Ramanan Sekar*1, Oleh Rybkin*1, Kostas Daniilidis1, Pieter Abbeel2, Danijar Hafner3,4, Deepak Pathak5,6
(* equal contribution)
1University of Pennsylvania
2UC Berkeley
3Google Research, Brain Team
4University of Toronto
5Carnegie Mellon University
6Facebook AI Research
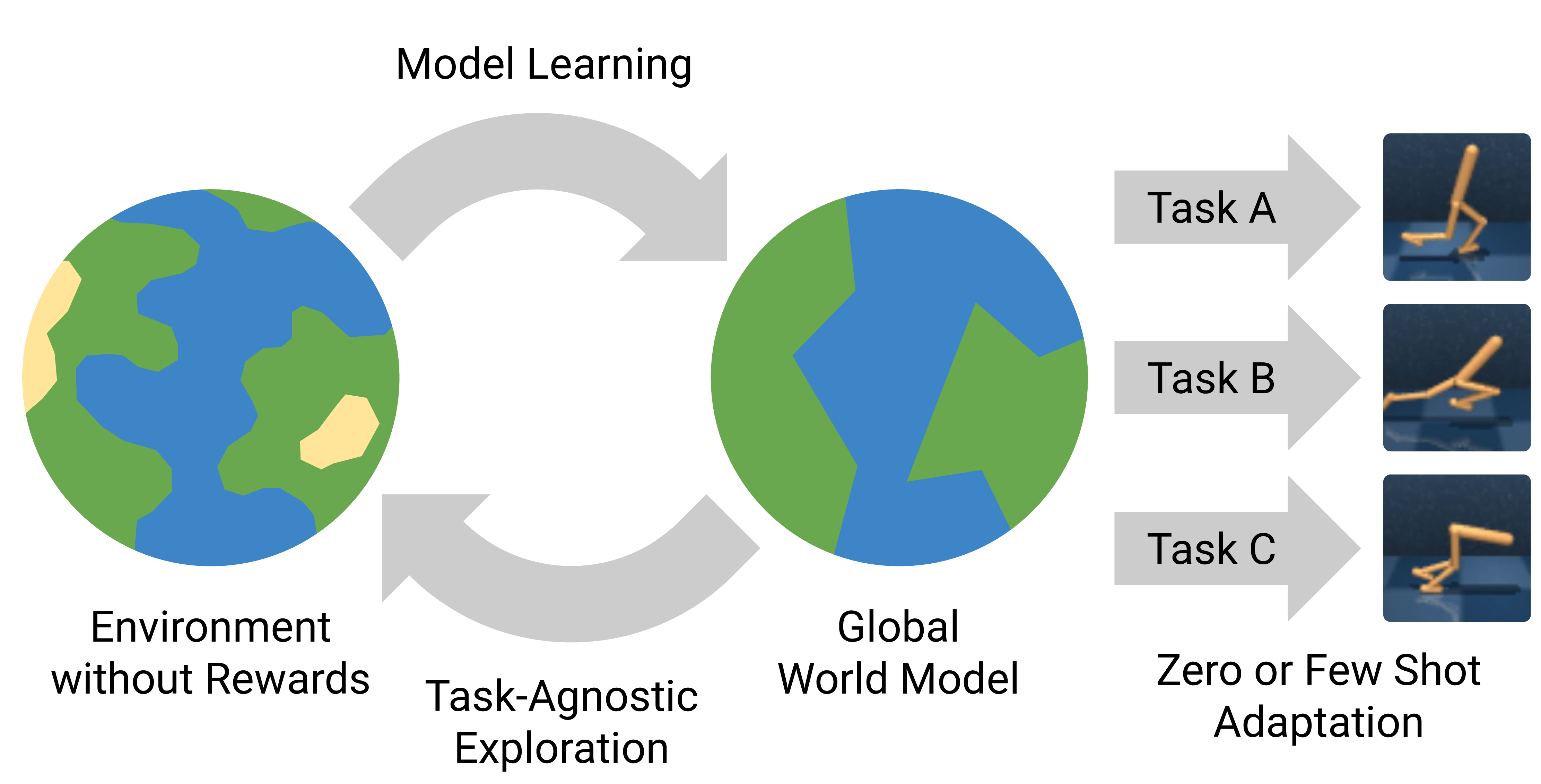
This is a TensorFlow based implementation for our paper on planning to explore via self-supervised world models. This work focuses on self-supervised exploration, where an agent explores a visual environment without yet knowing the tasks it will later be asked to solve. While current methods often learn reactive exploration behaviors to maximize retrospective novelty, we learn a world model trained from images to plan for expected surprise. Novelty is estimated as ensemble disagreement in the latent space of the world model. Exploring and learning the world model without rewards, our approach, Plan2Explore, efficiently adapts to a range of control tasks with high-dimensional image inputs. If you find this work useful in your research, please cite:
@inproceedings{sekar2020planning,
title={Planning to Explore
via Self-Supervised World Models},
author={Ramanan Sekar and Oleh Rybkin
and Kostas Daniilidis and Pieter Abbeel
and Danijar Hafner and Deepak Pathak},
year={2020},
Booktitle={ICML}
}
Please note that a TensorFlow 2 implementation on the base of Dreamer V2 is now available here. To replicate zero-shot results in the TF2 implementation, run
python dreamerv2/train.py --logdir ~/logs/walker_walk/zero_shot --configs dmc_vision --task dmc_walker_walk --expl_behavior Plan2Explore --expl_until 2e6 --steps 2e6 --grad_heads 'decoder'
To replicate few-shot results in the TF2 implementation, run
python dreamerv2/train.py --logdir ~/logs/walker_walk/zero_shot --configs dmc_vision --task dmc_walker_walk --expl_behavior Plan2Explore --expl_until 5e5 --steps 5.05e5 --grad_heads 'decoder'
The number of steps for both of these runs is specified in the agent steps. The number of environment steps as reported in the paper is 2x larger due to action repeat.
git clone https://github.com/ramanans1/plan2explore.git
cd plan2explore/
python3.6 -m venv Plan2Explore
source $PWD/Plan2Explore/bin/activate
pip install --upgrade pip-
CUDNN-7.6, CUDA-9.0, Python-3.6, Tensorflow 1.14.0, Tensorflow Probability 0.7.0, DeepMind Control Suite (
osmesarendering option recommended), gym, imageio, matplotlib, ruamel.yaml, scikit-image, scipy. -
Mujoco-200: Download binaries, put license file inside and add path to .bash_env
-
Run the following command to have the necessary dependencies on the OS:
apt-get update && apt-get install -y --no-install-recommends \
build-essential nano libssl-dev libffi-dev libxml2-dev libxslt1-dev\
zlib1g-dev python3-setuptools python3-pip libglew2.0 libgl1-mesa-glx\
libopenmpi-dev libgl1-mesa-dev libosmesa6 libglfw3 patchelf xserver-xorg-dev xpra- Quick setup for exact replication (Recommended):
pip install -r requirements.txt
- The code was tested under Ubuntu 18.
To train an agent, install the dependencies and then run one of these commands. The commands below all run the default settings of the experiments reported in the paper. Change the task in --params {tasks:...} as required. The available tasks are given in scripts/tasks.py.
- Our Plan2Explore Agent Zero-shot Experiments:
python3 -m plan2explore.scripts.train --expID 1001_walker_walk_plan2explore_zeroshot \
--params {defaults: [disagree], tasks: [walker_walk]}- Random Zero-shot Experiments:
python3 -m plan2explore.scripts.train --expID 1002_walker_walk_random_zeroshot \
--params {defaults: [random], tasks: [walker_walk]}- Model Based Curiosity Zero-shot Experiments
python3 -m plan2explore.scripts.train --expID 1003_walker_walk_curious_zeroshot \
--params {defaults: [prediction_error], tasks: [walker_walk]}- Supervised Oracle (Dreamer) Experiments:
python3 -m plan2explore.scripts.train --expID 1004_walker_walk_dreamer \
--params {defaults: [dreamer], tasks: [walker_walk]}- MAX Zero-shot Experiments:
python3 -m plan2explore.scripts.train --expID 1005_walker_walk_max_zeroshot \
--params {defaults: [disagree], tasks: [walker_walk], use_max_objective: True}- Retrospective Agent Zero-shot Experiments:
python3 -m plan2explore.scripts.train --expID 1006_walker_walk_retrospective_zeroshot \
--params {defaults: [disagree], tasks: [walker_walk], exploration_imagination_horizon: 1, curious_action_bootstrap: False, curious_value_bootstrap: False}- Our Plan2Explore Agent Few-shot Adaptation Experiments (note: you can use the same command setup as the Zero-shot experiments above with the specific adaptation flags as given here for running the adaptation experiments for other agents):
python3 -m plan2explore.scripts.train --expID 1007_walker_walk_plan2explore_adapt \
--params {defaults: [disagree], tasks: [walker_walk], adaptation: True, adaptation_step: 5e6, max_steps: 5.75e6}These are good places to start when modifying the code:
| Directory | Description |
|---|---|
scripts/configs.py |
Add new parameters or change defaults. |
scripts/tasks.py |
Add or modify environments. |
training/utility.py |
Modify Objectives or Optimization Processes |
models |
Add or modify latent transition models. |
networks |
Add or modify encoder, decoder, or one-step models |
control |
Change MPC Agents, add new wrappers, modify simulations |
The available tasks are listed in plan2explore/scripts/tasks.py. The hyper-parameters can be found in plan2explore/scripts/configs.py. The possible configurations for main experiment defaults are disagree [or] random [or] dreamer [or] prediction_error. To get started, some quick hyper-parameters for playing around with Plan2Explore are intrinsic_scale, ensemble_model_type, model_size, state_size, ensemble_loss_scale.
This codebase was built on top of Dreamer.
The evaluation curves for Figures 3 and 6 (zero-shot evaluation) are here