modify counting active workers #769
Conversation
|
Thank you for your pull request and welcome to our community. We could not parse the GitHub identity of the following contributors: wangpei6.
|
0ecf8a1
to
b565e46
Compare
| @@ -57,9 +58,10 @@ public ClusterStats getClusterStats() | |||
| long blockedQueries = 0; | |||
| long queuedQueries = 0; | |||
|
|
|||
| long activeNodes = nodeManager.getNodes(NodeState.ACTIVE).size(); | |||
There was a problem hiding this comment.
I need to restart the coordinator without the user's awareness, so I will start the second coordinator in the same cluster to switch traffic, and the second coordinator will be closed after the restart. When the second coordinator started, I found that the number of active workers was incorrect, so I submit this commit for this reason. Thanks!
There was a problem hiding this comment.
Such scenario: "two coordinators registered to same discovery server" is not supported by Presto ATM, so workers and coordinator behavior is undefined. Definitely currently running queries will fail when coordinator is killed.
Correct way to do coordinator turnover is to have some kind of load balancer or name resolution for coordinator that would be routing to the currently active coordinator.
There was a problem hiding this comment.
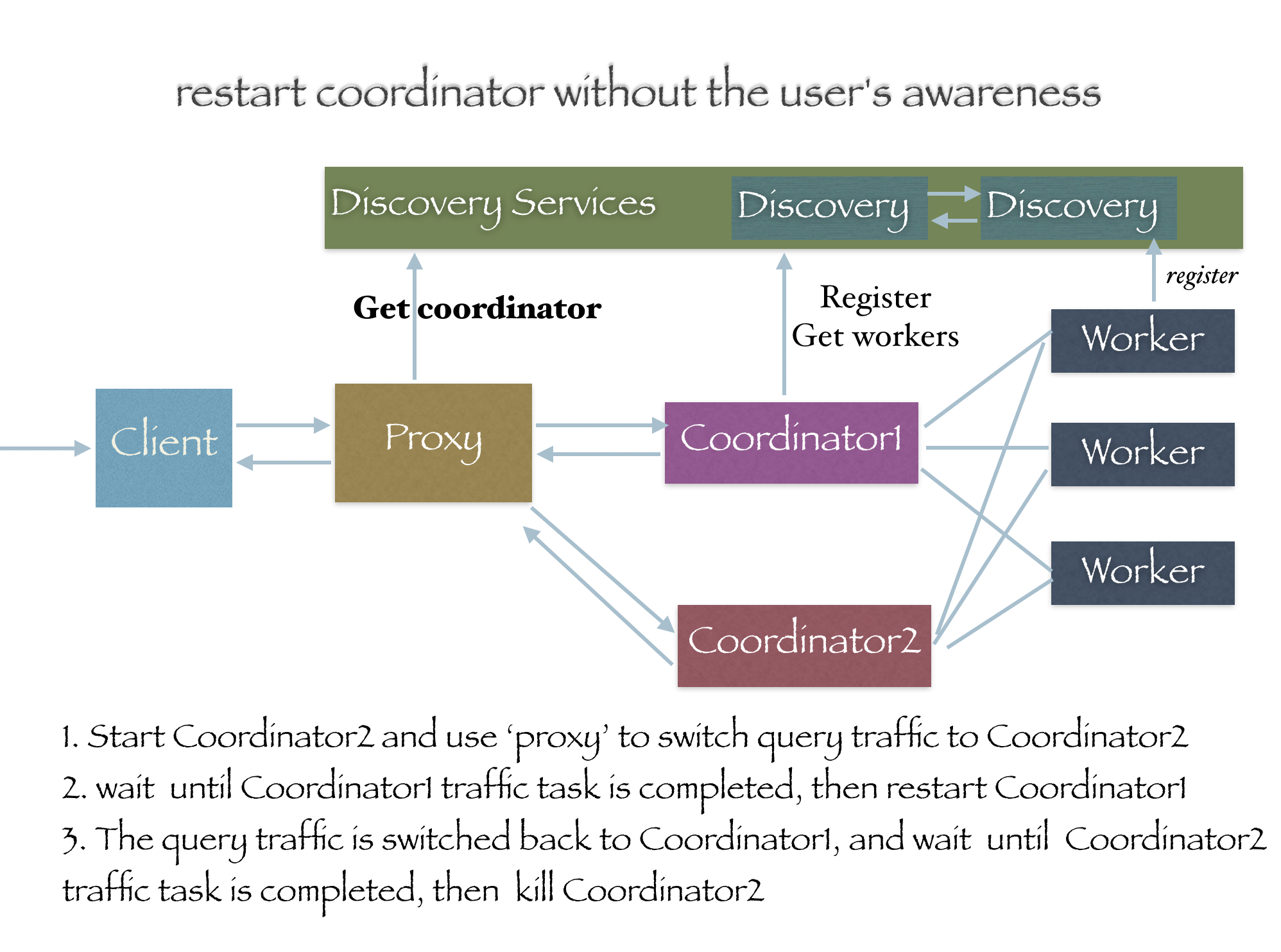
The picture shows the details of our restart ,i need restart the coordinator without user's awareness,that is ,the running queries can not be affected. So i figure out the picture solution .Maybe there is better solution that i don't know, i really appreciate it if you can tell me.Thanks !
By the way ,i have do this more than 20 times, no any effects。
presto-main/src/main/java/io/prestosql/server/ClusterStatsResource.java
Outdated
Show resolved
Hide resolved
b16a1e6
to
004fc14
Compare
|
My PR builds failed, but through the log, it seems that the errors have nothing to do with my PR. Sorry, I don't know what to do. I need help . |
| long activeNodes = nodeManager.getNodes(NodeState.ACTIVE).size(); | ||
| if (!isIncludeCoordinator) { | ||
| activeNodes -= 1; | ||
| long activeNodes = nodeManager.getNodes(NodeState.ACTIVE).stream() |
There was a problem hiding this comment.
If we change this to:
long activeWorkers = nodeManager.getNodes(NodeState.ACTIVE).stream()
.filter(node -> isIncludeCoordinator || !node.isCoordinator())
.count();
It will ignore coordinators in this count unless, isIncludeCoordinator is set, so if you have multiple coordinator and are including them, you get the right count.
|
@dain, Hi, dain, thanks very much for your reply. Your proposed code: long activeWorkers = nodeManager.getNodes(NodeState.ACTIVE).stream()
.filter(node -> isIncludeCoordinator || !node.isCoordinator())
.count();I think the codes have some problems, for example: according to your code, There's also something wrong with my submitted code,which is: long activeWorkers = nodeManager.getNodes(NodeState.ACTIVE).stream()
.filter(node -> !node.isCoordinator())
.count();
if (isIncludeCoordinator){
activeWorkers += 1;
}
In the same cluster, according to my code, It seems that neither of these two solutions is perfect. In addition, the value of the attribute `node-scheduler.include-coordinator'in each coordinator cannot be obtained in the discovery service. So, I think there are two choices at present. One is to modify the discovery service code and know the value of the attribute `node-scheduler.include-coordinator'in each coordinator, so that we can get the exact number of workers. The other is to assume that each coordinator can only see itself and other workers, and can not see other coordinators. The code I submitted fits this situation. The above is my opinion. Please be free to review. |
SummaryI'm going to try to summarize. We have two possible solutions that both start by counting the workers (non-coordinators), and then modify the count depending on the "include coordinators" configuration. The two different modifications are:
Both give the correct answer if you only have a single coordinator. The first one gives the wrong answer when multiple coordinators have "include coordinators" enabled. The second one gives the wrong answer anytime the coordinators have different configurations. Does the above summary look correct? ThoughtsMy thoughts on this are based on following observations:
Based on 1, either of the solutions is good enough, but based on 2, I would expect most people to use the same configuration for all coordinators, which gives me a slight preference for the "add all coordinators" proposal. The long term answer is we'll need to adjust the announcements, when adding support for multiple coordinators (#391) |
|
@PennyAndWang, BTW we will need an individual CLA (https://github.com/prestosql/cla) from you to accept this contribution. |
|
@dain ,I agree with your summary and your thoughts . BTW, �I missed the reply from Martin about my presto-cla file, really sorry about this. �I have re-send my presto-cla file to Martin yesterday and I am waiting his check. |
|
@cla-bot check |
|
The cla-bot has been summoned, and re-checked this pull request! |
… and add ClusterStats.activeCoordinators property
b640980
to
e0d1f56
Compare
@dain ,done!Build errored again ,errors have nothing to do with my PR. I don't know what to do ,sorry . |
|
The error is unrelated. Merged. Thanks! |
Hi, this commit is for the issue: #641 . In my situation ,maybe it is not real coordinator HA, just a trick for restarting coodinator, but I think the code is more appropriate for my situation。Thanks !