This code implements a method for Lifelong Learning.
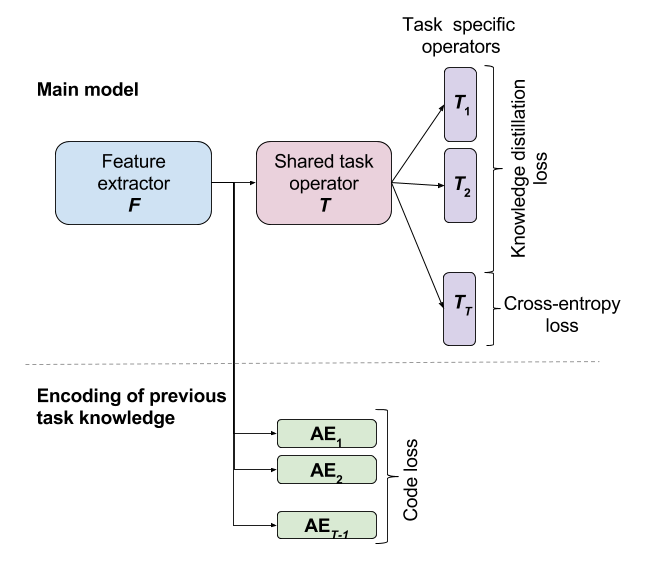
It is based on our work that introduces a new lifelong learning solution where a single model is trained for a sequence of tasks. The main challenge that vision systems face in this context is catastrophic forgetting: as they tend to adapt to the most recently seen task, they lose performance on the tasks that were learned previously. Our method aims at preserving the knowledge of the previous tasks while learning a new one by using autoencoders. For each task, an under-complete autoencoder is learned, capturing the features that are crucial for its achievement. When a new task is presented to the system, we prevent the reconstructions of the features with these autoencoders from changing, which has the effect of preserving the information on which the previous tasks are mainly relying. At the same time, the features are given space to adjust to the most recent environment as only their projection into a low dimension submanifold is controlled. The proposed system is evaluated on image classification tasks and shows a reduction of forgetting over the state-of-the-art.
- MATLAB
- MatConvNet (http://www.vlfeat.org/matconvnet/) - the code is based on version 1.0-beta23.
- GPU: should work with a gpu memory of 4G with batch size of 200.
- Code is tested under linux based system
- Download/clone the current project
- Download MatConvNet-v1.0-beta23 (or later)
- Change MatconvnetPath in the experiments file to your MatConvNet path
- Follow the instruction of the experiments file to download and construct the data
- You're ready to run the experiment file.
Before running the code, please modify the paths in each of the provided codes to match your own paths.
The given experiement code runs a sequence of 3 tasks: Imagenet -> Scenes -> Birds (See the paper for more details about these datasets).
The project contains four main folders:
This folder contains the code to train autoencoders on the output of feature extractor. The training file contains a customized implementation of ADADELTA. This is necessary for the version 1.0-beta23 of MatConvNet. In the latest versions, this can be done by using the solver implemented by MatConvNet.
This contains our core model. It is subdivided into three subfolders:
- Model_preparation: contains the codes to add up all the needed blocks for the model (see figure above)
- Model_training: contains the codes to train this customized model. The different branches of the model are modeled with custom layers.
- For_tests: contains codes to recover the base models (without the additional blocks) for each of the tasks in order to be able to evaluate the models.
This folder contains the functions needed for exp_LwF_with_encoder.m that gives an example of implementation of our method.
- Amal Rannen Triki, Rahaf Aljundi, Matthew B. Blaschko & Tinne Tuytelaars
** All the authours are with KU Leuven, ESAT-PSI, IMEC, Belgium ** A. Rannen Triki is also affiliated with Yonsei University, Korea
** For questions about the code, please contact Amal Rannen Triki (amal.rannen@esat.kuleuven.be) or Rahaf Aljundi (rahaf.aljundi@esat.kuleuven.be)
@article{RannenTrikiAljundi2017encoder,
title={Encoder Based Lifelong Learning},
author={Triki~Rannen, Amal and Aljundi, Rahaf and Blaschko, Mathew B and Tuytelaars, Tinne},
journal={IEEE International Conference of Computer Vision},
year={2017}
}This software package is freely available for research purposes. Please check the LICENSE file for details.
-
This code is mainly based on MatConvNet
-
We used a function used in Li, Zhizhong, and Derek Hoiem. "Learning without forgetting." European Conference on Computer Vision 2016 (see utils/vl_nnsoftmaxdiff.m)