The Decade of Deep Learning #1151
Comments
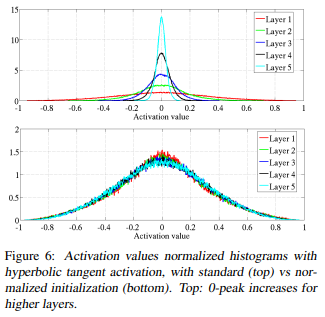
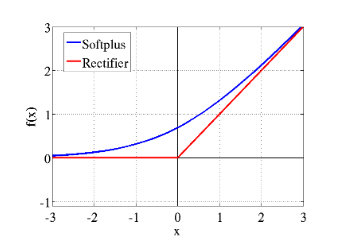
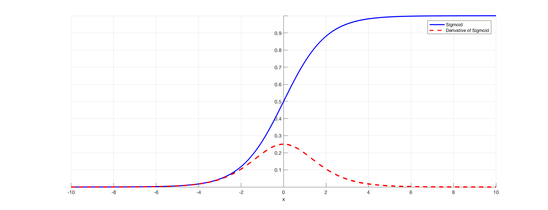
The Decade of Deep Learning by @nabla_thetaCreated: 2019-12-31 Modified: 2020-01-04 The Decade of Deep LearningAs the 2010’s draw to a close, it’s worth taking a look back at the monumental progress that has been made in Deep Learning in this decade.[1] Driven by the development of ever-more powerful compute and the increased availability of big data, Deep Learning has successfully tackled many previously intractable problems, especially in Computer Vision and Natural Language Processing. Deep Learning has also begun to see real-world application everywhere around us, from the high-impact to the frivolous, from autonomous vehicles and medical imaging to virtual assistants and deepfakes. This post is an overview of some the most influential Deep Learning papers of the last decade. My hope is to provide a jumping-off point into many disparate areas of Deep Learning by providing succinct and dense summaries that go slightly deeper than a surface level exposition, with many references to the relevant resources. Given the nature of research, assigning credit is very difficult—the same ideas are pursued by many simultaneously, and the most influential paper is often neither the first nor the best. I try my best to tiptoe the line between influence and first/best works by listing the most influential papers as main entries and the other relevant papers that precede or improve upon the main entry as honorable mentions.[2] Of course, as such a list will always be subjective, this is not meant to be final, exhaustive, or authoritative. If you feel that the ordering, omission, or description of any paper is incorrect, please let me know—I would be more than glad to improve this list by making it more complete and accurate. 2010 ======== Understanding the difficulty of training deep feedforward neural networks (7446 citations)This paper explored some problems with deep networks, especially surrounding random initialization of weights. This paper also noticed issues with sigmoid and hyperbolic tangent activations, and proposed an alternative, SoftSign, which is a sigmoidal activation function with smoother asymptopes[3]. The most lasting contribution of this paper, however, is in initialization. When initialized with normally-distributed weights, it is easy for values in the network to explode or vanish, preventing training. Assuming the values from the previous layer are i.i.d Gaussians, adding them adds their variances, and thus the variance should be scaled down proportionally to the number of inputs to keep the output zero mean and unit variance. The same logic holds in reverse (i.e with the number of outputs) for the gradients. The Xavier initialization introduced in this paper is a compromise between the two, initializing weights from a Gaussian with variance 2nin+nout\frac{2}{n_{in} + n_{out}}nin+nout2, where ninn_{in}nin and noutn_{out}nout are the numbers of neurons in the previous and next layers, respectively. A subsequent paper in 2015, Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, introduced Kaiming initialization, which is an improved version of Xavier initialization that accounts for the effects of ReLU activations.[4] 2011 ======== Deep Sparse Rectifier Neural Networks (4071 citations)Most neural networks, from the earliest MLPs up until many networks toward the middle of the decade, used sigmoids for intermediate activations. Sigmoids (most commonly the logistic and hyperbolic tangent functions) have the advantages of being differentiable everywhere and having a bounded output. They also provide a satisfying analogy to biological neurons’ all-or-none law. However, as the derivative of sigmoid functions decays quickly away from zero, the gradient is often diminished rapidly as more layers are added. This is known as the vanishing gradient problem and is one of the reasons that networks were difficult to scale depthwise. This paper found that using ReLUs helped solve the vanishing gradient problem and paved the way for deeper networks. Despite this, however, ReLUs still have some flaws: they are non-differentiable at zero[5], they can grow unbounded, and neurons could “die” and become inactive due to the saturated half of the activation. Since 2011, many improved activations have been proposed to solve the problem, but vanilla ReLUs are still competitive, as the efficacy of many new activations has been under question. The paper Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit (2000) is generally credited to be the first paper to establish the biological plausibility of the ReLU, and What is the Best Multi-Stage Architecture for Object Recognition? (2009) was the earliest paper that I was able to find that explored using the ReLU (referred to as the positive part in this paper) for neural networks. Honorable Mentions
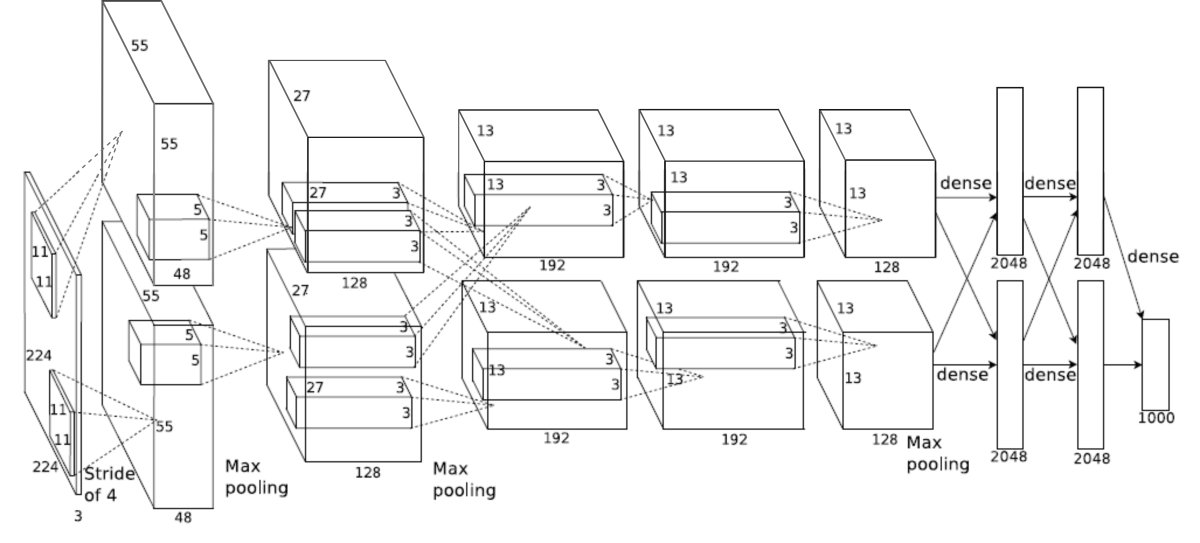
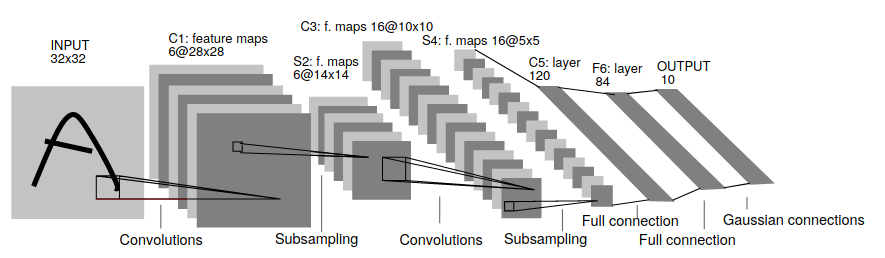
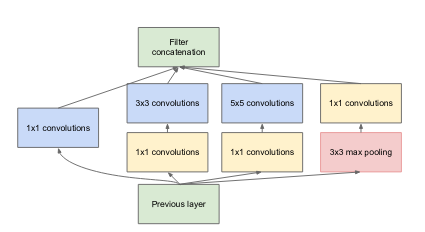
2012 ======== ImageNet Classification with Deep Convolutional Neural Networks (52025 citations)AlexNet is an 8 layer Convolutional Neural Network using the ReLU activation function and 60 million parameters. The crucial contribution of AlexNet was demonstrating the power of deeper networks, as its architecture was, in essence, a deeper version of previous networks (i.e LeNet). The AlexNet paper is generally recognized as the paper that sparked the field of Deep Learning. AlexNet was also one of the first networks to leverage the massively parallel processing power of GPUs to train much deeper convolutional networks than before. The result was astounding, lowering the error rate on ImageNet from 26.2% to 15.3%, and beating every other contender in ILSVRC 2012 by a wide margin. This massive improvement in error attracted a lot of attention to the field of Deep Learning, and made the AlexNet paper the most cited papers in Deep Learning. Honorable Mentions:
2013 ======== Distributed Representations of Words and Phrases and their Compositionality (16923 citations)This paper (and the slightly earlier Efficient Estimation of Word Representations in Vector Space by the same authors) introduced word2vec, which became the dominant way to encode text for Deep Learning NLP models. It is based on the idea that words which appear in similar contexts likely have similar meanings, and thus can be used to embed words into vectors (hence the name) to be used downstream in other models. Word2vec, in particular, trains a network to predict the context around a word given the word itself, and then extracting the latent vector from the network.[8] Honorable Mentions
Playing Atari with Deep Reinforcement Learning (3251 citations)The results of DeepMind’s Atari DQN kickstarted the field of Deep Reinforcement Learning. Reinforcement Learning was previously used mostly on low-dimensional environments such as gridworlds, and was difficult to apply to more complex environments. Atari was the first successful application of reinforcement learning to a high-dimensional environment, which brought Reinforcement Learning from obscurity to an important subfield of AI. The paper uses Deep Q-Learning in particular, a form of value-based Reinforcement Learning. Value-based means that the goal is to learn how much reward the agent can expect to obtain at each state (or, in the case of Q-learning, each state-action pair) by following the policy implicitly defined by the Q-value function. This policy used in this paper is the ϵ\epsilonϵ-greedy policy—it takes the greedy (highest-scored) action as estimated by the Q-function with probability 1−ϵ1 - \epsilon1−ϵ and a completely random action with probability ϵ\epsilonϵ. This is to allow for exploration of the state space. The objective for training the Q-value function is derived from the Bellman equation, which decomposes the Q-value function into the current reward plus the maximum (discounted) Q-value of the next state (Q(s,a)=r+γmaxa′Q(s′,a′)Q(s, a) = r + \gamma \max_{a'} Q(s', a')Q(s,a)=r+γmaxa′Q(s′,a′)), which lets us update the Q-value function using its own estimates. This technique of updating the value function based on the current reward plus future value function is known in general as Temporal Difference learning. Honorable Mentions
2014 ======== Generative Adversarial Networks (13917 citations)Generative Adversarial Networks have been successful in no small part due to the stunning visuals they produce. Relying on a minimax game between a Generator and a Discriminator, GANs are able to model complex, high dimensional distributions (most often, images[9]). The objective of the Generator is to minimize the log-probability log(1−D(G(z)))log(1 - D(G(\bold{z})))log(1−D(G(z))) of the Discriminator being correct on fake samples, while the Discriminator’s goal is to minimize its classification error logD(x)+log(1−D(G(z)))log D(x) + log(1 - D(G(\bold{z})))logD(x)+log(1−D(G(z))) between real and fake samples.
In practice, the Generator is often trained to maximize the log-probability D(G(z))D(G(\bold{z}))D(G(z)) of the Discriminator being incorrect (See: NIPS 2016 Tutorial: Generative Adversarial Networks, section 3.2.3). This minor change reduces gradient saturating and improves training stability. Honorable Mentions:
Neural Machine Translation by Jointly Learning to Align and Translate (9882 citations)This paper introduced the idea of attention—instead of compressing information down into a latent space in an RNN, one could instead keep the entire context in memory, then allowing every element of the output to attend to every element of the input, using O(nm)\mathcal{O}(nm)O(nm) operations. Despite requiring quadratically-increasing compute[12], attention is far more performant than fixed-state RNNs and have become an integral part of not only textual tasks like translation and language modeling, but also percolating to models as distant as GANs, too. Adam: A Method for Stochastic Optimization (34082 citations)Adam has become a very popular adaptive optimizer due to its ease of tuning. Adam is based on the idea of adapting separate learning rates for each parameter. While more recent papers have cast doubt on the performance of Adam, it remains one of the most popular optimization algorithms in Deep Learning. Honorable Mentions
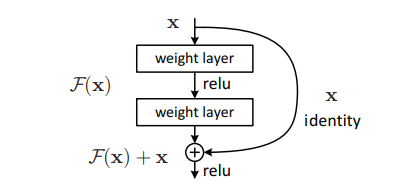
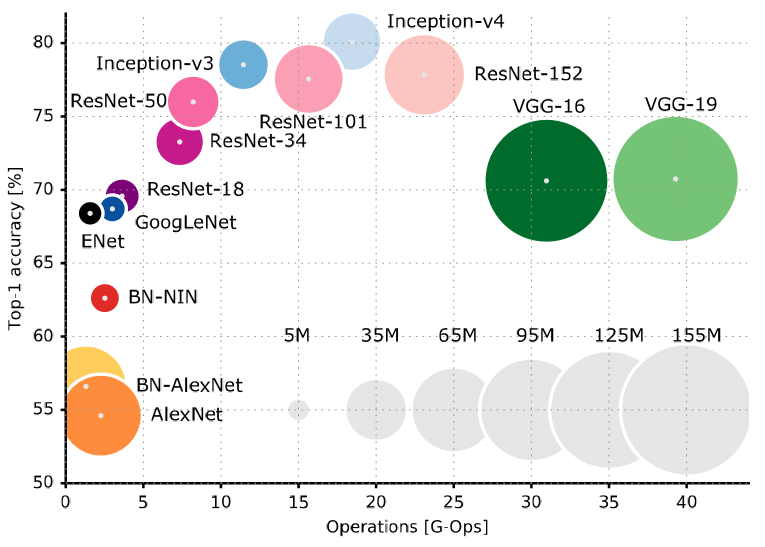
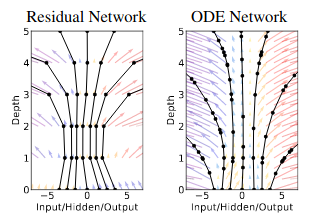
2015 ======== Deep Residual Learning for Image Recognition (34635 citations)
Honorable Mentions:
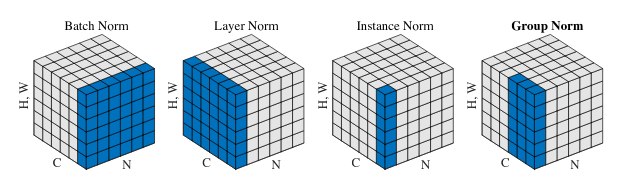
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (14384 citations)Batch normalization is another mainstay of nearly all neural networks today. Batch norm is based on another simple but powerful idea: Keeping mean and variance statistics during training, and using that to scale activations to zero mean and unit variance. The exact reasons for the effectiveness of Batch norm are disputed, but it is undeniably effective empirically.[15] Honorable Mentions
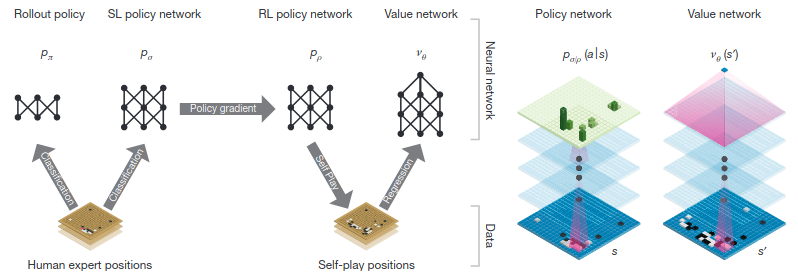
2016 ======== Mastering the game of Go with deep neural networks and tree search (6310 citations)After the defeat of Kasparov by Deep Blue, Go became the next goal for the AI community, thanks to its properties: a much larger state space than chess and a greater reliance on intuition among human players. Up until AlphaGo, the most successful Go systems such as Crazy Stone and Zen were a combination of a Monte-Carlo tree search with many handcrafted heuristics to guide the tree search. Judging from the progress of these systems, defeating human grandmasters was considered at the time to be many years away. Although previous attempts at applying neural networks to Go do exist, none have reached the level of success of AlphaGo, which combines many of these previous techniques with big compute. Specifically, AlphaGo consists of a policy network and a value network that narrow the search tree and allow for truncation of the search tree, respectively. These networks were first trained with standard Supervised Learning and then further tuned with Reinforcement Learning. AlphaGo has made, of all the advancements listed here, possibly the biggest impact on the public mind, with an estimated 100 million people globally (especially from China, Japan, and Korea, where Go is very popular) tuning in to the AlphaGo vs. Lee Sedol match. The games from this match and the other later AlphaGo Zero matches have influenced human strategy in Go. One example of a very influential move by AlphaGo is the 37th move in the second game; AlphaGo played very unconventionally, baffling many analysts. This move later turned out to be crucial in securing the win for AlphaGo later.[16] Honorable Mentions
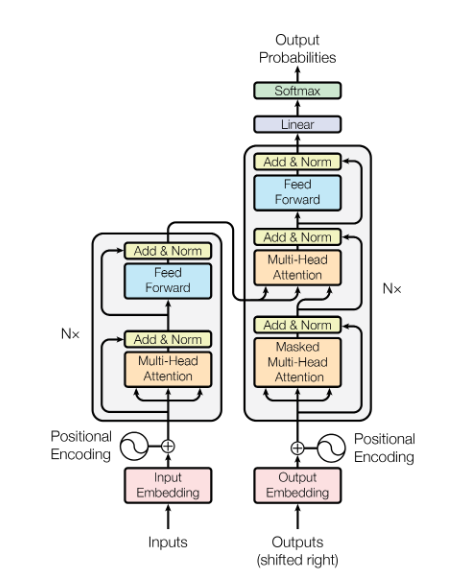
2017 ======== Attention Is All You Need (5059 citations)
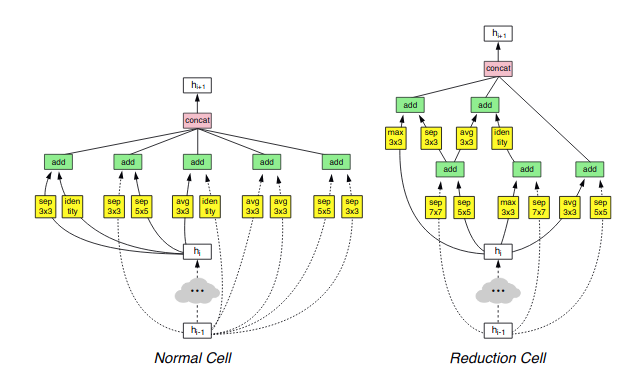
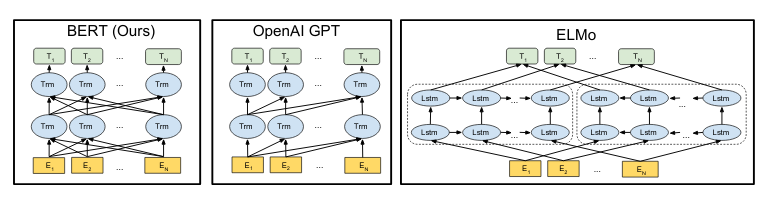
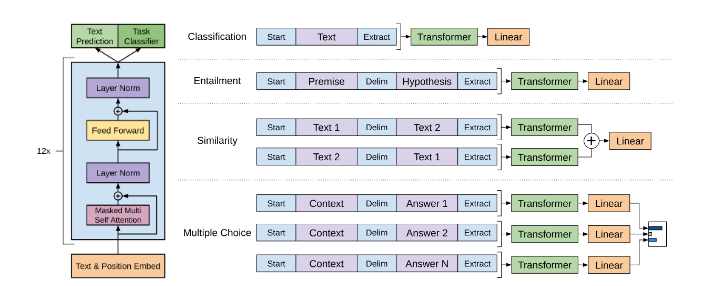
Neural Architecture Search with Reinforcement Learning (1186 citations)Neural Architecture Search has become common practice in the field for squeezing every drop of performance out of networks. Instead of designing architectures painstakingly by hand, NAS allows this process to be automated. In this paper, a controller network is trained using RL[17] to produce performant network architectures, which has created many SOTA networks. Other approaches, such as Regularized Evolution for Image Classifier Architecture Search (AmoebaNet), use evolutionary algorithms instead. 2018 ======== BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (3025 citations)BERT is a bidirectional contextual text embedding model. Like word2vec, it is based on assigning each word (or, rather, sub-word token) a vector. However, these vectors in BERT are contextual, allowing homographs to be properly distinguished. Furthermore, BERT is deeply bidirectional, with each latent vector in each layer depending on all latent vectors from the previous layer, unlike earlier works like GPT (which is forward-only) and ELMo (which has separate forward and backward LMs that are only combined at the end). In unidirectional LMs like GPT, the model is trained to predict the next token at each time step, which works because the states at each time step can only depend on previous states. (With ELMo, both the forward and backward models are trained independently in this way and optimized jointly.) However, in a deeply bidirectional network, a state StLS^L_tStL for step ttt and layer LLL must depend on all states St′L−1S^{L-1}_{t'}St′L−1, each of which could, in turn, depend on StL−2S^{L-2}_{t}StL−2, allowing the network to “cheat” on the language modeling. To solve this problem, BERT uses a reconstruction task to recover masked tokens, which are never seen by the network.[18] Honorable MentionsSince the publication of BERT, there has been an explosion of other transformer-based language models. As they are all quite similar, I will list some of them here instead of as their own entries. Of course, since this field is so fast-moving, it is impossible to be comprehensive; moreover, many of these papers have yet to stand the test of time, and so it is difficult to conclude which papers will have the most impact.
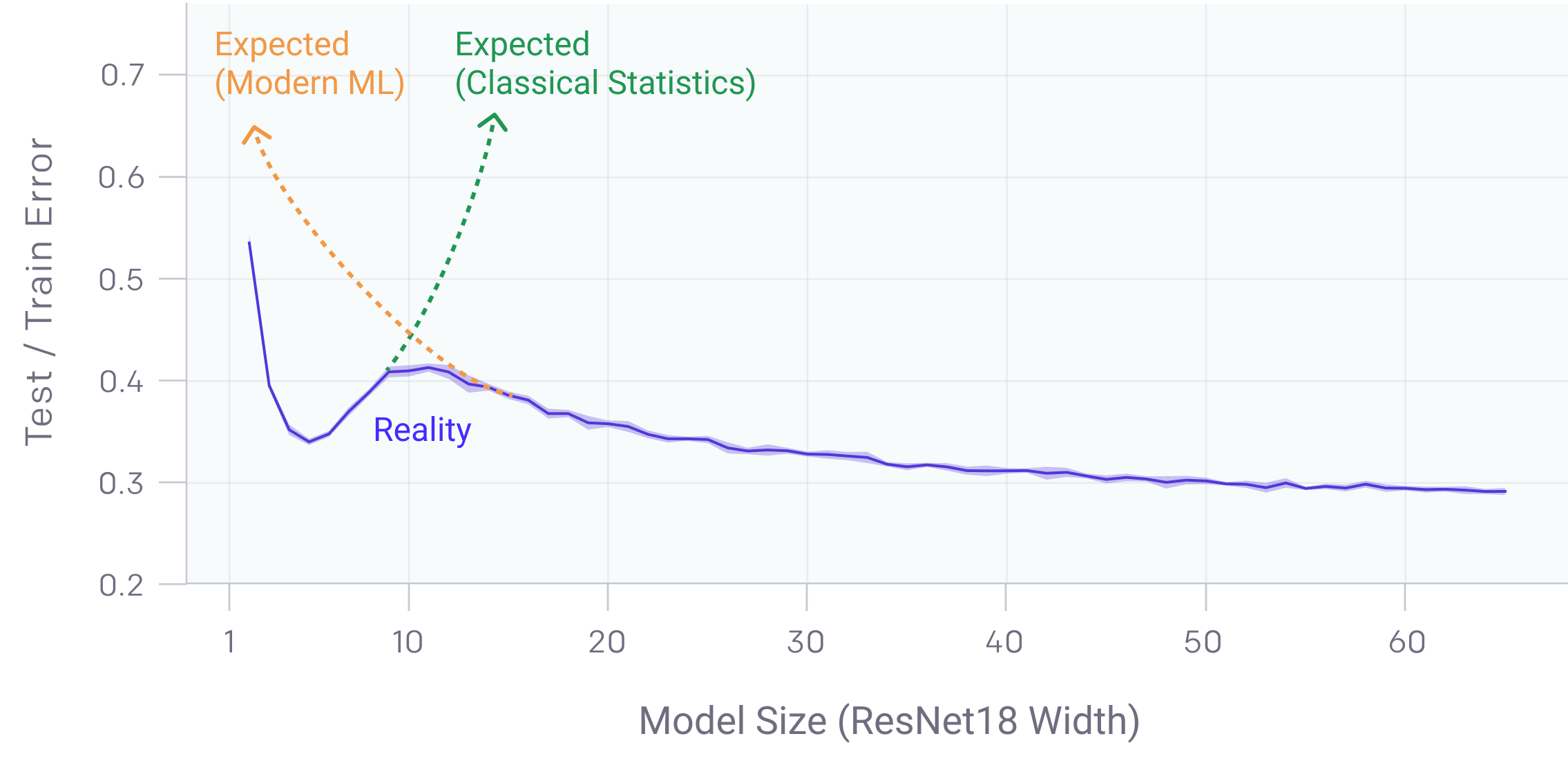
2019 ======== Deep Double Descent: Where Bigger Models and More Data HurtThe phenomenon of (Deep) Double Descent explored in this paper runs contrary to popular wisdom in both classical machine learning and modern Deep Learning. In classical machine learning, model complexity follows the bias-variance tradeoff. Too weak a model is unable to fully capture the structure of the data, while too powerful a model can overfit and capture spurious patterns that don’t generalize. Because of this, in classical machine learning it is expected that test error will decrease as models get larger, but then start to increase again once the models begin to overfit. In practice, however, in Deep Learning, models are very often massively overparameterized and yet still seem to improve on test performance with larger models. This conflict is the motivation behind (deep) double descent. Deep Double Descent expanded on the original Double Descent paper by Belkin et al. by showing empirically the effects of Double Descent on a much wider variety of Deep Learning models, and its applicability to not only the model size but also training time and dataset size.
As the capacity of the models approaches the “interpolation threshold,” the demarcation between the classical ML and Deep Learning regimes, it becomes possible for gradient descent to find models that achieve near-zero error, which are likely to be overfit. However, as the model capacity is increased even further, the number of different models that can achieve zero training error increases, and the likelihood that some of them fit the data smoothly (i.e without overfitting) increases. Double Descent posits that gradient descent is more likely to find these smoother zero-training-error networks, which generalize well despite being overparameterized.[20] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Another paper about the training characteristics of deep neural networks was the Lottery Ticket Hypothesis paper. The Lottery Ticket Hypothesis asserts that most of a network’s performance comes from a certain subnetwork due to a lucky initialization (hence the name, “lottery ticket,” to refer to these subnetworks), and that larger networks are more performant because of a higher chance of lottery tickets occurring. This not only allows us to prune the irrelevant weights (which is already well established in the literature), but also to retrain from scratch using only the “lottery ticket” weights, which, surprisingly, obtains close to the original loss. Conclusion and Future ProspectsThe past decade has marked an incredibly fast-paced and innovative period in the history of AI, driven by the start of the Deep Learning Revolution—the Renaissance of gradient-based networks. Spurred in large part by the ever increasing computing power available, neural networks have gotten much larger and thus more powerful, displacing traditional AI techniques across the board, from Computer Vision to Natural Language Processing. Neural networks do have their weaknesses though: they require a large amount of data to train, have inexplicable failure modes, and cannot generalize beyond individual tasks. As the limits of Deep Learning with respect to advancing AI have begun to become apparent thanks to the massive improvements in the field, attention has shifted towards a deeper understanding of Deep Learning. The next decade is likely to be marked by an increased understanding of many of the empirical characteristics of neural networks observed today. Personally, I am optimistic about the prospects of AI; Deep Learning is an invaluable tool in the toolkit of AI, that brings us yet another step closer to understanding intelligence. Here’s to a fruitful 2020’s. To cite:1 @ article{lg2020dldecade,
[Newer Multidisk Filesystems: A Comparison ](https://bmk.sh/2020/01/31/Multidisk-Filesystems-A-Comparison/)[**Older** Converting HuggingFace GPT-2 Models to Tensorflow 1.x ](https://bmk.sh/2019/11/09/Converting-HuggingFace-GPT2-Models-to-Tensorflow-1/) |





As the 2010’s draw to a close, it’s worth taking a look back at the monumental progress that has been made in Deep Learning in this decade.
Tags: deep_learning
via Pocket https://ift.tt/3rftNq9 original site
July 12, 2021 at 02:07PM
The text was updated successfully, but these errors were encountered: