about the result #3
Comments
|
The same problem as above. I have also tried to save 'pre_fc1_bias.npy' and 'pre_fc1_weights.npy' manually, sicnce the arcface pretrained model is not spcified by the author, but the problem still exists. |
|
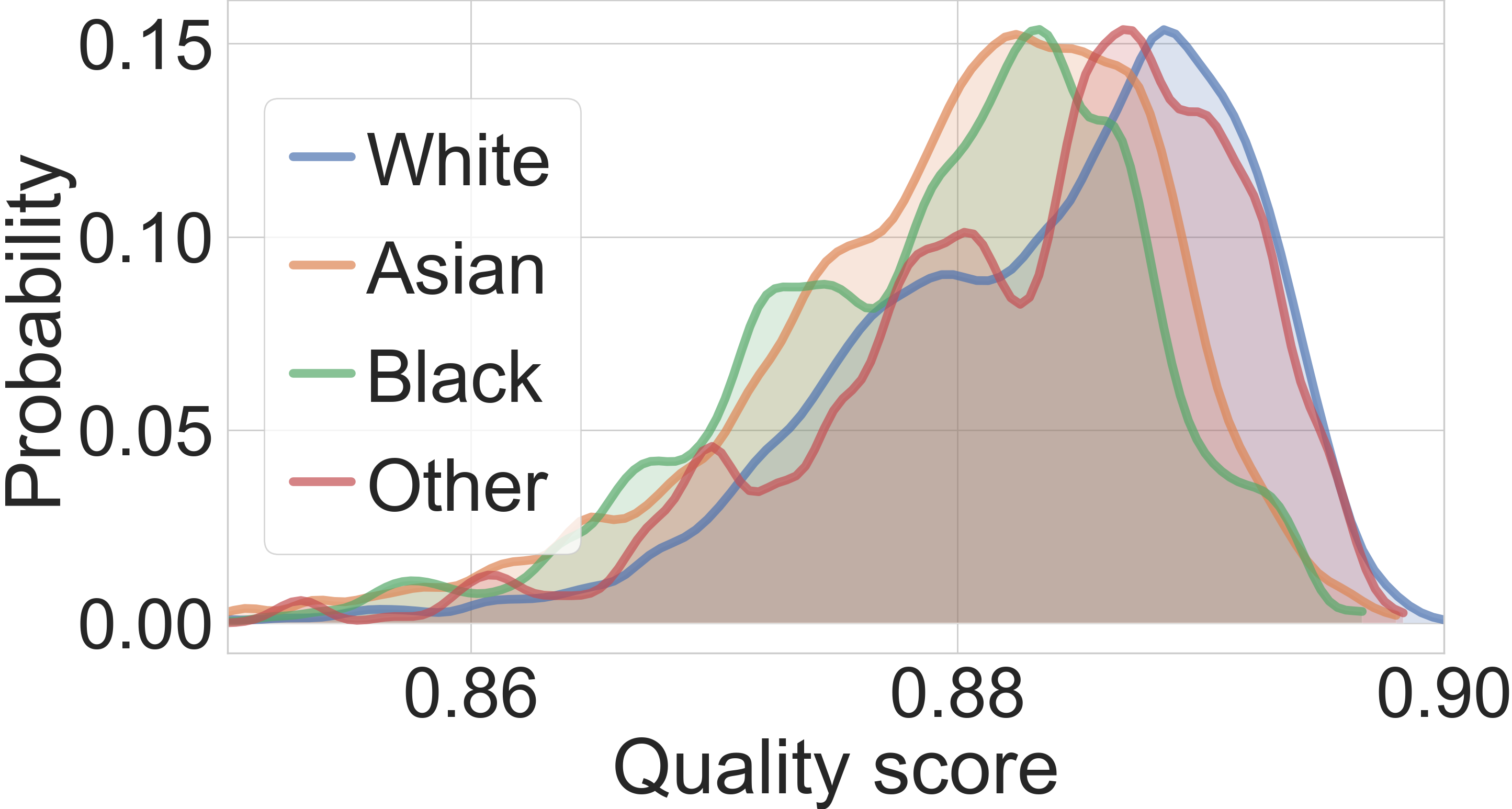
Hi, @sunny0315: If you look at the following paper, what is also shown in the repository, you will see that the score distribution of SER-FIQ on Arcface is mostly in the range of 0.86-0.90: @codelilei : The weights stored in the data folder are the weights that were used for the experiments. We have used a pretrained model from Insightface's model zoo. The model used in our experiments is the "LResNet100E-IR,ArcFace@ms1m-refine-v2" pre-trained model, downloaded in April 2019. If you have further questions, please do not hesitate to ask them. Best regards, |
|
Hi everyone, As Jan already mentioned, unfortunately, SER-FIQ on ArcFace produces very narrow quality estimates. Although this narrow quality range is unconvienet, it is still meaningful! (If you take more than 2 decimal places into account). To get a more "natural" quality range, you can simply use scaling methods, such as MinMax normalization. Or, if you are interested, we can add a scaling parameter to the model to output quality scores in a convient range of [0,1]. Best, |
@jankolf yeah, I got exactly the same weights saved from "LResNet100E-IR,ArcFace@ms1m-refine-v2" downloaded yesterday. I was mainly confused about the fact that the profile face image could also get a score higher than 0.8, which seemed to be inconsistent with the first impression brought by the distribution figure shown in your another paper https://arxiv.org/abs/2004.01019.
Now it seems to make sense, I didn't notice the starting point of the x-coordinate. I will try more images later and focus on the relative size relation. Nice work! Thanks for your quick reply! |
|
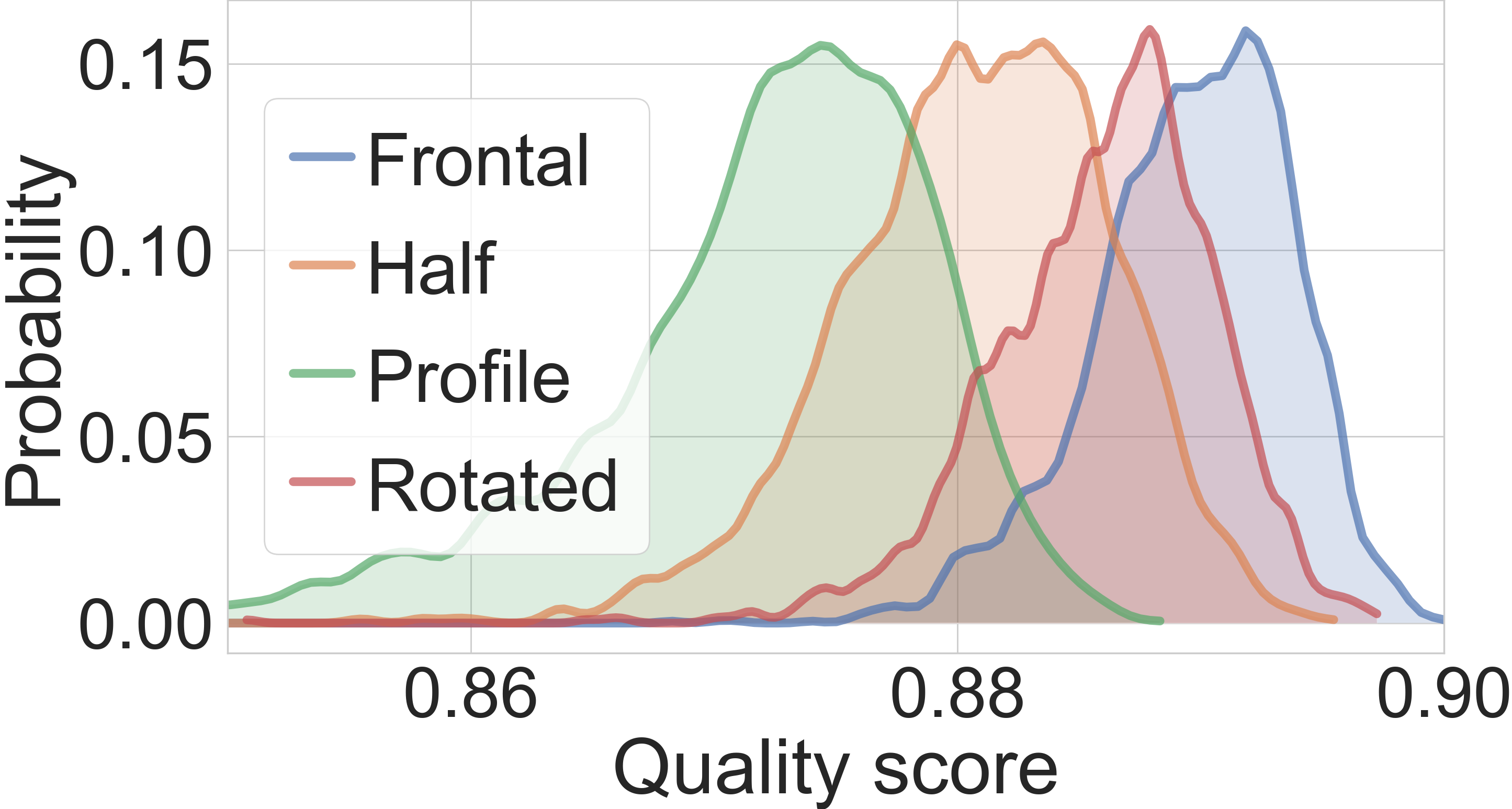
@jankolf @pterhoer Thanks for your quick reply! At first, I thought that based on this score, we could solve the problem such as pose, occlusions and expressions which learned from the paper https://arxiv.org/pdf/2003.09373.pdf.So I found some representative pictures, and their scores didn't seem to have a strong correlation and can't filter them just by setting a score threshold(probability may lead to misjudgment).Maybe this method can be used to judge whether it is suitable for a recognition system. |

{kind=link}
{kind=link}
|
@codelilei Thanks for your feedback! If you find any other problems, just contact us. @sunny0315 The face quality score of SER-FIQ relates to how well the deployed face recognition model can deal with the input image. If your network can deal well with various poses, occlusions, and expressions, SER-FIQ will not produce low quality values. In this cases, I would recommend to use a network that is not robust to such variations. Then SER-FIQ will produce low quality values for images with these variations. |
|
@pterhoer |
You are welcome :) |
|
Hi @pterhoer
|
|
Hi again RyanCV, if your network can deal well with variations, such as poses, occlussions, and expressions, it will produce relatively stable representations. Stable representations leads to less variations in the stochastic embeddings and thus, to a high robustness and quality estimates. Best, |
I try to run the file 'serfiq_example.py' and got the result of two test images which you providied in './data/'. The score of 'test_img.jpeg' is 0.89 ,and the score of 'test_img2.jpeg' is 0.87.Are the resuls correct? Yet,I test on other images like side faces and front faces.But their results are indistinguishable,Is there something wrong with my use? Thank you for your reply!
The text was updated successfully, but these errors were encountered: