speed up beam search by ~2x #1851
Labels
Comments
|
Very nice! |
moussaKam
pushed a commit
to moussaKam/language-adaptive-pretraining
that referenced
this issue
Sep 29, 2020
Summary: # Before submitting - [x] Was this discussed/approved via a Github issue? (no need for typos, doc improvements) - [x] Did you read the [contributor guideline](https://github.com/pytorch/fairseq/blob/master/CONTRIBUTING.md)? - [ ] Did you make sure to update the docs? - [ ] Did you write any new necessary tests? ## What does this PR do? Fixes facebookresearch#1851 . ## PR review Anyone in the community is free to review the PR once the tests have passed. If we didn't discuss your PR in Github issues there's a high chance it will not be merged. ## Did you have fun? Make sure you had fun coding � Pull Request resolved: facebookresearch#1852 Reviewed By: ngoyal2707 Differential Revision: D20490964 Pulled By: myleott fbshipit-source-id: 22f6c849408029f5432e531589da29d95e31d392
mgaido91
pushed a commit
to mgaido91/FBK-fairseq-ST
that referenced
this issue
Jan 12, 2021
Summary: # Before submitting - [x] Was this discussed/approved via a Github issue? (no need for typos, doc improvements) - [x] Did you read the [contributor guideline](https://github.com/pytorch/fairseq/blob/master/CONTRIBUTING.md)? - [ ] Did you make sure to update the docs? - [ ] Did you write any new necessary tests? ## What does this PR do? Fixes facebookresearch/fairseq#1851 . ## PR review Anyone in the community is free to review the PR once the tests have passed. If we didn't discuss your PR in Github issues there's a high chance it will not be merged. ## Did you have fun? Make sure you had fun coding � Pull Request resolved: facebookresearch/fairseq#1852 Reviewed By: ngoyal2707 Differential Revision: D20490964 Pulled By: myleott fbshipit-source-id: 22f6c849408029f5432e531589da29d95e31d392
facebook-github-bot
pushed a commit
that referenced
this issue
May 6, 2021
Summary: see title Pull Request resolved: fairinternal/fairseq-py#1851 Reviewed By: michaelauli, arbabu123 Differential Revision: D28226892 Pulled By: alexeib fbshipit-source-id: e07641dda46be2708e1f9d0c0cbc5b8dedaa92e7
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
🚀 Feature Request
Speed up beam search ~2x by removing unnecessary reorder and merging small ops
Motivation
GPU utility is only ~40% during BART model inference. By profile, I see 2 issues in incremental generation.
Pitch
I created PR #1852 with below changes.
In encoder_decoder_attention, reorder only need when batch size change. Because encoder state
is shared across beam size.
Additional context
Inference speed (sample/s) on CNN-DM dataset using V100
(beam=4, lenpen=2.0, max_len_b=140, min_len=55)
Profile data to compare before and after change.
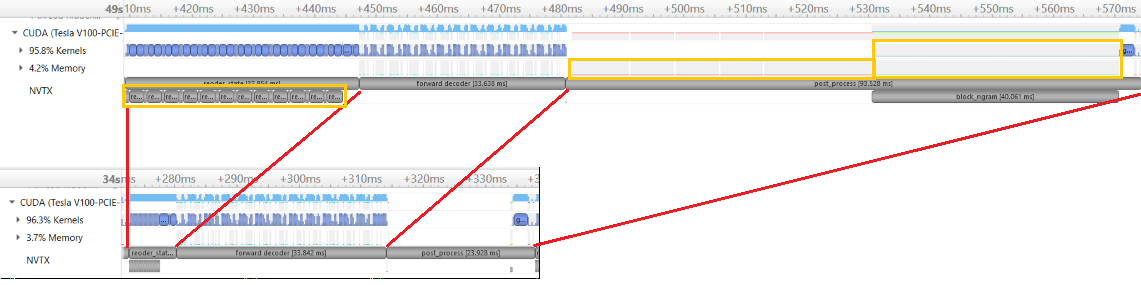
To benchmark the speed, run "CUDA_VISIBLE_DEVICES=0 python generation_speed_test.py".
benchmark code modify from here
cnndm_128.txt
generation_speed_test.py.txt
The text was updated successfully, but these errors were encountered: