wait() does not block the default stream for NCCL's asynchronous P2P operations #68866
Comments
|
Hi @vycezhong thanks for posting the question, If you look into the details of @pritamdamania explanation in #68112 (comment), it explained the
you can also use torch.distributed.send/recv instead of isend/recv to allow synchronous behavior :) Closing this issue, feel free to re-open if the question un-resolved. |
|
IIUC batch_isend_irecv followed by wait() should be equivalent to send/recv, although I think the former APIs have some limitations/bugs that are not ironed out. Should we keep this issue open until we can confirm whether it is a bug or not and track the appropriate fix if so? @wanchaol @pritamdamania87 |
|
FYI. When I use import os
from datetime import timedelta
import torch
def main():
local_rank = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
torch.distributed.init_process_group(
'nccl', init_method="env://",
timeout=timedelta(seconds=5)
)
rank = torch.distributed.get_rank()
size = (1000000, )
for _ in range(100):
dst_rank = (rank + 1) % 2
x = torch.ones(size=size, requires_grad=True).cuda()
y = torch.zeros(size=size, requires_grad=True).cuda()
torch.distributed.send(x, dst_rank)
torch.distributed.recv(y, dst_rank)
z = x + y
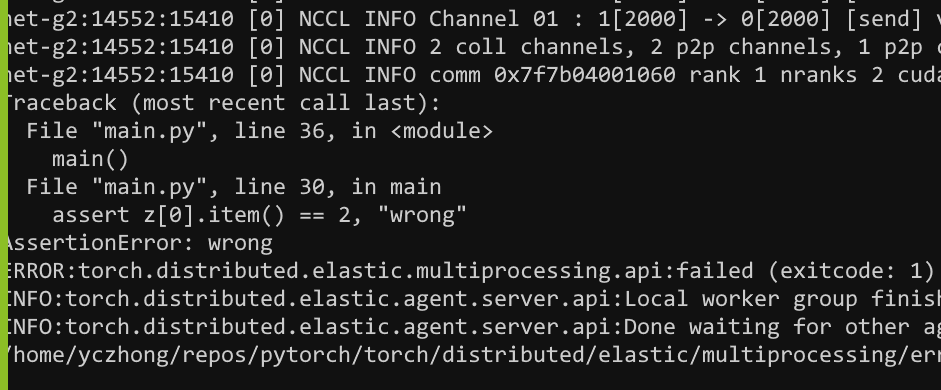
assert z[0].item() == 2, "wrong"
print("right")
if __name__ == '__main__':
main() |
According to the previous issue #68112 , PyTorch will block the default stream until the asynchronous NCCL's operations finish. However, our experience shows that this is not true.
Here is the minimal reproducible code.
The assert fails as shown in the figure below.
However, when we add an explicit cuda device synchronization (i.e., torch.cuda.synchronize()) before
z = x + y, it works well.I notice that torch.cuda.synchronize() is added after the wait() in the downstream repo Megatron-LM (https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/p2p_communication.py#L132-L137). So I am not sure whether it is a bug or a feature.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang
The text was updated successfully, but these errors were encountered: