distributed data parallel, gloo backend works, but nccl deadlock #17745
Comments
|
I have encoutered this problem. My problem is caused by different CUDA version. |
|
Can you please use https://github.com/pytorch/pytorch/blob/master/torch/utils/collect_env.py to report information about your system |
|
Had a similar issue. Mine was due to not issuing |
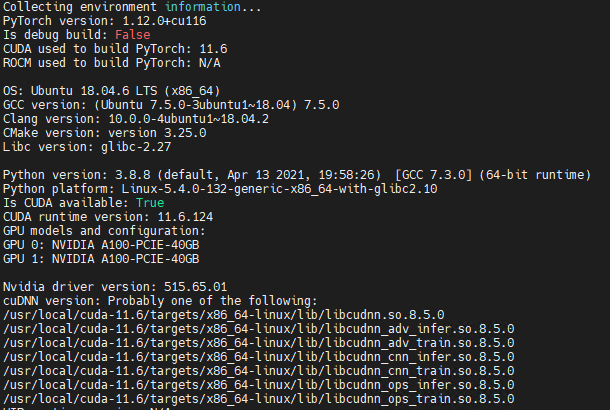



I fixed this by change another machine. So I guess maybe something wrong with the previous machine, and it has nothing to do with the software. |
I have run into the same problem as #14870 . Because I cannot reopen the issue, I opened a new issue. But the GPUs are all empty, except that 11MB memory is used (no process running).
The code is easy to reproduce:
After printing
it hangs.
But it works fine with
gloo.The text was updated successfully, but these errors were encountered: