- What is this?
- Introduction
- Bank sample
- How it works?
- Annotations
- Consistency
- Performance and Scalability
- Determinism
- Limitations
- FAQ and more
- Status and Conclusion
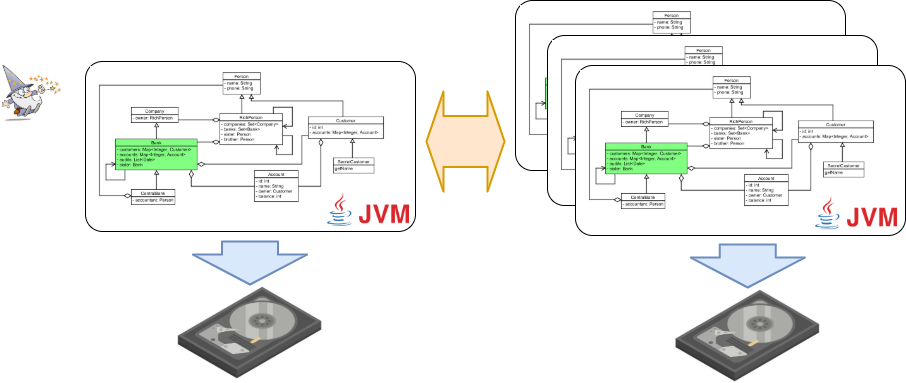
This is a proof of concept library which provides POJOs (Plain Old Java Objects) replication and persistence capabilities almost transparently.
Chainvayler requires neither implementing special interfaces nor extending from special classes nor a backing relational database.
Only some @Annotations and conforming a few rules is necessary. Chainvayler does its magic by instrumentation (injecting bytecode) of Java classes.
Either replication or persistence can be disabled independently. If replication is disabled, you will have locally persisted POJOs. If persistence is disabled, you will have your POJOs replicated over JVMs possibly spreading over multiple nodes. If both replication and persistence is disabled, well you will only have Chainvayler's overhead ;)
I've found the idea really promising, so went ahead and made a PoC implementation.
Sounds too good to be true? Well, keep reading... ;)
As mentioned, Chainvayler only requires some @Annotations and conforming a few rules.
Here is a quick sample:
@Chained
class Library {
final Map<Integer, Book> books = new HashMap<>();
int lastBookId = 1;
@Modification
void addBook(Book book) {
book.setId(lastBookId++);
books.put(book.getId(), book);
}
}Quite a Plain Old Java Object, isn't it? Run the Chainvayler compiler after javac and then to get a reference to a chained instance:
Library library = Chainvayler.create(Library.class);or this variant to configure options:
Library library = Chainvayler.create(Library.class, config);Now, add as many books as you want to your library, they will be automagically persisted and replicated to other JVMs. Kill your program any time, when you restart it, the previously added books will be in your library.
Note, the call to Chainvayler.create(..) is only required for the root of object graph. All other objects are created in regular ways, either with the new operator or via factories, builders whatever. As it is, Chainvayler is quite flexible, other objects may be other instances of root class, subclasses/superclasses of it, or instances of a completely different class hierarchy.
@Chained annotation marks the classes which will be managed by Chainvayler and @Modification annotation marks the methods in chained classes which modifies the data (class variables).
Chainvayler comes with a Bank sample, for both demonstration and testing purposes.
Below is the class diagram of the Bank sample:
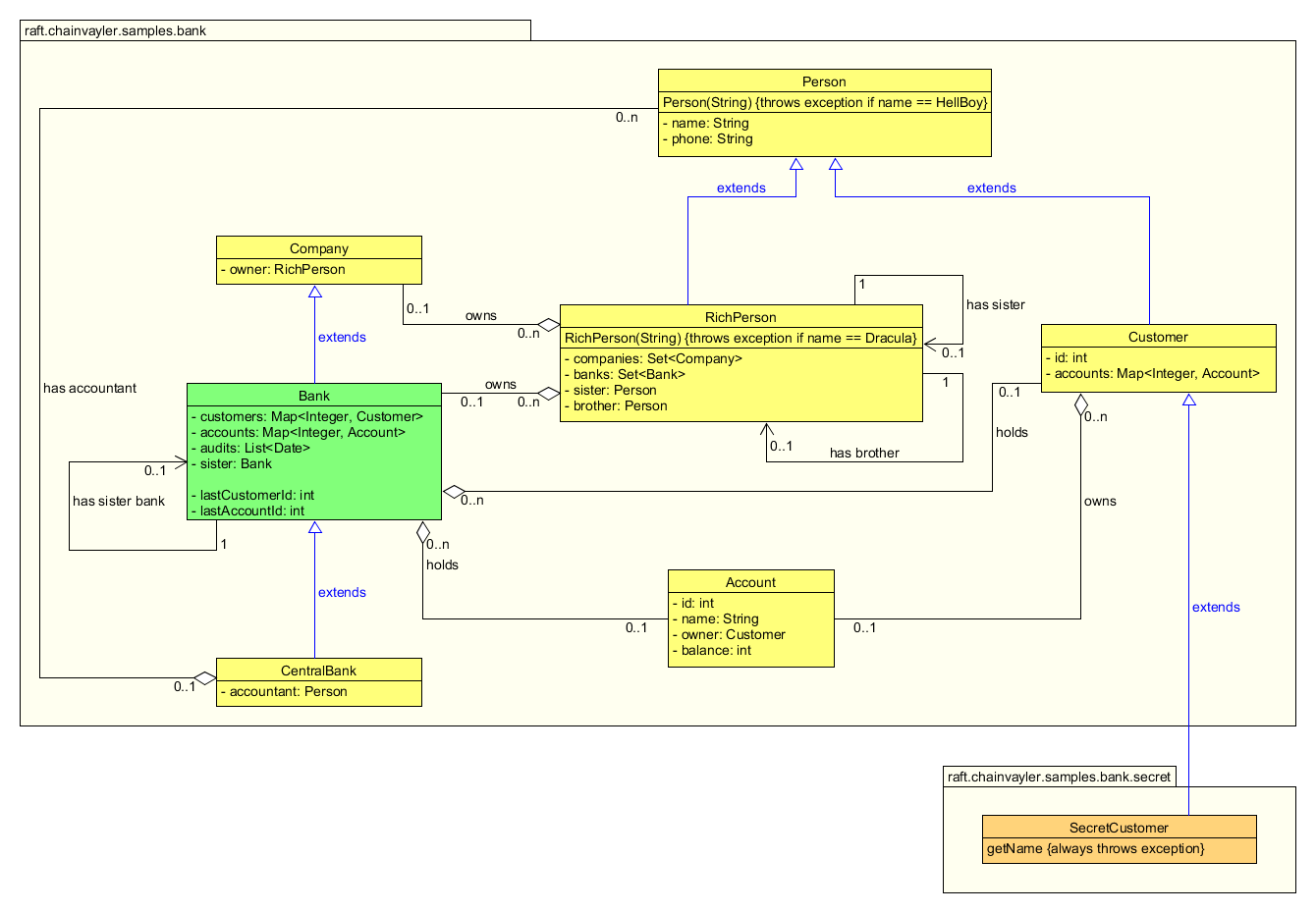
Nothing much fancy here. Apparently this is a toy diagram for a real banking application, but hopefully good enough to demonstrate Chainvayler's capabilities.
Bank class is the root class of this object graph. It's used to get a chained instance of the object graph via Chainvayler. Every object reachable directly or indirectly from the root Bank object will be chained (persisted/replicated). Notice Bank class has super and sub classes and even has a reference to another Bank object.
For the sake of brevity, I've skipped the class methods in the diagram but included a few to demonstrate Chainvayler's capabilities regarding some edge cases:
- Person and RichPerson constructors throw an exception if name has a special value
- SecretCustomer throws an exception whenever getName is called
- SecretCustomer resides in a different package, I will tell in a bit what it demonstrates
Note: I tried to cover all the possible edge cases. If you notice a case which is not covered, please create an issue.
There is also an emulated Bank sample where the Chainvayler injected bytecode is manually added to demonstrate what is going on.
The easiest way to see Chainvayler in action is to run the Bank sample in Kubernetes via provided Helm charts.
In Chainvayler/bank-sample folder, run the following command:
helm install chainvayler-sample kube/chainvayler-bank-sample/ This will by default create 3 writer pods and the watcher application peer-stats to follow the process. Any writer or reader pods will register themselves to peer-stats pod via RMI and you can follow the process via peer-stats pod's logs:
kubectl logs chainvayler-peer-stats-<ID> --followThe output will be similar to below (will be updated every 5 seconds):
created RMI registry
bound PeerManager to registry
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
------------------------------------------------------------------------------------------------------------------------
registered peer, count: 1
registered peer, count: 2
registered peer, count: 3
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
false false -1 1 0.05 0 0.00 0 0.00
false false 4 1 0.05 0 0.00 0 0.00
true false 4 1 40.00 0 0.00 0 0.00
------------------------------------------------------------------------------------------------------------------------
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
true false 15154 19607 3891.25 6418 1273.41 0 0.00
true false 15161 19624 3897.52 6427 1276.21 0 0.00
true false 15184 19644 3893.76 6782 1344.43 0 0.00
------------------------------------------------------------------------------------------------------------------------
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
true false 39019 45812 4555.33 14908 1482.35 0 0.00
true false 39021 45811 4556.50 14922 1484.19 0 0.00
true false 39049 45827 4553.56 15986 1588.28 0 0.00
------------------------------------------------------------------------------------------------------------------------
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
true false 69130 77516 5141.67 25268 1675.89 0 0.00
true false 69143 77547 5144.76 25216 1672.93 0 0.00
true false 69146 77547 5141.35 27053 1793.49 0 0.00
------------------------------------------------------------------------------------------------------------------------
-- started | completed | pool size | tx count | tx/second | own tx count | own tx/sec | read count | reads/sec --
true true 84774 94390 5249.50 32033 1787.16 0 0.00
true true 84774 94390 5228.20 31971 1770.85 0 0.00
true true 84774 94390 5278.17 30385 1812.62 0 0.00
------------------------------------------------------------------------------------------------------------------------
stopped all readers
will compare results..
transaction counts are the same! 94390
--all banks are identical!!
pool sizes are same 84774 == 84774
pool sizes are same 84774 == 84774
all pool classes are the same
this pair looks identical
this pair looks identical
this pair looks identical
-- all pools are identical!!
average tx/second: 5251.96, own tx/second: 1790.21
So, what happened (with the default values) exactly is:
- We had launched 3 instances of Bank sample where replication is enabled and persistence is disabled
- They all registered themselves to
peer-statsapplication to provide some metrics - They started to make random write operations over their copy of the Bank with 5 threads
peer-statsapplication collected and printed their metrics every 5 seconds- After all writers are finished:
peer-statsgot the final copy of each one's Bank object and also Chainvayler's implemenation details, like transaction count and internal object pool- Compared each one of them against any other them
- Checked if they are completely identical
- Printed the final statistics
Welcome to Chainvayler world! You just witnessed a POJO graph is automagically and ~transparently replicated!
Feel free to try different settings: more writers, some readers, some writer-readers or more write actions. See the values.yaml file for all options.
For example, lets create additional 2 readers:
helm install chainvayler-sample kube/chainvayler-bank-sample/ --set replication.readerCount=2 --set load.actions=5000Increased the action count, so we will have more time until they are completed. Kill any pod any time, when restarted, they will retrieve the initial state and catch the others.
For example, from the logs after they are killed and restarted:
requesting initial transactions [2 - 23582]
received all initial transactions [2 - 23582], count: 23581
If you enable persistence and mount external disks with the flags --set persistence.enabled=true --set persistence.mountVolumes=true, when pods are killed and restarted, logs will be something like:
requesting initial transactions [40154 - 69079]
received all initial transactions [40154 - 69079], count: 28926
In this case, the first 40153 transactions are loaded from the disk, next 28926 are retrieved from the network.
Note: When replication is enabled, most of the time pods recover successfully after a kill/restart cycle. But still sometimes they cannot properly connect to Hazelcast cluster. Not sure if this is a misconfuguration by myself or Hazelcast is not bullet proof.
It's also possible to run the Bank sample without Kubernetes.
First, lets build and publish Chainvayler to local Maven repository:
# run in chainvayler/ folder
./gradlew clean build publishToMavenLocalThen build and instrument the Bank sample:
# run in bank-sample/ folder
./gradlew clean instrument buildYou will see the verbose output of Chainvayler compiler, the packages and classes it scanned, found Chained classes and their hierarchy and the modifications made to these classes.
Start the stats registry so we can watch the process:
# run in bank-sample/ folder
./gradlew runStatsRegistryIn another terminal, run the sample in persisted mode:
# run in bank-sample/ folder
./gradlew runPersistedWatch the process in stats registry terminal. When completed, kill and run both of them again. You will notice transaction count and pool size will not start from zero but continue from the numbers of previous run. This is because, transactions are loaded from the disk and the Bank object restored the state when it was killed last time. Do this a couple of times, the numbers will just continue from the last run.
By default, transactions are saved to persist/<Root class name> folder. So in our case this is persist/raft.chainvayler.samples.bank.Bank folder. Delete that folder and run the sample again, stats will start from scratch.
Start the stats registry so we can watch the process:
# run in bank-sample/ folder
./gradlew runStatsRegistryOpen at least 3 more terminals and run the sample in replicated mode:
# run in bank-sample/ folder
./gradlew runReplicatedHazelcast's CP subsystem requires at least 3 Raft nodes, so you should run at least 3 instances in replicated mode.
Since transactions are written to persist folder inside bank-sample folder, in persisted and replicated mode, you ned to run them in different folders.
Make 2 more copies of bank-sample folder:
# run in root folder
# first make sure we make a clean start
rm -r bank-sample/persist
cp -r bank-sample bank-sample-2
cp -r bank-sample bank-sample-3Start the stats registry so we can watch the process:
# run in bank-sample/ folder
./gradlew runStatsRegistryOpen 3 more terminals and run the sample in persisted and replicated mode:
# run in bank-sample/ folder
./gradlew runPersistedReplicated
# run in bank-sample-2/ folder
./gradlew runPersistedReplicated
# run in bank-sample-3/ folder
./gradlew runPersistedReplicatedTo explain how Chainvayler works, I need to first introduce Prevayler. It is a brilliant library to persist real POJOs. In short it says:
Encapsulate all changes to your data into Transaction classes and pass over me. I will write those transactions to disk and then execute on your data. When the program is restarted, I will execute those transactions in the exact same order on your data. Provided all such changes are deterministic, we will end up with the exact same state just before the program terminated last time.
This is simply a brilliant idea to persist POJOs. Actually, this is the exact same sequence databases store and re-execute transaction logs after a crash recovery.
However, the thing is Prevayler is a bit too verbose. You need to write Transaction classes for each operation that modifies your data. And it’s also a bit old fashioned considering today’s wonderful @Annotated Java world.
Here comes into scene Postvayler. It's the predecessor of Chainvayler, which was also a PoC project by myself for transperent POJO persistence.
Postvayler injects bytecode into (instruments) javac compiled @Chained classes such that every @Modification method in a @Chained class is modified to execute that method via Prevayler.
For example, the addBook(Book) method in the introduction sample becomes something like (omitting some details for readability):
void addBook(Book book) {
if (! there is Postvayler context) {
// no persistence, just proceed to original method
__postvayler_addBook(book);
return;
}
if (weAreInATransaction) {
// we are already encapsulated in a transaction, just proceed to original method
__postvayler_addBook(book);
return;
}
weAreInATransaction = true;
try {
prevayler.execute(new aTransactionDescribingThisMethodCall());
} finally {
weAreInATransaction = false;
}
}
// original addBook method is renamed to this
private void __postvayler_addBook(Book book) {
// the contents of the original addBook method
}As can been seen, if there is no Postvayler context around, the object bahaves like the original POJO with an ignorable overhead.
Constructors of @Chained classes are also instrumented to keep track of of them. They are pooled weekly so GC works as expected
Chainvayler takes the idea of Postvayler one step forward and replicates transactions among JVMs and executes them with the exact same order. So we end up with transparently replicated and persisted POJOs.
Before a transaction is committed locally, a global transaction ID is retrieved via Hazelcast's IAtomicLong data structure, which is basically a distributed version of Java's AtomicLong. Local JVM waits until all transactions up to retrieved transaction ID is committed and then commits its own transaction.
Hazelcast's IAtomicLong uses Raft consensus algorithm behind the scenes and is CP (consistent and partition tolerant) in regard to CAP theorem and so is Chainvayler.
Chainvayler uses Hazelcast's reliable ITopic data structure to replicate transactions among JVM's. ITopic is basically a pub/sub implementation of Hazelcast backed by Hazelcast's Ringbuffer.
ITopic is only used for replicating new transactions on the fly. When a new Chainvayler instance is joined to a cluster and doesn't have the transactions up to that point, it retrieves the missing transactions and a snaphot (if exists) from other peers in P2P manner, initializes itself and continues retrieving new transactions via ITopic.
Chainvayler also makes use of some ugly hacks to integrate with Prevayler. In particular, it uses reflection to access Prevayler internals as Prevayler was never meant to be extened this way. Obviously, this is not optimal, but please just remember this is just a PoC project ;) Possibly the way to go here is, enhancing Prevayler code base to allow this kind of extension.
Note, even if persistence is disabled, still Prevayler transactions are used behind the scenes. Only difference is, Prevayler is configured not to save transactions to disk.
Possibly, instrumentation of constructors are the most complicated part of Chainvayler and also Postvayler. So best to mention a bit.
First, as mentioned before, except the root object of the chained object graph, creating instances of chained classes are done in regular ways, either with the new oprerator, or via factories, builders whatever.
For example, here is a couple of code fragments from the Bank sample to create objects:
Bank other = new Bank();Customer customer = new Customer(<name>);Customer customer = bank.createCustomer(<name>);They look quite POJO way, right?
Actually many things are happening behind the scenes due to constructor instrumentation:
- First, if there is no Chainvayler context around, they act like a plain POJO. They do nothing special
- Otherwise, the created object gets a unique long id, which is guaranteed to be the same among all JVMs and the object is put to the local object pool with that id
- If necessary, a ConstructorTransaction is created and committed with the arguments passed to constructor.
A ConstructorTransaction is necessary only if:
- We are not already in a transaction (inside a
@Modificationmethod call or in another ConstructorTransaction)
- We are not already in a transaction (inside a
- If this is the local JVM, the JVM which created the object for the first time, it just gets back the reference of the object. All the rest works as plain POJO world.
- Otherwise, if this is due to a remote transaction (coming from another JVM) or a recovery transaction (JVM stopped/crashed and replaying transactions from disk)
- Object is created using the exact same constructor arguments and gets the exact same id
- Object is put to local object pool with that id
- After this point, local and remote JVMs works the same way. Transactions representing
@Modificationmethod calls internally use target object ids. So, as each chained object gets the same id across all JVM sessions,@Modificationmethod calls execute on the very same object.
Constructor instrumentation also does some things which is not possible via plain Java code. In particular it:
- Injects some bytecode which is executed before calling
super class'constructor - Wraps
super class'constructor call in atry/catch/finallyclause.
These are required to handle exceptions thrown from constructors (edge cases) and initiate a ConstructorTransaction in the correct point.
Marks a class as Chained. @Chained is inherited so subclasses of a chained class are also chained. But it's a good practice to annotate them too.
Starting from the root class, Chainvayler compiler
recursively scans packages and references to other classes and instruments all the classes marked with the @Chained annotation.
Marks a method as Modification. All methods in a @Chained class which modify the data should be marked with this annotation and all such methods should be deterministic.
Chainvayler records invocations to such methods with arguments and executes them in the exact same order on other peers and also when the system is restarted. The invocations are synchronized on the chained root.
Marks a method to be synchronized with @Modification methods. Just like @Modification methods, @Synch methods are also synchronized on persistence root.
It's not allowed to call directly or indirectly a @Modification method inside a @Synch method and will result in a ModificationInSynchException.
Includes a class and its package to be scanned. Can be used in any @Chained class. This is typically required when some classes cannot be reached by class and package scanning.
SecretCustomer in the bank sample demonstrates this feature.
Each Chainvayler instance is strongly consistent locally. That is, once the invocation of a @Modification method completed, all reads in the same JVM session reflect the modification.
The overall system is eventually consistent for reads. That is, once the invocation of a @Modification method completed in one JVM, reads on other JVMs may not reflect the modification.
However, the overall system is strongly consistent for writes. That is, once the invocation of a @Modification method completed in one JVM, writes on other JVMs reflect the modification, @Modification methods will wait until all other writes from other JVMs are committed locally. So they can be sure they are modifying latest version of the data.
In other words, provided all changes are deterministic, any @Modification method invocation on any JVM is guaranteed to be executed on the exact same data.
Presumably, it’s also possible to make the overall system strongly consistent for reads. This is achievable by marking the methods which require consistent reads with @ConsistentRead annotation and blocking the method until latest transaction in the network is committed locally.
As all objects are always in memory, assuming proper synchronization, reads should be lightning fast. Nothing can beat the performance of reading an object from memory. In most cases you can expect read times < 1 milliseconds even for very complex data structures. With todays modern hardware, iterating over a Map with one million entries barely takes a few milliseconds. Compare that to full table scan over un-indexed columns in relational databases ;)
Furthemore, reads are almost linearly scalable. Add more nodes to your cluster and your lightning fast reads will scale-out.
However, as it's now, writes are slightly scalable. The overall write performance of the system first increases and then decreases as more nodes are added.
Below chart shows the overall write performance with respect to number replicas. Tested on an AWS EKS cluster with 4 d2.xlarge nodes. Compare it to previous implementation based on Hazelcast IMap, there is improvement both on performance and scalability. Hopefully/possibly there is still room for improvement here.

BTW, the weird fluctuations based on odd/even number of replicas is not a coincidence or typo. Tested it several times. Possibly related to some internals of Hazelcast.
And this one shows local (no replication) write performance with respect to number of writer threads. Tested on an AWS d2.xlarge VM (without Kubernetes)

Above chart also suggests, disk write speed is not the bottleneck of low TX/second numbers when both replication and persistence is enabled. Possibly there is a lot to improve here by making disk writes asynchronous.
Note, for some reason I couldn't figure out yet, Java IO performance drops to ridiculous numbers in Kubernetes after some heavy writes. That's the reason why high replica counts with persistence are missing in the overall write performance chart and non-replication tests are done on a plain VM.
As mentioned, all methods which modify the data in the chained classes should be deterministic. That is, given the same inputs, they should modify the data in the exact same way.
The term deterministic has interesting implications in Java. For example, iteration order of HashSet and HashMap is not deterministic. They depend on the hash values which may not be the same in different JVM sessions. So, if iteration order is siginificant, for example finding the first object in a HashSet which satisfies certain conditions and operate on that, instead LinkedHashSet and LinkedHashMap should be used which provide predictable iteration order.
In contrast, random operations are deterministic as long as you use the same seed.
Another source of indeterminism is depending on the data provided by external actors, for example sensor data or stock market data. For these kind of situations, relevant @Modification methods should accept the data as method arguments. For example, below sample is completely safe:
@Chained
class SensorRecords {
List<Record> records = new ArrayList<>();
void record() {
Record record = readRecordFromSomeSensor();
record(record);
}
@Modification
void record(Record record) {
records.add(record);
}
}Note, clock is also an external actor to the system. Since it's so commonly used, Chainvayler provides a
Clock
facility which can safely be used in @Modification methods instead of System.currentTimeMillis() or new Date().
Clock pauses during the course of transactions and always has the same value for the same transaction regardless of which
JVM session it's running on.
Audits in the Bank sample demonstrates usage of clock facility.
Clock facility can also be used for deterministic randomness. For example:
@Modification
void doSomethingRandom() {
Random random = new Random(Clock.nowMillis());
// do something with the random value
// it will have the exact same sequence on all JVM sessions
}When replication is not enabled, garbage collection works as expected. Any chained object created but not accessible from the root object will be garbage collected soon if there are no other references to it. This is achieved by holding references to chained objects via weak references.
However, this is not possible when replication is enabled. Imagine a chained object is created on a JVM and it's not accessible from the root object, there are only some other local references to it. Those other local references will prevent it to be garbage collected.
When this chained object is replicated to other JVMs, there won't be any local references to it, and hence nothing will stop it to be garbage collected if it's not accessible from the root object.
So, unfortunately, looks like, we need to keep a reference to all created chained objects in replication mode and prevent them to be garbage collected.
Maybe, one possible solution is, injecting some finalizer code to chained objects and notify other JVMs when the chained object is garbage collected in the JVM where the chained object is initially created.
When replication is enabled, clean shutdown is very important. In particular, if a node reserves a transaction ID in the network and dies before sending the transaction to the network, the whole network will hang for some period (20 seconds) for writes, they will wait to receive that missing transaction. After that period they will assume the sending peer died and send the network a NoOp transaction with that ID so the rest of the network can continue operating.
On a healthy system (enough memory for all peers and good network connection) this will most possibly cover > 99% cases. However blocking the network for 20 seconds is not nice and there is also one problematic case where assumed dead peer comes back and sends the network its missing transaction(s). Peers detect this case and closes local Chainvayler instance for further writes for the sake of preserving consistency.
The root cause of this problem is, retrieving the transaction ID and sending the actual transaction to the network is not an atomic operation, it consists of two consecutive steps. Possibly, the actual bullet proof solution, which will also prevent any network hangs, will be combining two operations into a single atomic one. Unfortunately, unless I'm not missing something, Hazelcast does not provide any mechanism to achieve this.
ORM (Object-Relational Mapping) frameworks improved a lot in the last 10 years and made it much easier to map object graphs to relational databases.
However, the still remaining fact is, objects graphs don't naturally fit into relational databases. You need to sacrifice something and there is the overhead for sure.
I would call the data model classes used in conjuction with ORM frameworks as object oriented-ish, since they are not trully object oriented. The very main aspects of object oriented designs, inheritance and polymorphism, and even encapsulation is either impossible or is a real pain with ORM frameworks.
Indeed, possibly this was my main motivation to implement this PoC project: I'm a fan of object oriented design and strongly believe it is naturally a good fit to model the world we are living in. I want my objects persisted/replicated naturally, without compromising basic object oriented design principles.
Hazelcast is a great framework which provides many distributed data structures, locks/maps/queues etc. But still, those structures are not drop-in replacements for Java locks/maps/queues, one needs to be aware of he/she is working with a distributed object and know the limitations. And you are limited to data structures Hazelcast provides.
With Chainvayler there is almost no limit for what data structures can be used. It's truly object oriented and almost completely transparent.
As mentioned, when a node is restarted or joined to a cluster, it executes all transactions up to that point (retrieved either from disk or from network). This can be time consuming if there are already many transactions in place.
A snapshot can be taken to accelerate this process, via the call:
Chainvayler.takeSnapshot();Taking snaphot serializes the root object and all objects which are accessible from the root object to disk. Restarts after that point, loads the serialized copy of the root object and executes transactions which happened only after that point.
I've said Chainvayler is a PoC (proof of concept) library but actually it's more than a PoC.
It's stable as it's now. I'm safely saying this since even a single transaction is missed or executed in wrong order, or a single object gets an incorrect ID, the test runs will fail.
The main point of improvement is, handling disaster scenarios in replication mode.
Lets break the status into two parts:
I won’t hesitate to use Chainvayler's persistence only mode in production for desktop and Android applications right now.
Replication mode, with or without persistence, is the PoC, but getting closer to be production ready. Compare the limitations and performance sections of previous implementation to current status.
Once it’s production ready, it can be used in different domains with several benefits:
- Much simpler and natural object oriented code
- Eliminate databases, persistence layers and all the relevant limitations
- Lightning fast read performance
- Any type of Java application which needs to persist data
- If writes can be scaled-out more, at least to some level, Chainvayler is a very good fit for microservices applications
- Even not, it can still be a good fit for many microservices applications if they are read-centric
So happy transparent persistence and replication to your POJOs :)
Cheers,
r a f t (Hakan Eryargi)