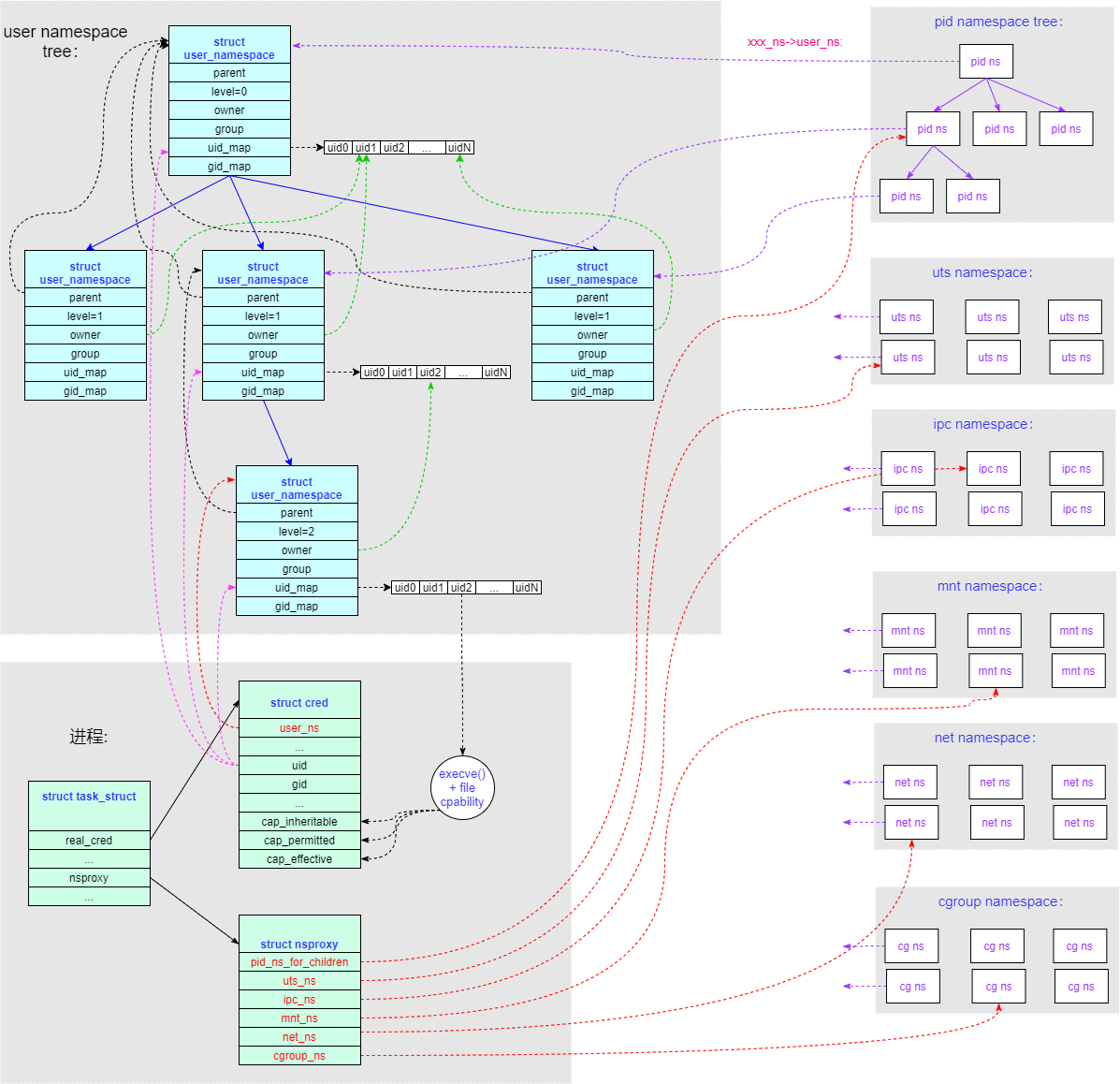
一个 task_struct 结构内不止有一个 user_namespace:
- 本进程所在的 user namespace 为
task->real_cred->user_ns,调用 getpid()/getuid() 所获得的返回值就是由这个 user_namespace 决定的。 - 其他类型的 namespace 中会有指针成员链接到 user_namespace(即
xxx_ns->user_ns),这个 user namespace 就是创建相应 namespace 时进程所属的 user namespace,相当于每个 namespace 都有一个 owner(user namespace)。
这两个 user_namespace 不一定相等。猜测:如果一个进程继承了父进程的 user_namespace,但某个 namespace 用的是别的进程的(也即该进程并非所有 namespace 都是用的父进程的),那是不是就有可能出现自己的 user_namespace 和某个 namespace 的 user_namespace 不相同的情况?
user_namespace 是呈现树状结构的,上述的两种 user_namespace,每一个都是其中的节点。
创建 user namespace 的地方和创建其他 namespace 的不一样,调用路径为 copy_process() → copy_creds() → create_user_ns(),
/*
* Create a new user namespace, deriving the creator from the user in the
* passed credentials, and replacing that user with the new root user for the
* new namespace.
*
* This is called by copy_creds(), which will finish setting the target task's
* credentials.
*/
int create_user_ns(struct cred *new)
{
struct user_namespace *ns, *parent_ns = new->user_ns;
kuid_t owner = new->euid;
kgid_t group = new->egid;
int ret;
if (parent_ns->level > 32) // user namespace 有深度限制
return -EUSERS;
/*
* Verify that we can not violate the policy of which files
* may be accessed that is specified by the root directory,
* by verifing that the root directory is at the root of the
* mount namespace which allows all files to be accessed.
*/
if (current_chrooted())
return -EPERM;
/* The creator needs a mapping in the parent user namespace
* or else we won't be able to reasonably tell userspace who
* created a user_namespace.
*/
if (!kuid_has_mapping(parent_ns, owner) ||
!kgid_has_mapping(parent_ns, group))
return -EPERM;
ns = kmem_cache_zalloc(user_ns_cachep, GFP_KERNEL); // 分配新的 user namespace 内存空间
if (!ns)
return -ENOMEM;
ret = ns_alloc_inum(&ns->ns);
if (ret) {
kmem_cache_free(user_ns_cachep, ns);
return ret;
}
ns->ns.ops = &userns_operations;
atomic_set(&ns->count, 1);
// 初始化 user namespace 的各个成员
/* Leave the new->user_ns reference with the new user namespace. */
ns->parent = parent_ns; // 父节点
ns->level = parent_ns->level + 1; // 在父节点基础上增加level
ns->owner = owner; // 设置 user ns 的 owner uid
ns->group = group; // 设置 user ns 的 owner gid
/* Inherit USERNS_SETGROUPS_ALLOWED from our parent */
mutex_lock(&userns_state_mutex);
ns->flags = parent_ns->flags;
mutex_unlock(&userns_state_mutex);
set_cred_user_ns(new, ns); // 将新的 user namespace 设置到 cred->user_ns
#ifdef CONFIG_PERSISTENT_KEYRINGS
init_rwsem(&ns->persistent_keyring_register_sem);
#endif
return 0;
}static void set_cred_user_ns(struct cred *cred, struct user_namespace *user_ns)
{
/* Start with the same capabilities as init but useless for doing
* anything as the capabilities are bound to the new user namespace.
*/
// 对于本 user namespace 初始的第一进程,赋予所有的 capability
cred->securebits = SECUREBITS_DEFAULT;
cred->cap_inheritable = CAP_EMPTY_SET;
cred->cap_permitted = CAP_FULL_SET;
cred->cap_effective = CAP_FULL_SET;
cred->cap_bset = CAP_FULL_SET;
#ifdef CONFIG_KEYS
key_put(cred->request_key_auth);
cred->request_key_auth = NULL;
#endif
/* tgcred will be cleared in our caller bc CLONE_THREAD won't be set */
cred->user_ns = user_ns; // 替换 cred 中的 user_ns 为新值
}user namespace 在 create_new_namespaces() 中是没有相应的 copy_xxx 函数的,因为它作为成员被包含在其他5个 namespace 里了。
在 clone_uts_ns()、create_ipc_ns() 和 create_pid_namespace() 中(其他俩还没看),都有这个语句:
ns->user_ns = get_user_ns(user_ns);static inline struct user_namespace *get_user_ns(struct user_namespace *ns)
{
if (ns) // 检查 ns 是否为空
atomic_inc(&ns->count); // 引用计数++
return ns; // 把 ns 原样返回
}也就是说,如果需要新建某个 namespace 的话,user_ns 成员就赋值为原有的 user_ns。
// 本结构体记录的是进程的用户和组信息的命名空间,包括用户 ID 范围、组 ID 范围、用户、组、密码等信息
struct user_namespace {
struct uid_gid_map uid_map;
struct uid_gid_map gid_map;
struct uid_gid_map projid_map;
atomic_t count; // 命名空间引用计数,表示当前有多少个进程引用了这个命名空间
struct user_namespace *parent; // 父 user_namespace
int level; // 深度
kuid_t owner;
kgid_t group;
struct ns_common ns; // 用于命名空间管理的公共命名空间结构体
unsigned long flags;
/* Register of per-UID persistent keyrings for this namespace */
#ifdef CONFIG_PERSISTENT_KEYRINGS
struct key *persistent_keyring_register;
struct rw_semaphore persistent_keyring_register_sem;
#endif
};/*
* The security context of a task
*
* The parts of the context break down into two categories:
*
* (1) The objective context of a task. These parts are used when some other
* task is attempting to affect this one.
*
* (2) The subjective context. These details are used when the task is acting
* upon another object, be that a file, a task, a key or whatever.
*
* Note that some members of this structure belong to both categories - the
* LSM security pointer for instance.
*
* A task has two security pointers. task->real_cred points to the objective
* context that defines that task's actual details. The objective part of this
* context is used whenever that task is acted upon.
*
* task->cred points to the subjective context that defines the details of how
* that task is going to act upon another object. This may be overridden
* temporarily to point to another security context, but normally points to the
* same context as task->real_cred.
*/
struct cred { // 本结构体用于表示进程的身份认证信息,包括用户 ID(UID)、组 ID(GID)、安全令牌等
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; // 进程的真实用户 ID
kgid_t gid; // 进程的真实组 ID
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; // 进程的有效用户 ID
kgid_t egid; // 进程的有效组 ID
kuid_t fsuid; // 进程的文件系统用户 ID,用于文件系统操作的权限检查
kgid_t fsgid; // 进程的文件系统组 ID,用于文件系统操作的权限检查
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; // 指向进程所属的 user_namespace 结构体
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};SYSCALL_DEFINE0(getuid)
{
/* Only we change this so SMP safe */
// current_uid() 获取的是全局 uid,current_user_ns() 获取的是当前 user ns;将全局 uid 转换成当前 user ns 中的 uid
return from_kuid_munged(current_user_ns(), current_uid());
}uid_t from_kuid_munged(struct user_namespace *targ, kuid_t kuid)
{
uid_t uid;
uid = from_kuid(targ, kuid); // 通过查询 uid_map 把全局 uid 转换成对应 user ns 的 uid
if (uid == (uid_t) -1)
uid = overflowuid;
return uid;
}map_write() 中有过一个漏洞,CVE-2018-18955。
Mnt Namespace 详解 - 泰晓科技 (tinylab.org)
Namespace 在 Kernel 里是怎么实现的?以 mount namespace 为例 – 肥叉烧 feichashao.com