[RFC]A suggestion of channels last memory format implementation for 3D tensor #74935
Comments
|
I am conceptually OK with ChannelsLast1D. I am very unhappy with the bitfield situation. I agree that absent any refactoring, we should do Proposal 2. |
|
For reference, the RFC from the repo: pytorch/rfcs#42 |
|
Thank you for the detailed RFC. The Core team isn't pursuing additional channels last memory format support at this time, however, and may not be available to review related PRs. We think it would require adding numerous kernels to provide this kind of support properly. |
Thanks @mruberry for the feedbacks. According to the suggestions from @VitalyFedyunin today, we will check and handle channels last 1D format inside individual performance-critical op kernels first (e.g., conv1d and maxpool1d) without explicitly exposing the |
|
any updates on this? |
|
1d still not added. |
Are you considering any particular case that needs this support? |
|
Recent language/speech/vision models often combine 1D convolutions and attention layers. See for example the EfficientFormer paper (specifically first bullet in bottom half of page 4) |
You may consider to do this implicitly in the implementation of convolution, i.e., check if the input is channels last 1d by its stride and do not force contiguous and leave the channels last 1d for output. Not necessarily to expose it as an explicit memory format. |
|
What do you mean with 'in the implementation of convolution'? my problem is I don't know how to call the cuDNN conv1D kernel with channels_last from pytorch. Also I'm not sure on what dimension BatchNorm operates on, as the documentation says it expects [batch, channels, ...] but if I don't use torch's .to(memory_format=torch.channels_last) it may operate across the wrong dimension, no? |
|
So I'm looking how to do conv_btc like facebookresearch/fairseq#172 is using torch.conv_tbc |
Note that the code I referred to actually forces the format to channels last 1d while if you ignore this forcing code, the conv implementation assumes the input is channels last 1d (if it is 3d) and does not force contiguous on it.
I believe BatchNorm can do this implicit approach similarly. The problem for promoting channels last 1d as a frontend API is that the ops need to cover are not that many compared with channels last 2d/3d. |
🚀 The feature, motivation and pitch
Motivation
Pytorch has already supported ChannelsLast(2d) for 4D tensor(N, C, H, W) and ChannelsLast3d for 5D tensor(N, C, H, W, D), but doesn't support ChannelsLast1d for 3D tensor(N, C, L). See below:
ChannelsLast for 4D tensor works fine:
ChannelsLast for 5D tensor works fine:
ChannelsLast for 3D tensor doens't work:
However, operators such as conv1d, pool1d etc. demand ChannelsLast1d to get better performance boost due to the natural advantages of Channels Last memory format.
Usage
After the feature is supported, it works as below:
Value
ChannelsLast1d feature would benifit such as time series analysis models, deep learning model based on Lidar data, voice model wav2vec, etc.
Proposed Implementation
Proposal 1:
The general implementation principle of proposal 1 is as below:
The details are as follows:
Regarding 1: Users can use it as below:
Regarding 2 and 3: As is known, for ChannelsLast(2d) and ChannelsLast3d, there are associated flags in TensorImpl structure as below:
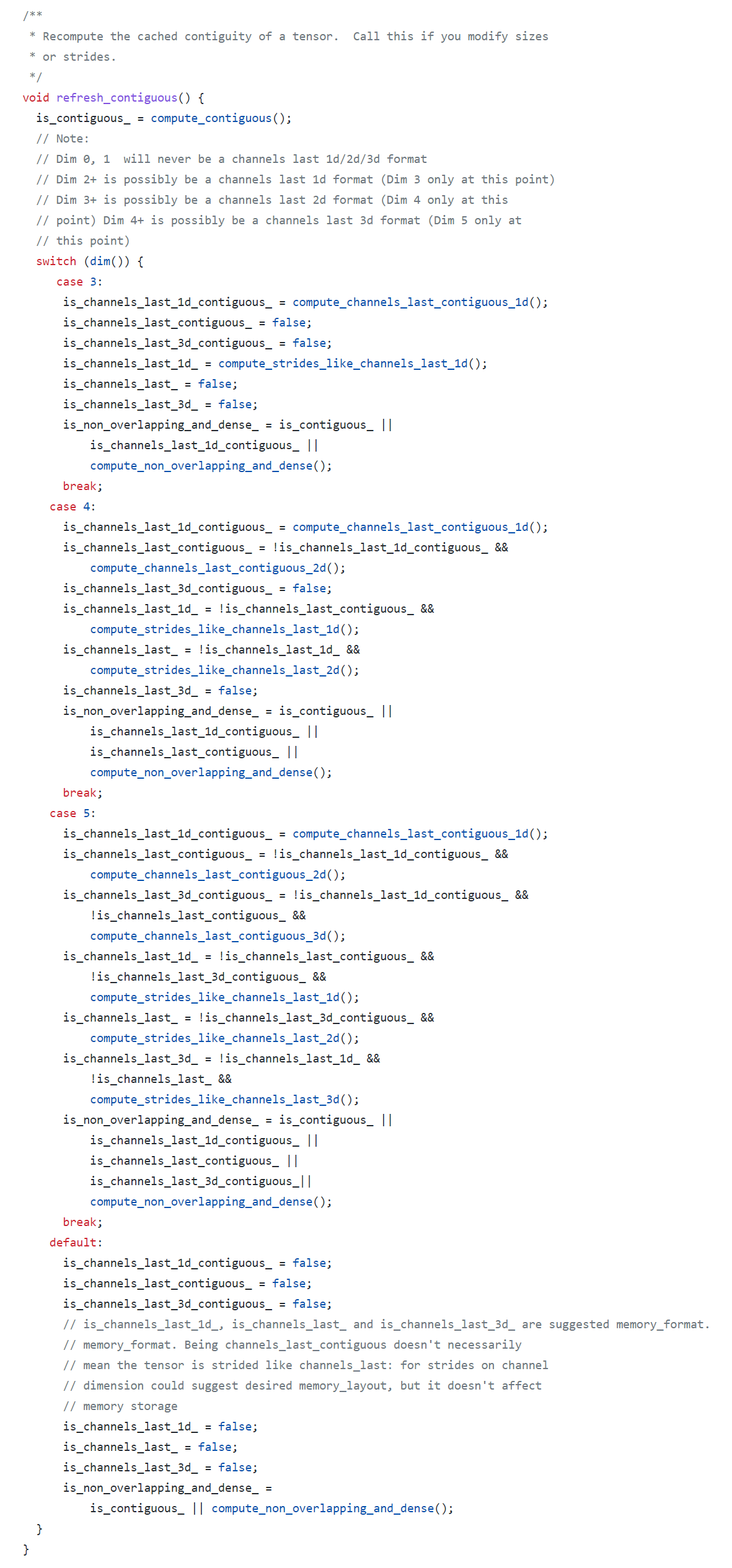
Then refresh_contiguous() would update these flags to track the tensor memory format information. APIs such as is_contiguous(), is_strides_like_channels_last(), is_strides_like_channels_last_3d(), etc. could work based on these flags.
To avoide to introudce extra bits into TensorImpl structure, don't define such as
bool is_channels_last_1d_ : 1; bool is_channels_last_1d_contiguous_ : 1;in TensorImpl structure for ChannelsLast1d, which would not introudce any overhead for key function refresh_contiguous(). If the associated APIs(e.g.: is_contiguous()) demand the memory format information for ChannelsLast1d, we do it as below:Regarding 4: If users don't use ChannelsLast1d, they don't need do anything. If user want to use ChannelsLast1d, they can get the same user experience as ChannelsLast(2d) and ChannelsLast3d.
Proposal 2:
Although proposal 1 doesn't introduce extra bits in TensorImpl structure and any overhead for such as function refresh_continguous(), proposal 1 implementation is not smooth and elegant as ChannelsLast(2d) or ChannelsLast3d.
Besides the overhead for refresh_continguous() is almost negligible. I'll explain it later. First of all, let's focus on proposal 2 implementation.
The details are as follows:
Regarding 1: Users still use it as below:
Regarding 2 : only add 2 extra bits in TensorImpl structure as below:
Regarding 3: The key code snippet is as below:
Let's carefully look at refresh_contiguous(). New added functions compute_channels_last_contiguous_1d() and compute_strides_like_channels_last_1d() for channels last 1d would not introduce additional computation for channels last 2d(4D tensor) or channels last 3d(5D tensor) in refresh_contiguous(). E.g.: suppose that we create a new 5D tensor to trigger refresh_contiguous() function, the call tree is as below:
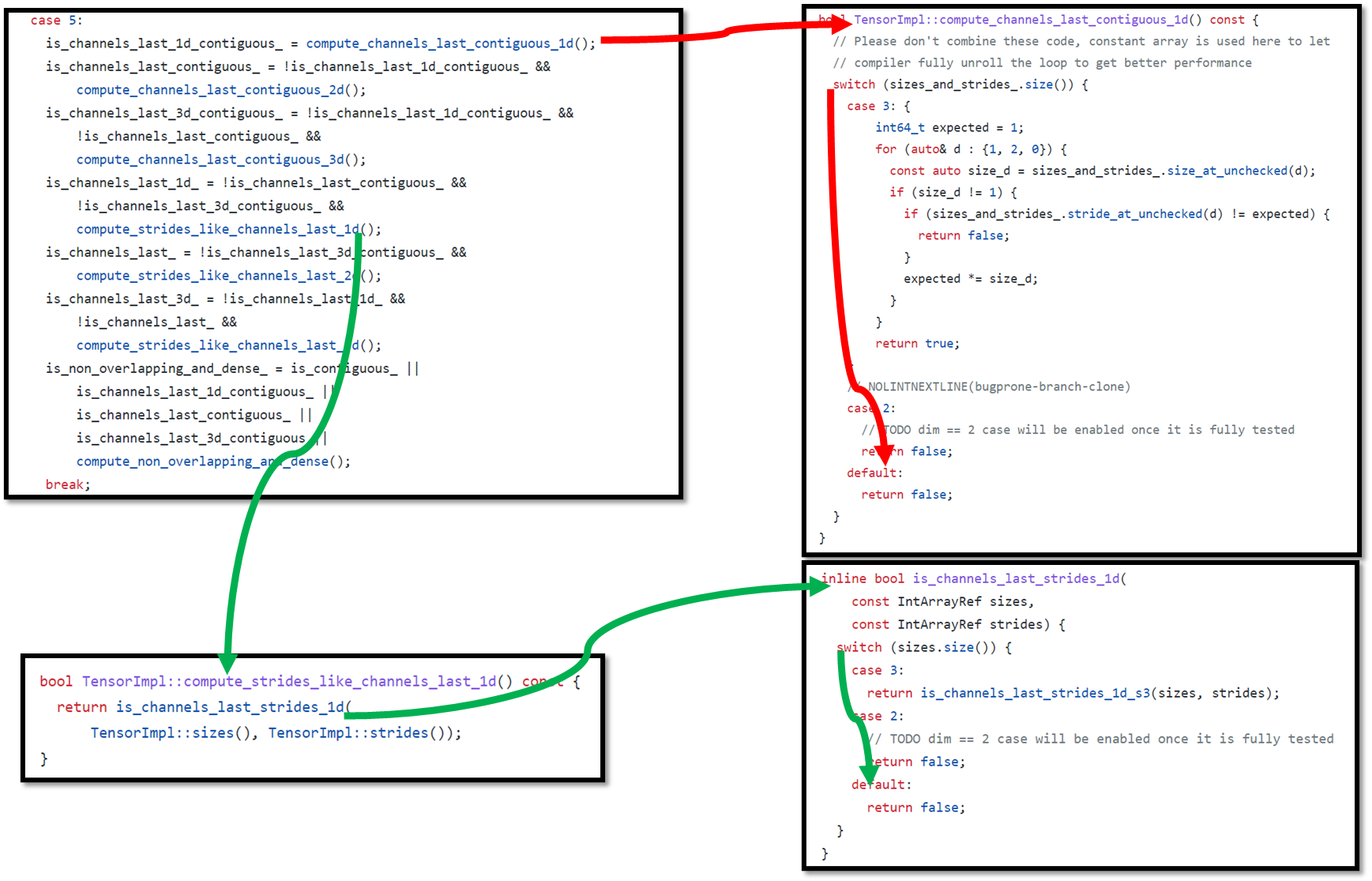
Although we call compute_channels_last_contiguous_1d() in refresh_contiguous for 5D tensor, it would not do any additional computation and directly return false(illustrated by red arrow above. dim == 5 would fall into default pass);
Although we call compute_strides_like_channels_last_1d() in refresh_contiguous for 5D tensor, it would not do any additional computation and directly return false (illustrated by green arrow above. dim == 5 would fall into default pass).
Regarding 4: If users don't use ChannelsLast1d, they still don't need do anything. If user want to use ChannelsLast1d, they can get the same user experience as ChannelsLast(2d) and ChannelsLast3d.
The 2 proposals are compared in the table below:
**Metrics **
As is known, channels last format has better performance than channels first format for most of operators such as conv.
How we teach this
ChannelsLast1d will align to the usage habits of ChannelsLast(2d) and ChannelsLast3d to provide consistent use experience as below, so we believe that there is no learning cost for users.
Alternatives
See Proposal 2.
Additional context
No response
cc @VitalyFedyunin @jamesr66a
The text was updated successfully, but these errors were encountered: