Linux 基本知识
1. 基本概念
1.1. 标准输⼊和命令参数
1.2. 输入重定向
1.3. 输出重定向
1.4. 管道
1.5. 相关资料
1.6. 磁盘分区及目录
1.7. 权限修改 —— chown、chmod
2. 其他资料
2.1. 单引号与双引号
2.2. 脚本中#!/bin/sh与#!/bin/bash的区别
2.3. 指令组合 ||,&&
3. 管道命令
3.1. cut 指令
3.2. grep指令
3.2.1. 选项及参数
3.2.2. 指令实例
3.3. sort
3.3.1. 选项与参数说明
3.3.2. 实例
3.4. xargs(划重点)
3.4.1. 实例
3.5. 其他
3.5.1. uniq
3.5.2. wc
3.5.3. tee
3.5.4. split 分割文件
4. sed
4.1. 选项与参数说明
4.2. 实例
5. 正则表达式
6. awk
6.1. 选项与参数说明
6.2. awk 动作说明
6.3. 实例说明
7. 文件比对
7.1. diff
7.2. comm
8. 日志及文件查找
8.1. less
8.2. more
8.3. tail
8.4. head
9. vi 与 vim 文本编辑
9.1. vi
9.2. vim
10. 软件安装
10.1. rpm
10.1.1. 安装
10.1.2. 查询
10.1.3. 卸载
10.2. yum
11. 其他
11.1. alias
11.2. tar 打包
11.3. wget
11.4. sodu(TODO)
Linux 中的技术
1. mmap
2. 零拷贝Zero-Copy
标准输⼊就是编程语⾔中诸如 scanf 或者 readline 这种命令; ⽽参数是指程序的 main 函数传⼊的 args 字符数组。
以cat命令为例,cat命令的功能是从命令行给出的文件中读取数据,并将这些数据直接送到标准输出。若使用如下命令:
$ cat file
Hello world
Hello world
Bye使用标准输入/输出文件存在以下问题:
- 输入数据从终端输入时,用户费了半天劲输入的数据只能用一次。下次再想用这些数据时就得重新输入。而且在终端上输入时,若输入有误修改起来不是很方便。
- 为了解决上述问题,Linux系统为输入、输出的传送引入了另外两种机制,即输入/输出重定向和管道。
输入重定向是指把命令(或可执行程序)的标准输入重定向到指定的文件中。也就是说,输入可以不来自键盘,而来自一个指定的文件。所以说,输入重定向主要用于改变一个命令的输入源,特别是改变那些需要大量输入的输入源。
命令wc统计指定文件包含的行数、单词数和字符数
直接输入wc,wc将等待用户告诉它统计什么,这时shell就好象死了一样,从键盘键入的所有文本都出现在屏幕上,但并没有什么结果,直至按下ctrl+d,wc才将命令结果写在屏幕上。
[root@VM-0-16-centos ~]# wc
dsf
sadf123
qwe
3 3 16
[root@VM-0-16-centos ~]# wc < file
1 1 7
[root@VM-0-16-centos ~]# wc << file
> delim
> sdfasdf
> sadff
> delim
> file
4 4 26输出重定向是指把命令(或可执行程序)的标准输出或标准错误输出重新定向到指定文件中。这样,该命令的输出就不显示在屏幕上,而是写入到指定文件中。
[root@VM-0-16-centos ~]# echo "sdfadf" > file错误重定向: 和程序的标准输出重定向一样,程序的错误输出也可以重新定向。使用符号2>(或追加符号2>>)表示对错误输出设备重定向。例如下面的命令:
$ ls /usr/tmp 2> err.file标准输入输出均重定向:可以使用另一个输出重定向操作符(&>)将标准输出和错误输出同时送到同一文件中。例如:
$ ls /usr/tmp &> output.file将一个程序或命令的输出作为另一个程序或命令的输入,有两种方法,一种是通过一个临时文件将两个命令或程序结合在一起,例如上个例子中的/tmp/dir文件将ls和wc命令联在一起;另一种是Linux所提供的管道功能。
管道可以把一系列命令连接起来,这意味着第一个命令的输出会作为第二个命令的输入通过管道传给第二个命令,第二个命令的输出又会作为第三个命令的输入,以此类推。显示在屏幕上的是管道行中最后一个命令的输出,通过使用管道符“|”来建立一个管道行。
[root@VM-0-16-centos ~]# cat file|grep adf
sdfadf
[root@VM-0-16-centos ~]# cat file|grep adf|wc -l
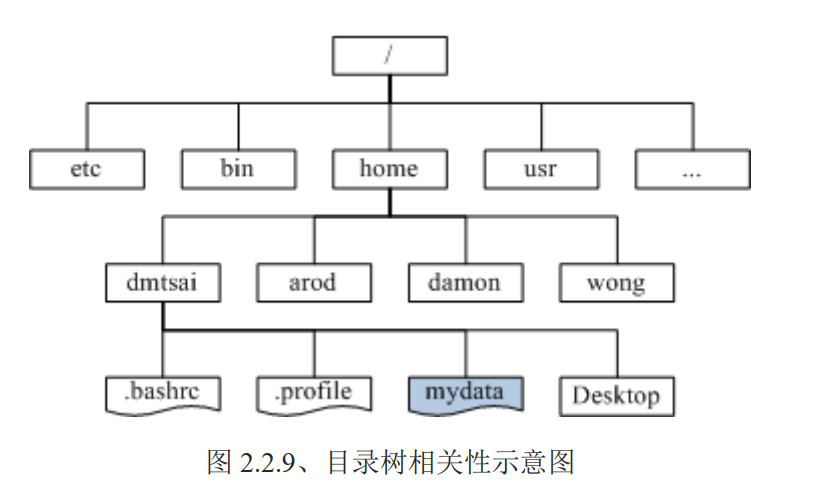
1挂载:利用一个目录当成进入点,将磁盘分区槽的数据放置在该目录下。也就是说,进入该目录就可以读取该分区槽的意思。
挂载点:那个进入点的目录我们称为『挂载点』。
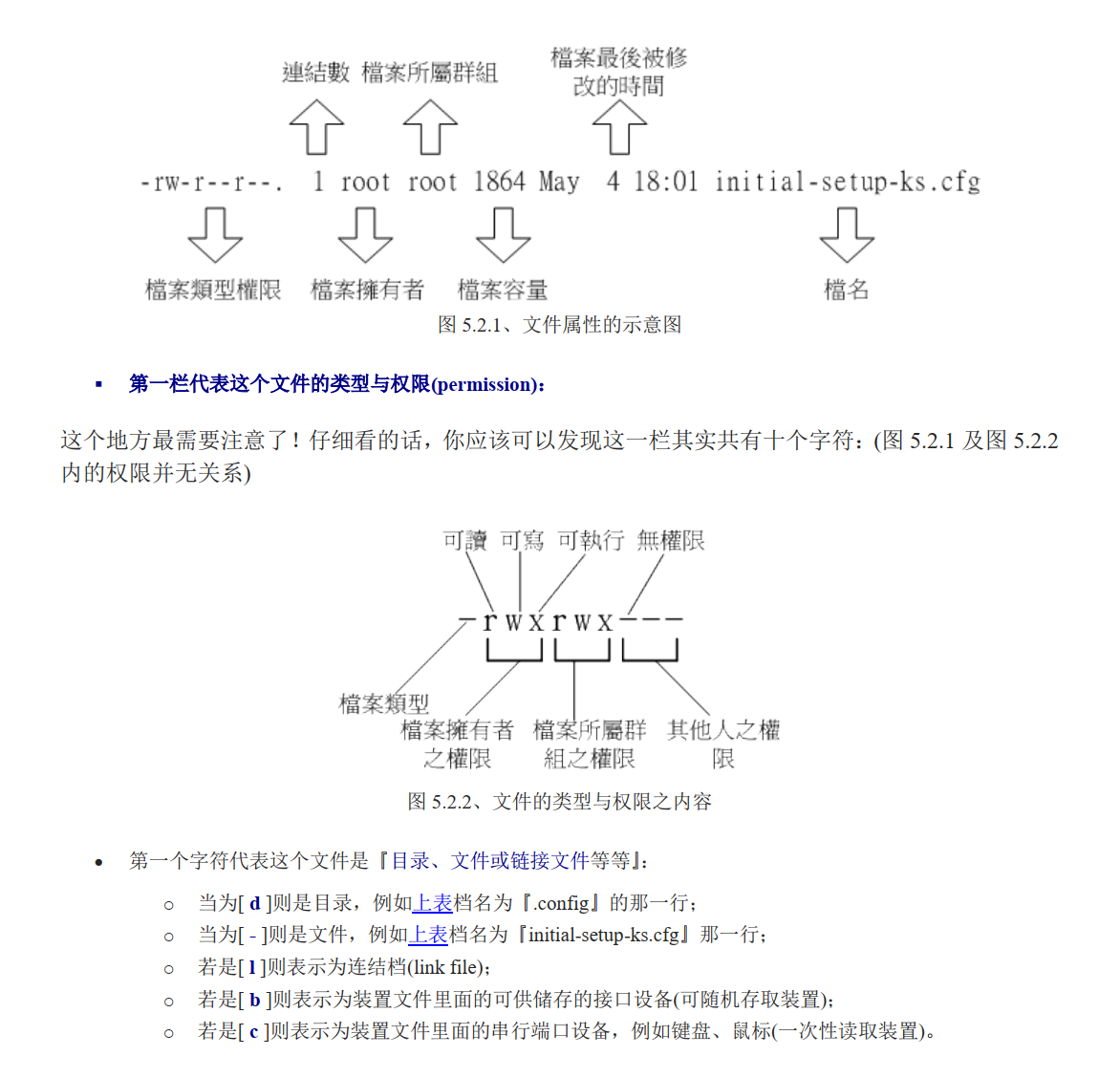
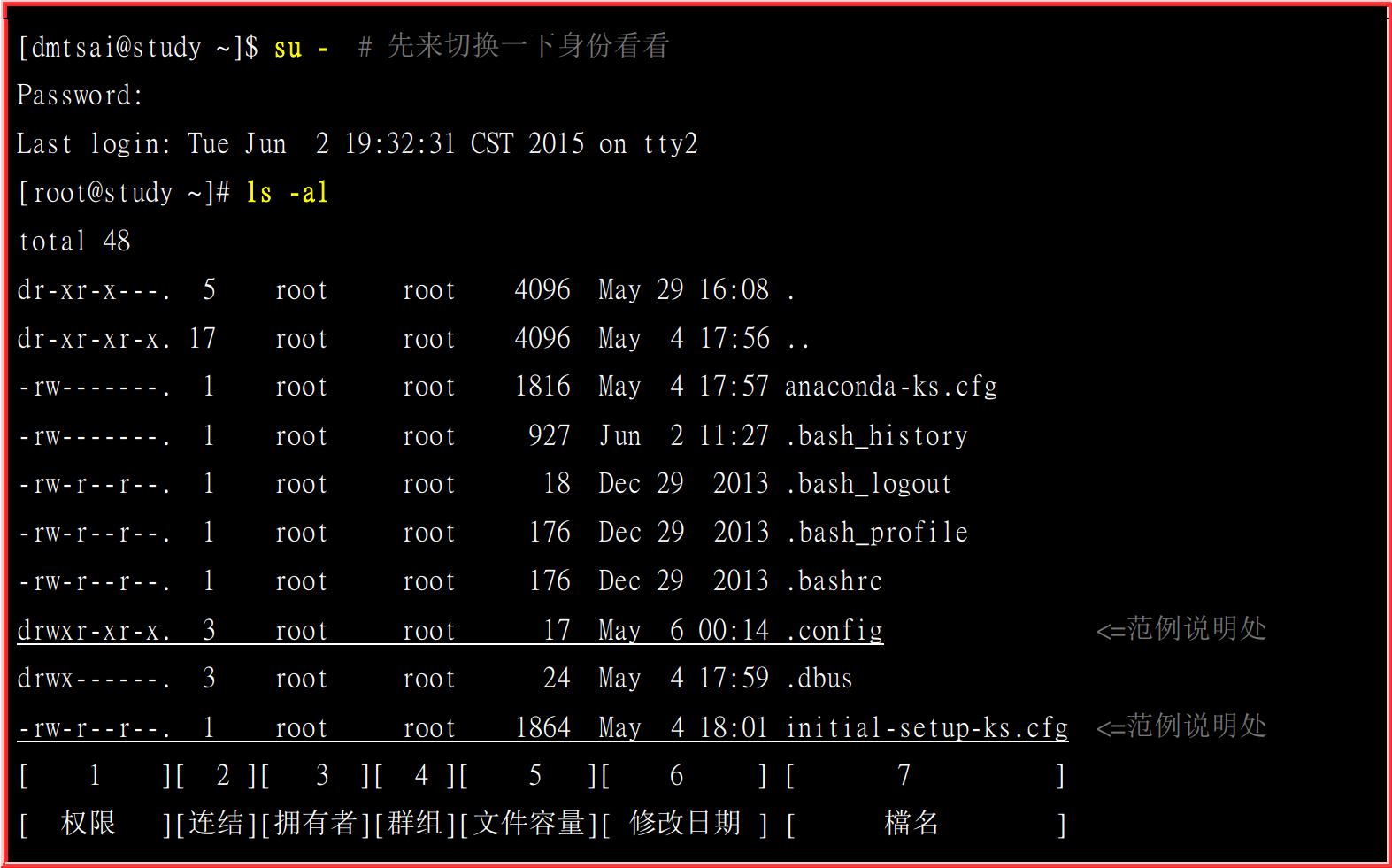
- chgrp :改变文件所属群组
- chown :改变文件拥有者
- chmod :改变文件的权限, SUID, SGID, SBIT 等等的特性

- 单引号、双引号用于用户把带有空格的字符串赋值给变量的分界符。
[root@VM-0-16-centos ~] str="sdf111 sdf"
[root@VM-0-16-centos ~] echo $str
sdf111 sdf
// 如果没有单引号或双引号,shell会把空格后的字符串解释为命令
[root@localhost sh] str=Today is Monday
bash: is: command not found- 单引号和双引号的区别。单引号告诉shell忽略所有特殊字符,而双引号忽略大多数,但不包括
$ \
双引号中的'$'(参数替换)和'`'(命令替换)是例外,所以,两者基本上没有什么区别,除非在内容中遇到了参数替换符$和命令替换符```。
- 反引号 (```) 位于键盘的Tab键的上方,1键的左方。注意与单引号(')位于Enter键的左方的区别。在Linux中起着命令替换的作用。命令替换是指shell能够将一个命令的标准输出插在一个命令行中任何位置。
如,shell会执行反引号中的date命令,把结果插入到echo命令显示的内容中。
[root@localhost sh] echo The date is `date`
The date is 2011年 03月 14日 星期一 21:15:43 CST第一句的#!是对脚本的解释器程序路径,脚本的内容是由解释器解释的,我们可以用各种各样的解释器来写对应的脚本。
比如说/bin/csh脚本,/bin/perl脚本,/bin/awk脚本,/bin/sed脚本,甚至/bin/echo等等。
Ubuntu中可以认为/bin/sh就是/bin/dash, 如果打算使用bash, 可直接将/bin/sh软链接到/bin/bash.
范例三:我不清楚 /tmp/abc 是否存在,但就是要建立 /tmp/abc/hehe 文件
[dmtsai@study ~]$ ls /tmp/abc || mkdir /tmp/abc && touch /tmp/abc/hehe
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
[root@VM-0-16-centos ~] echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@VM-0-16-centos ~] echo ${PATH}| cut -d ":" -f 3,4
/usr/sbin:/usr/bin
// 输出4 之后的字符
[root@VM-0-16-centos ~] echo ${PATH}| cut -c 4-
r/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-i :忽略大小写的不同,所以大小写视为相同
-c :计算找到 '搜寻字符串' 的次数
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
-r :递归查找指定文件夹下所有匹配的文本
-e : 使用正则表达式匹配内容
-l : 只输出匹配到文件的文件名
-L : 只输出未匹配到文件的文件名
-H : 查询文件时显示文件名。
-h : 查询文件时不显示文件名。
-w :整字匹配
-A : 显示匹配行和后n行
-B : 显示匹配行和前n行
-C : 显示匹配行、前n行和后n行
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
-c指令说明
[root@VM-0-16-centos ~] last |cut -f 1 -d " "
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
root
reboot
wtmp
[root@VM-0-16-centos ~] last |cut -f 1 -d " "| wc -l
23
[root@VM-0-16-centos ~] last |cut -f 1 -d " "|grep -c "root"
20
-v反向匹配过滤
[root@VM-0-16-centos ~] last |cut -f 1 -d " "|grep -v "root"
reboot
wtmpgrep "匹配内容" filename
[root@VM-0-16-centos ~] last -n 5 |cut -f 1 -d " "|grep root --color -n
1:root
2:root
3:root
4:root
5:root
-r递归查找
[root@VM-0-16-centos ~] grep -r 23000 ./test
./test/temp:VBird 23000 24000 25000
./test/temp:DMTsai 21000 20000 23000
./test/tmp/record:VBird 23000 24000 25000
./test/tmp/record:DMTsai 21000 20000 23000
-e正则表达式
-l 与 -L 输出文件名
[root@VM-0-16-centos test] ls ./*
./file ./temp
./tmp:
record
// 输出匹配到文本的文件名
[root@VM-0-16-centos test] grep -r 23000 ./ -l
./temp
./tmp/record
// 输出未匹配到文本的文件名
[root@VM-0-16-centos test] grep -r 23000 ./ -L
./file
-h匹配不显示文件名-H匹配显示文件名
[root@VM-0-16-centos test] grep -r 23000 ./ -h
VBird 23000 24000 25000
DMTsai 21000 20000 23000
VBird 23000 24000 25000
DMTsai 21000 20000 23000
[root@VM-0-16-centos test] grep "2300" temp -H
temp:VBird 23000 24000 25000
temp:DMTsai 21000 20000 23000
-A -B -C 行数显示说明
[root@VM-0-16-centos test] grep "20000" temp -C 1
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
[root@VM-0-16-centos test] grep "20000" temp -A 1 -B 1
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
-w 整字匹配
[root@VM-0-16-centos test] grep "VB" temp
VBird 23000 24000 25000
[root@VM-0-16-centos test] grep -w "VB" temp [dmtsai@study ~]$ sort [-fbMnrtuk] [file or stdin]
选项与参数:
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空格符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用『纯数字』进行排序(默认是以文字型态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符,预设是用 [tab] 键来分隔;
-k :以那个区间 (field) 来进行排序的意思
// 内容是以 : 来分隔的,以第三栏来排序
[root@VM-0-16-centos ~] cat /etc/passwd |sort -t ":" -k 3
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
// 排序汇总
cat file|sort -uxargs 可以读入 stdin 的数据,并且以空格符或断行字符作为分辨,将 stdin 的资料分隔成为 arguments
- xargs命令还可以从文件读取条目,而不是从标准输入读取条目。使用-a选项,后跟文件名。
- xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
选项与参数:
- -0 :如果输入的 stdin 含有特殊字符,例如 `, , 空格键等等字符时,这个 -0 参数可以将他还原成一般字符。这个参数可以用于特殊状态喔!
- -e :这个是 EOF (end of file) 的意思。后面可以接一个字符串,当 xargs 分析到这个字符串时,就会停止继续工作!
- -p :在执行每个指令的 argument 时,都会询问使用者的意思;
- -n :后面接次数,每次 command 指令执行时,要使用几个参数的意思。
- -t 表示先打印命令,然后再执行。 当 xargs 后面没有接任何的指令时,默认是以 echo 来进行输出喔!
[root@VM-0-16-centos ~] find /usr/sbin -perm /7000 | xargs ls -l
-rwxr-sr-x 1 root root 11224 Apr 1 2020 /usr/sbin/netreport
-rwsr-xr-x 1 root root 11232 Apr 1 2020 /usr/sbin/pam_timestamp_check
-rwsr-xr-x 1 root root 36272 Apr 1 2020 /usr/sbin/unix_chkpwd
-rws--x--x 1 root root 40328 Aug 9 2019 /usr/sbin/userhelper
-rwsr-xr-x 1 root root 11296 Apr 1 2020 /usr/sbin/usernetctl单行与多行的变换-n
[root@VM-0-16-centos ~] cat test
a b c d e f g
h i j k l m n
o p q
r s t
u v w x y z
// xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。 单行变多行通过-n指令实现。
[root@VM-0-16-centos ~] cat test |xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@VM-0-16-centos ~] cat test |xargs -n4
a b c d
e f g h
i j k l
m n o p
q r s t
u v w x
y z-t 输出执行参数
[root@VM-0-16-centos ~] ls |grep lsroot| xargs -t
echo lsrootaa lsrootab lsrootac
lsrootaa lsrootab lsrootac
[root@VM-0-16-centos ~] ls |grep lsroot| xargs -t rm -rf
rm -rf lsrootaa lsrootab lsrootac
-p 执行时进行询问
[root@VM-0-16-centos ~] cat test |xargs -p -n4
echo a b c d ?...y
a b c d
echo e f g h ?...y
e f g h
echo i j k l ?...y
i j k l
echo m n o p ?...y
m n o p
echo q r s t ?...y
q r s t
echo u v w x ?...y
u v w x
echo y z ?...y
y z
定义:仅列出一个显示
选项与参数:
- -i :忽略大小写字符的不同;
- -c :进行计数
范例一:使用 last 将账号列出,仅取出账号栏,进行排序后仅取出一位;
[root@VM-0-16-centos ~] last | cut -d ' ' -f1 | sort | uniq
reboot
root
wtmp
范例二:承上题,如果我还想要知道每个人的登入总次数呢?
[root@VM-0-16-centos ~] last | cut -d ' ' -f1 | sort | uniq -c
1
1 reboot
27 root
1 wtmp
定义:统计计算
选项与参数:
- -l :仅列出行;
- -w :仅列出多少字(英文单字);
- -m :多少字符
[root@VM-0-16-centos ~] last |wc
30 288 2194
//输出的三个数字中,分别代表:『行、字数、字符数』
[root@VM-0-16-centos ~] last |wc -l
30
定义:tee 会同时将数据流分送到文件去与屏幕 (screen);而输出到屏幕的,其实就是 stdout
[dmtsai@study ~]$ last | tee last.list | cut -d " " -f1
//这个范例可以让我们将 last 的输出存一份到 last.list 文件中
选项与参数:
- -b :后面可接欲分区成的文件大小,可加单位,例如 b, k, m 等;
- -l :以行数来进行分区。
- PREFIX :代表前导符的意思,可作为分区文件的前导文字。
// 按1k 分割文件
[root@VM-0-16-centos ~] split -b 1k lsrootaa
// 按1k 分割文件,指定文件前缀为sadf
[root@VM-0-16-centos ~] split -b 1k lsrootaa sadf
// 使用 ls -al / 输出的信息中,每十行记录成一个文件
[root@VM-0-16-centos ~] ls -al / | split -l 10 - lsroot
[dmtsai@study ~]$ sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在指令列模式上进行 sed 的动作编辑
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function 有底下这些咚咚:
a :新增, a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运作~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!
例如 1,20s/old/new/g 就是
function:ddemo
[root@VM-0-16-centos ~] nl file
1 sdfadf
2 123
3 123
4 123
5 12
6 3123
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
[root@VM-0-16-centos ~] nl file |sed '2,5d'
1 sdfadf
6 3123
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12function:a 新增demo 会新增到下一行
[root@VM-0-16-centos ~] nl file |sed '2a|sadf'
1 sdfadf
2 123
|sadf
3 123
4 123
5 12
6 3123
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
// 新增多行以反斜杠结尾
[root@VM-0-16-centos ~] nl file |sed '2a|sadf............\
dsfasdff ? dfsd\
dsfasdf'
1 sdfadf
2 123
|sadf............
dsfasdff ? dfsd
dsfasdf
3 123
4 123
5 12
6 3123
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
function:c 行替换例子
[root@VM-0-16-centos ~] nl file|sed '2,6c go down town'
1 sdfadf
go down town
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
function:p打印修改行数
-n输出sed修改的行数
[root@VM-0-16-centos ~] nl file | sed -n '2,10p'
2 123
3 123
4 123
5 12
6 3123
7 123123
8 qwe
9 123
10 qwe
function:s替换内容sed 's/要被取代的字符串/新的字符串/g'
被取代的字符串部分可以使用正则表达式
[root@VM-0-16-centos ~] nl file
1 sdfadf
2 123
3 123
4 123
5 12
6 3123
7 123123
8 qwe
9 123
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
[root@VM-0-16-centos ~] nl file |sed 's/^.*123/456/g'
1 sdfadf
456
456
456
5 12
456
456
8 qwe
456
10 qwe
11 qwe
12 qwe
13 asd
14 qwea
15 sd
16 xzcZXc
17 qwweqwe12
-
sed -i修改文件内容 -
sed 在每行头部或者尾部添加固定字符
[root@VM-0-16-centos ~] cat file |sed 's/^/yep/g'
yepsdfadf
yep123
yep123
yep123
yep12
yep3123
yep123123
yepqwe
yep123
yepqwe
yepqwe
yepqwe
yepasd
yepqwea
yepsd
yepxzcZXc
yepqwweqwe12
[root@VM-0-16-centos ~] cat file |sed 's/$/~yep/g'
sdfadf~yep
123~yep
123~yep
123~yep
12~yep
3123~yep
123123~yep
qwe~yep
123~yep
qwe~yep
qwe~yep
qwe~yep
asd~yep
qwea~yep
sd~yep
xzcZXc~yep
qwweqwe12~yep
-i忽略大小写匹配
[root@VM-0-16-centos test] cat temp
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
[root@VM-0-16-centos test] grep "name" temp
[root@VM-0-16-centos test] grep -i "name" temp
Name 1st 2nd 3th
| 正则表达式 | 范例 | 匹配结果 |
|---|---|---|
| + | 意义:重复『一个或一个以上』的前一个 RE 字符 | egrep -n 'go+d' regular_express.txt 搜寻 (god) (good) (goood)... 等等的字符串 |
| ? | 意义:『零个或一个』的前一个 RE 字符 | egrep -n 'go+d' regular_express.txt 范例:搜寻 (gd) (god) 这两个字符串。 |
| 竖线 | 意义:用或( or )的方式找出数个字符串 | egrep -n 'gd/good' regular_express.txt 范例:搜寻 gd 或 good 这两个字符串 |
| () | 意义:找出『群组』字符串 | egrep 'A(xyz)+C' 范例:将『AxyzxyzxyzxyzC』用 echo 叫出 |
| ^ | 匹配输入字符串的开始位置 | egrep '^ABC' 范例:匹配以ABC开头的 |
| $ | 匹配输入字符串的结尾位置 | egrep 'CBA$' 范例:匹配以CBA结尾的 |
awk 主要是处理『每一行的字段内的数据』,而默认的『字段的分隔符为 "空格键" 或 "[tab]键" 』!
选项参数:
-F : 指定输入文件的分隔符
-v: 赋值一个用户自定义遍历
-f: 从脚本文件中读取awk命令。
-F选项例子: 当未指定分割符号的情况,默认使用空格或者tab作为分割
[root@VM-0-16-centos ~] cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdow
// 按 : 分割 输出1, 2 字段
[root@VM-0-16-centos ~] cat /etc/passwd | awk -F ":" '{print $1 "|" $2}'
root|x
bin|x
daemon|x
adm|x
lp|x
sync|x
[root@VM-0-16-centos ~] last -n 5
root pts/1 140.206.51.97 Sun Jan 31 12:22 still logged in
root pts/1 59.61.69.209 Tue Jan 12 10:09 - 17:34 (07:25)
root pts/2 223.104.49.216 Mon Jan 11 13:40 - 20:31 (06:50)
root pts/1 223.104.49.216 Mon Jan 11 13:38 - 20:31 (06:52)
root pts/1 59.61.69.209 Mon Jan 11 09:52 - 13:24 (03:31)
wtmp begins Wed Dec 23 00:06:07 2020
//
[root@VM-0-16-centos ~] last -n 5 |awk '{print $3"\t"$1}'
140.206.51.97 root
59.61.69.209 root
223.104.49.216 root
223.104.49.216 root
59.61.69.209 root
Wed wtmp
-v:自定义变量
[root@VM-0-16-centos ~] last -n 5 |awk -v bk=aisibi '{print $3"\t"$1"\t"bk}'
140.206.51.97 root aisibi
59.61.69.209 root aisibi
223.104.49.216 root aisibi
223.104.49.216 root aisibi
59.61.69.209 root aisibi
aisibi
Wed wtmp aisibi
awk 后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作。 awk 可以处理后续接的文件,也可以读取来自前个指令的 standard output 。
[dmtsai@study ~]$ awk '条件类型 1{动作 1} 条件类型 2{动作 2} ...' filename动作中变量说明:
| 变量名称 | 代表意义 |
|---|---|
| $0 | 代表整行数据 |
| $1, $2 | 代表第一个参数,第二个参数... |
| NF | 每一行 ($0) 拥有的字段总数 |
| NR | 目前 awk 所处理的是『第几行』数据 |
| FS | 目前的分隔字符,默认是空格键 |
BEGIN:用来预先设定 awk 的变量。BEGIN{ 这里面放的是执行前的语句 }如果未使用预设,可能会导致第一行数据处理未生效的情况。
END:END {这里面放的是处理完所有的行后要执行的语句 }
print:打印指定输出内容
[root@VM-0-16-centos ~] last -n 5
root pts/1 140.206.51.97 Sun Jan 31 12:22 still logged in
root pts/1 59.61.69.209 Tue Jan 12 10:09 - 17:34 (07:25)
root pts/2 223.104.49.216 Mon Jan 11 13:40 - 20:31 (06:50)
root pts/1 223.104.49.216 Mon Jan 11 13:38 - 20:31 (06:52)
root pts/1 59.61.69.209 Mon Jan 11 09:52 - 13:24 (03:31)
wtmp begins Wed Dec 23 00:06:07 2020
[root@VM-0-16-centos ~] last -n 5| awk '{print $1"\t"$3}'
root 140.206.51.97
root 59.61.69.209
root 223.104.49.216
root 223.104.49.216
root 59.61.69.209
wtmp Wed
[root@VM-0-16-centos ~] last -n 5| awk '{print $1 "\t lines: " NR "\t columns: " NF}'
root lines: 1 columns: 10
root lines: 2 columns: 10
root lines: 3 columns: 10
root lines: 4 columns: 10
root lines: 5 columns: 10
lines: 6 columns: 0
wtmp lines: 7 columns: 7[root@VM-0-16-centos ~] cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@VM-0-16-centos ~] cat /etc/passwd |awk 'BEGIN {FS=":"} $3<10 {print $1 "\t" $3}'
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
[root@VM-0-16-centos ~] cat /etc/passwd |awk -F ":" ' $3<10 {print $1 "\t" $3}'
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
汇总求值:
$ ls -l *.txt | awk '{sum+=$5} END {print sum}'
--------------------------------------------------
666581字段最后拼接:首行特殊处理,其他行最后拼接字符串
[root@VM-0-16-centos ~] cat temp
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
[root@VM-0-16-centos ~] cat temp |awk 'NR==1 {print $0" ""Totual"} NR>=2 {all=$2+$3+$4;print $0" "all}'
Name 1st 2nd 3th Totual
VBird 23000 24000 25000 72000
DMTsai 21000 20000 23000 64000
Bird2 43000 42000 41000 126000
选项与参数: from-file :一个档名,作为原始比对文件的档名; to-file :一个档名,作为目的比对文件的档名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表『Standard input』之意。
- -b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
- -B :忽略空白行的差异。
- -i :忽略大小写的不同
[root@VM-0-16-centos ~] cp test test-bk
[root@VM-0-16-centos ~] diff test test-bk
[root@VM-0-16-centos ~] vi test-bk
// 表示右边的文件新增了字符
[root@VM-0-16-centos ~] diff test test-bk
2a3
> i dsfa Linux comm 命令用于比较两个已排过序的文件。这项指令会一列列地比较两个已排序文件的差异,并将其结果显示出来,如果没有指定任何参数,则会把结果分成 3 列显示:
- 第 1 列仅是在第 1 个文件中出现过的列
- 第 2 列是仅在第 2 个文件中出现过的列
- 第 3 列则是在第 1 与第 2 个文件里都出现过的列。
选项及参数:
- -1 不显示只在第 1 个文件里出现过的列。
- -2 不显示只在第 2 个文件里出现过的列。
- -3 不显示只在第 1 和第 2 个文件里出现过的列。
[root@VM-0-16-centos ~] comm -12 test test-bk
a b c d e f g
h i j k l m n
o p q
r s t
u v w x y z
[root@VM-0-16-centos ~] comm -1 test test-bk
a b c d e f g
h i j k l m n
i dsfa
o p q
r s t
u v w x y z
[root@VM-0-16-centos ~] comm -13 test test-bk
i dsfa
[root@VM-0-16-centos ~] comm test test-bk
a b c d e f g
h i j k l m n
i dsfa
o p q
r s t
u v w x y z
less 与 more 类似,但使用 less 可以随意浏览文件,而且 less 在查看之前不会加载整个文件。
参数与选项
- -N 显示每行的行号
- /字符串:向下搜索"字符串"的功能
- ?字符串:向上搜索"字符串"的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
more 命令类似 cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示
参数与选项
- 空格键 向下滚动一屏
- Ctrl+B 返回上一屏
- :f 输出文件名和当前行的行号
- q 退出more
- V 调用vi编辑器
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
-f循环读取-n<行数> 显示文件的尾部 n 行内容-c<数目> 显示的字节数
[root@VM-0-16-centos logs] tail -200f zookeeper-root-server-VM-0-16-centos.out
[root@VM-0-16-centos logs] tail -n 1000 zookeeper-root-server-VM-0-16-centos.out
[root@VM-0-16-centos logs] tail -c 100 zookeeper-root-server-VM-0-16-centos.out
hreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)head 命令可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。
参数与选项:
- -q 隐藏文件名
- -v 显示文件名
- -c<数目> 显示的字节数。
- -n<行数> 显示的行数。
[root@VM-0-16-centos logs] head -n 2 zookeeper-root-server-VM-0-16-centos.out
2020-12-26 17:21:12,027 [myid:] - INFO [main:QuorumPeerConfig@174] - Reading configuration from: /usr/local/apache-zookeeper-3.6.2-bin/bin/../conf/zoo.cfg
2020-12-26 17:21:12,235 [myid:] - INFO [main:QuorumPeerConfig@460] - clientPortAddress is 0.0.0.0:2181
[root@VM-0-16-centos logs] head -c 20 zookeeper-root-server-VM-0-16-centos.out
2020-12-26 17:21:12,
vi 共分为三种模式,分别是 -『一般指令模式』: 默认模式 -『编辑模式』: 在一般模式中『i, I, o, O, a, A, r, R』等任何一个字母之后才会进入编辑模式 -『指令列命令模式』:在一般模式当中,输入『 : / ? 』三个中的任何一个按钮,就可以将光标移动到最底下那一列
按键说明:
[Ctrl] + [f] 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用)
[Ctrl] + [b] 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用)
[Ctrl] + [d] 屏幕『向下』移动半页
[Ctrl] + [u] 屏幕『向上』移动半页
// 搜索字符
/word: 向光标之下寻找一个名称为 word 的字符串。例如要在文件内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用)
?word: 向光标之上寻找一个字符串名称为 word 的字符串
n: 这个 n 是英文按键。代表『重复前一个搜寻的动作』。举例来说, 如果刚刚我们执行/vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为vbird 的字符串!
N( shift + n): 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird后,按下 N 则表示『向上』搜寻 vbird
// 一般模式的操作
:w :将编辑的数据写入硬盘文件中(常用)
:w! :若文件属性为『只读』时,强制写入该文件。不过,到底能不能写入, 还是跟你对该文件的文件权限有关啊!
:q :离开 vi (常用)
:q! :若曾修改过文件,又不想储存,使用 ! 为强制离开不储存文件。
:wq :储存后离开,若为 :wq! 则为强制储存后离开 (常用)
:w [filename] : 将编辑的数据储存成另一个文件(类似另存新档)
:r [filename] : 在编辑的数据中,读入另一个文件的数据。亦即将 『filename』 这个文件内容加到游标所在列后面
vi 的额外功能增强 TODO
[root@study ~] rpm -ivh package_name
选项与参数:
- -i :install 的意思
- -v :察看更细部的安装信息画面
- -h :以安装信息列显示安装进度
-q :仅查询,后面接的软件名称是否有安装;
-qa :列出所有的,已经安装在本机 Linux 系统上面的所有软件名称;
-qi :列出该软件的详细信息 (information),包含开发商、版本与说明等;
-ql :列出该软件所有的文件与目录所在完整文件名 (list);
-qc :列出该软件的所有配置文件 (找出在 /etc/ 底下的檔名而已)
-qd :列出该软件的所有说明文件 (找出与 man 有关的文件而已)
-qR :列出与该软件有关的相依软件所含的文件 (Required 的意思)
-qf :由后面接的文件名,找出该文件属于哪一个已安装的软件;
-q --scripts:列出是否含有安装后需要执行的脚本档,可用以 debug 喔!
- 查询是否安装,列出详细信息
[root@VM-0-16-centos logs] rpm -qa kernel
kernel-3.10.0-1127.19.1.el7.x86_64
[root@VM-0-16-centos logs] rpm -qi kernel
Name : kernel
Version : 3.10.0
Release : 1127.19.1.el7
Architecture: x86_64
Install Date: Thu 03 Sep 2020 11:49:30 AM CST
Group : System Environment/Kernel
Size : 67368285
License : GPLv2
Signature : RSA/SHA256, Wed 26 Aug 2020 02:25:08 AM CST, Key ID 24c6a8a7f4a80eb5
Source RPM : kernel-3.10.0-1127.19.1.el7.src.rpm
Build Date : Wed 26 Aug 2020 01:38:57 AM CST
Build Host : kbuilder.bsys.centos.org
Relocations : (not relocatable)
Packager : CentOS BuildSystem <http://bugs.centos.org>
Vendor : CentOS
URL : http://www.kernel.org/
Summary : The Linux kernel
Description :
The kernel package contains the Linux kernel (vmlinuz), the core of any
Linux operating system. The kernel handles the basic functions
of the operating system: memory allocation, process allocation, device
input and output, etc.
rpm -e xxx
[root@study ~] rpm -qa | grep pam
fprintd-pam-0.5.0-4.0.el7_0.x86_64
pam-1.1.8-12.el7.x86_64
gnome-keyring-pam-3.8.2-10.el7.x86_64
pam-devel-1.1.8-12.el7.x86_64
pam_krb5-2.4.8-4.el7.x86_64
[root@study ~] rpm -e pam
error: Failed dependencies: <==这里提到的是相依性的问题
libpam.so.0()(64bit) is needed by (installed) systemd-libs-208-20.el7.x86_64
libpam.so.0()(64bit) is needed by (installed) libpwquality-1.2.3-4.el7.x86_64
// ....以下省略....
//若仅移除 pam-devel 这个之前范例安装上的软件呢
[root@study ~] rpm -e pam-devel <==不会出现任何讯息
[root@study ~] rpm -q pam-devel
package pam-devel is not installed在rpm的基础上发展而来的,在线升级机制.
选项与参数:
- -y :当 yum 要等待用户输入时,这个选项可以自动提供 yes 的响应;
- search :搜寻某个软件名称或者是描述 (description) 的重要关键字;
- list :列出目前 yum 所管理的所有的软件名称与版本,有点类似 rpm -qa;
- info :同上,不过有点类似 rpm -qai 的执行结果;
- provides:从文件去搜寻软件!类似 rpm -qf 的功能!
安装: yum install pam-devel
移除: yum remove pam-devel
更新: yum upgrate xxx
清除旧数据:
[root@study ~] yum clean [packages|headers|all]选项与参数:
packages:将已下载的软件文件删除
headers :将下载的软件文件头删除
all :将所有软件库数据都删除!
范例一:删除已下载过的所有软件库的相关数据 (含软件本身与列表)
[root@study ~] yum clean all
设置别名命名,如alias lm='ls -al | more'
[root@VM-0-16-centos logs] alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'- 压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
- 查 询:tar -jtv -f filename.tar.bz2
- 解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
wget是一个下载文件的工具,支持HTTP,HTTPS和FTP协议,可以使用HTTP代理。
wget -O下载并以不同的文件名保存(-O:下载文件到对应目录,并且修改文件名称)
wget -O wordpress.zip http://www.minjieren.com/download.aspx?id=1080
wget -b后台下载
wget -b <a href="http://www.minjieren.com/wordpress-3.1-zh_CN.zip">http://www.minjieren.com/wordpress-3.1-zh_CN.zip</a>
sudo是linux下常用的允许普通用户使用超级用户权限的工具,允许系统管理员让普通用户执行一些或者全部的root命令,如halt,reboot,su等等。
sudo mkdir -p /var/lib/mongo
sudo mkdir -p /var/log/mongodb
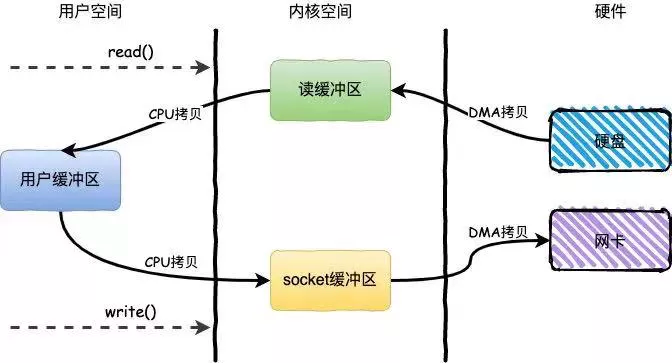
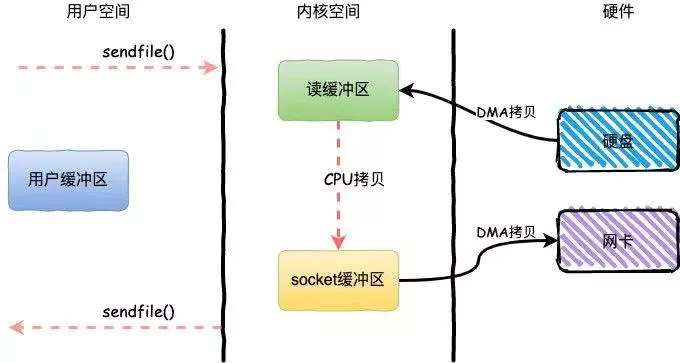
零拷贝是指数据直接从磁盘文件复制到网卡设备,而无需经过应用程序,减少了内核和用户模式之间的上下文切换。
下面这个过程是不采用零拷贝技术时,从磁盘中读取文件然后通过网卡发送出去的流程,可以看到:经历了 4 次拷贝,4 次上下文切换。
 如果采用零拷贝技术(底层通过 sendfile 方法实现),流程将变成下面这样。可以看到:只需 3 次拷贝以及 2 次上下文切换,显然性能更高。
如果采用零拷贝技术(底层通过 sendfile 方法实现),流程将变成下面这样。可以看到:只需 3 次拷贝以及 2 次上下文切换,显然性能更高。
传统 Read/Write 方式进行网络文件传输,在传输过程中,文件数据实际上是经过了四次 Copy 操作,其具体流程细节如下:
- 调用 Read 函数,文件数据被 Copy 到内核缓冲区。
- Read 函数返回,文件数据从内核缓冲区 Copy 到用户缓冲区
- Write 函数调用,将文件数据从用户缓冲区 Copy 到内核与 Socket 相关的缓冲区。
- 数据从 Socket 缓冲区 Copy 到相关协议引擎。
硬盘—>内核 buf—>用户 buf—>Socket 相关缓冲区—>协议引擎