Wav2Vec2 diversity loss problem #3673
Comments
|
diversity loss value of 0.1 is enough to ensure that a large portion of the codebook is used. you can try other values and monitor code_perplexity to see what percentage of the codebook is used (max value is num latent groups * num latent vars). the actual loss value of diversity loss doesnt matter, it exists to ensure sufficient codebook use and to promote exploration in the early training phase |
So is that means it doesn't matter how large the diversity loss is? Just make sure most of the codebooks are used is ok(by monitor |
yes. too high coefficient can also hurt the main objective |
|
Thank you alexeib!!!!! I get it~ @alexeib |
|
I found that my 'code_perplexity' is quite low(diversity weight 0.1, code_perplexity ~100, diversity weight 0.5, code_perplexity ~300). Can you please tell me what is the value of the code_perplexity or codebook percentage in the normal range when num of total codebooks is 640? @alexeib |
|
anything that is not super low will generally do ok. e.g. 100-500 range |
❓ Questions and Help
Before asking:
issue wav2vec 2.0: L2 penalty on features #3315
What is your question?
I've found that the diversity loss weight of wav2vec2.0 is 0.1, and a question about why the weight of diversity loss is this low was proposed in issue #3315 , but no answer is provided. So my first question is the same: Why such low a weight is assigned to diversity loss.
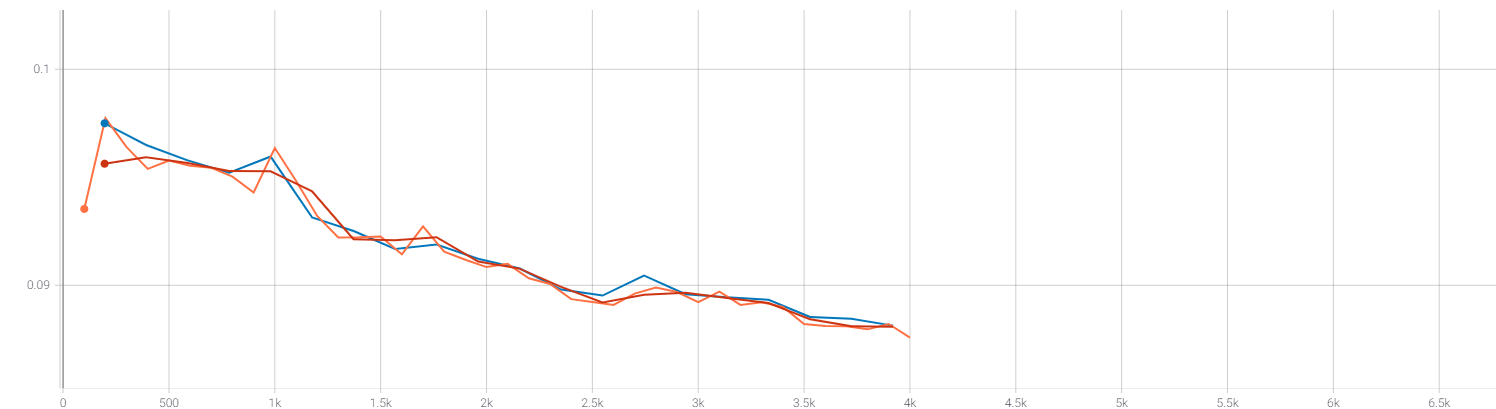
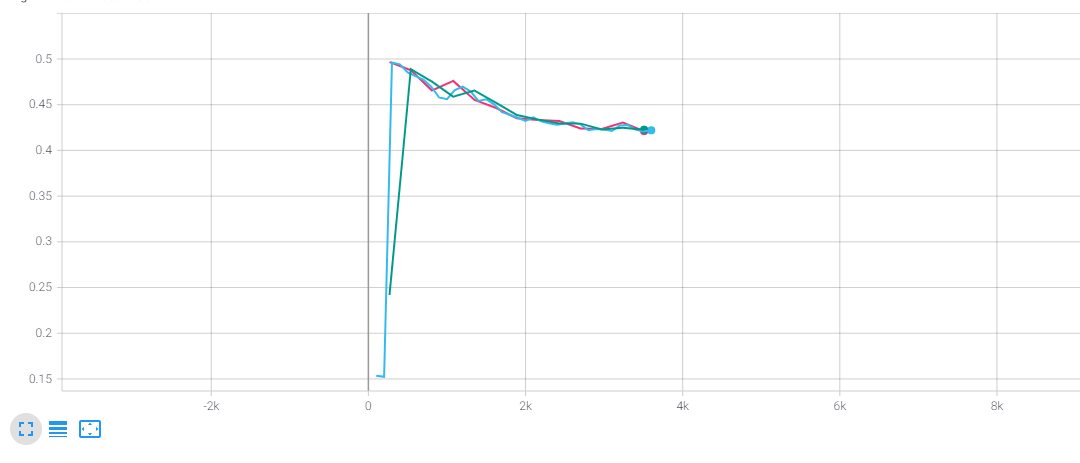
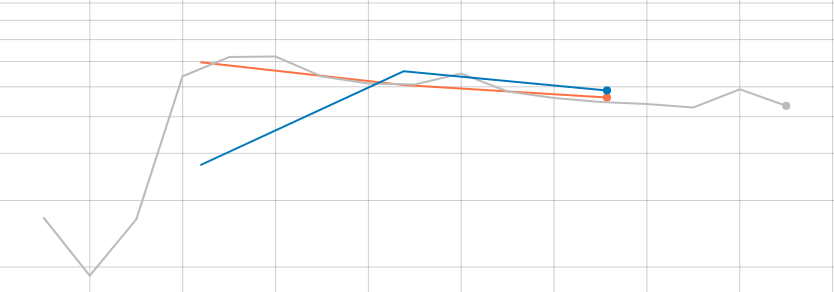
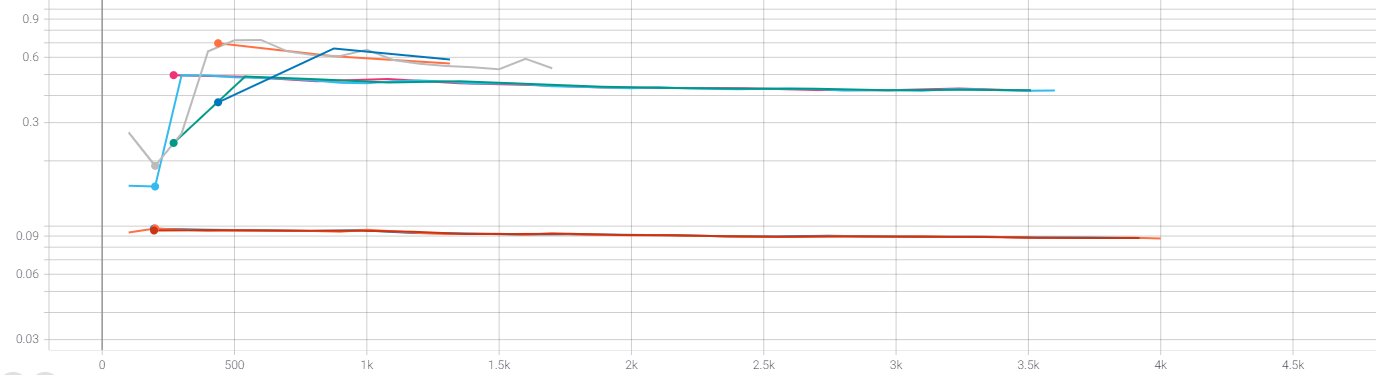
Also, I've tried to give different weights to this loss term ,such as 0.5,1.0, and I found weird loss curves like this:
weight= 0.1
weight= 0.5
weight= 1.0
all curves in one
The diversity loss always rise sharply in the first few epoches (and can't go down to the original loss). Is this a normal phenomenon or something wrong occured? Is it because that my training data is too small? Is there anything that can help me understand the codebook? How can I set the number of codebooks correctly?
What's your environment?
pip, source): sourceAny help is appreciated~~~
The text was updated successfully, but these errors were encountered: