This plugin introduces the concept of sharded queues for RabbitMQ. Sharding is performed by exchanges, that is, messages will be partitioned across "shard" queues by one exchange that we should define as sharded. The machinery used behind the scenes implies defining an exchange that will partition, or shard messages across queues. The partitioning will be done automatically for you, i.e: once you define an exchange as sharded, then the supporting queues will be automatically created on every cluster node and messages will be sharded across them.
This plugin is reasonably mature and known to have production users.
The following graphic depicts how the plugin works from the standpoint of a publisher and a consumer:
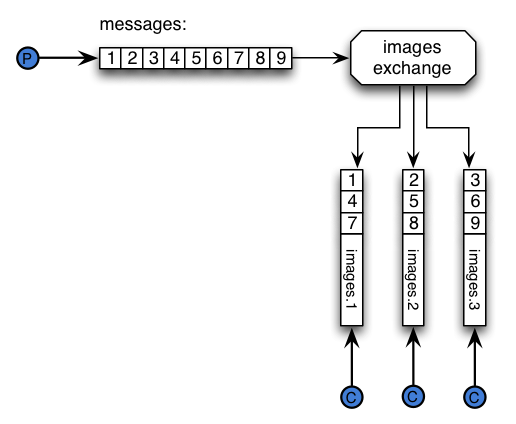
On the picture above the producer publishes a series of messages, those messages get partitioned to different queues, and then our consumer get messages from one of those queues. Therefore if there is a partition with 3 queues, it is assumed that there are at least 3 consumers to get all the messages from those queues.
Queues in RabbitMQ are units of concurrency (and, if there are enough cores available, parallelism). This plugin makes it possible to have a single logical queue that is partitioned into multiple regular queues ("shards"). This trades off total ordering on the logical queue for gains in parallelism.
Message distribution between shards (partitioning) is achieved with a custom exchange type that distributes messages by applying a hashing function to the routing key.
Sharding performed by this plugin makes sense for non-replicated classic queues only.
Combining sharding with a replicated queue type, e.g. quorum queues or (deprecated) mirrored classic queues will lose most or all of the benefits offered by this plugin.
Do not use this plugin with quorum queues. Avoid classic mirrored queues in general.
The exchanges that ship by default with RabbitMQ work in an "all or nothing" fashion, i.e: if a routing key matches a set of queues bound to the exchange, then RabbitMQ will route the message to all the queues in that set. For this plugin to work it is necessary to route messages to an exchange that would partition messages, so they are routed to at most one queue (a subset).
The plugin provides a new exchange type, "x-modulus-hash", that will use
a hashing function to partition messages routed to a logical queue
across a number of regular queues (shards).
The "x-modulus-hash" exchange will hash the routing key used to
publish the message and then it will apply a Hash mod N to pick the
queue where to route the message, where N is the number of queues
bound to the exchange. This exchange will completely ignore the
binding key used to bind the queue to the exchange.
There are other exchanges with similar behaviour:
the Consistent Hash Exchange or the Random Exchange.
Those were designed with regular queues in mind, not this plugin, so "x-modulus-hash"
is highly recommended.
If message partitioning is the only feature necessary and the automatic scaling of the number of shards (covered below) is not needed or desired, consider using Consistent Hash Exchange instead of this plugin.
One of the main properties of this plugin is that when a new node
is added to the RabbitMQ cluster, then the plugin will automatically create
more shards on the new node. Say there is a shard with 4 queues on
node a and node b just joined the cluster. The plugin will
automatically create 4 queues on node b and "join" them to the shard
partition. Already delivered messages will not be rebalanced but
newly arriving messages will be partitioned to the new queues.
While the plugin creates a bunch of "shard" queues behind the scenes, the idea is that those queues act like a big logical queue where you consume messages from it. Total ordering of messages between shards is not defined.
An example should illustrate this better: let's say you declared the exchange images to be a sharded exchange. Then RabbitMQ creates several "shard" queues behind the scenes:
- shard: - nodename images 1
- shard: - nodename images 2
- shard: - nodename images 3
- shard: - nodename images 4.
To consume from a sharded queue, register a consumer on the "images" pseudo-queue
using the basic.consume method. RabbitMQ will attach the consumer to a shard
behind the scenes. Note that consumers must not declare a queue with the same
name as the sharded pseudo-queue prior to consuming.
TL;DR: if you have a shard called images, then you can directly consume from a queue called images.
How does it work? The plugin will chose the queue from the shard with the least amount of consumers, provided the queue contents are local to the broker you are connected to.
NOTE: there's a small race condition between RabbitMQ updating the
queue's internal stats about consumers and when clients issue
basic.consume commands. The problem with this is that if your
client issue many basic.consume commands without too much time in
between, it might happen that the plugin assigns the consumers to
queues in an uneven way.
Shard queues declaration by this plugin will ignore queue master locator policy, if any.
As with many data distribution approaches based on a hashing function, even distribution between shards depends on the distribution (variability) of inputs, that is, routing keys. In other words the larger the set of routing keys is, the more even will message distribution between shareds be. If all messages had the same routing key, they would all end up on the same shard.
This plugin ships with modern versions of RabbitMQ. Like all plugins, it must be enabled before it can be used:
# this might require sudo
rabbitmq-plugins enable rabbitmq_shardingOnce the plugin is installed you can define an exchange as sharded by
setting up a policy that matches the exchange name. For example if we
have the exchange called shard.images, we could define the following
policy to shard it:
$CTL set_policy images-shard "^shard.images$" '{"shards-per-node": 2, "routing-key": "1234"}'Note, on Windows, above command will be like this:
rabbitmqctl set_policy images-shard "^shard.images$" '{\"shards-per-node\": 2, \"routing-key\": \"1234\"}'
This will create 2 sharded queues per node in the cluster, and will
bind those queues using the "1234" routing key.
In the example above we use the routing key 1234 when defining the
policy. This means that the underlying exchanges used for sharding
will bind the sharded queues to the exchange using the 1234 routing
key specified above. This means that for a direct exchange, _only
messages that are published with the routing key 1234 will be routed
to the sharded queues. If you decide to use a fanout exchange for
sharding, then the 1234 routing key, while used during binding, will
be ignored by the exchange. If you use the "x-modulus-hash"
exchange, then the routing key will be ignored as well. So depending
on the exchange you use, will be the effect the routing-key policy
definition has while routing messages.
The routing-key policy definition is optional.
Get the RabbitMQ Public Umbrella ready as explained in the RabbitMQ Plugin Development Guide.
Move to the umbrella folder an then run the following commands, to fetch dependencies:
make up
cd deps/rabbitmq-sharding
make distSee the LICENSE file.
Some information about how the plugin affects message ordering and some other details can be found in the file README.extra.md