MyBatis
1. 执行流程
2. Interceptor的实现原理
3. #{}和${}的区别是什么?
4. Xml 映射文件中,除了常见的 select|insert|updae|delete 标签之外,还有哪些标签?
5. 通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
6. MyBatis的分页
7. MyBatis 是如何将 sql 执行结果封装为目标对象并返回的?都有哪些映射形式?
8. MyBatis 的关联查询?
9. MyBatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复?
10. MyBatis 都有哪些 Executor 执行器?它们之间的区别是什么?
11. MyBatis xml文件与内部数据结构之间的关系?
12. 为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
13. mybatis与Hibernate区别
14. mybatis的一二级缓存
15. 千万级数据查询方案---- 流式查询
16. MyBatis的设计模式
17. @Param的作用
- 一个demo
<resultMap id="ExtListBaseResultMap" type="com.xy.tms.tran.entity.vo.TranSeaPlanListVo"
extends="com.xy.tms.tran.dao.TranSeaPlanMapper.BaseResultMap">
<result column="sea_plan_detail_id" jdbcType="BIGINT" property="seaPlanDetailId"/>
<result column="ship_company_order_no" jdbcType="VARCHAR" property="shipCompanyOrderNo"/>
<result column="materiel_code" jdbcType="VARCHAR" property="materielCode"/>
<result column="materiel_name" jdbcType="VARCHAR" property="materielName"/>
<result column="materiel_id" jdbcType="BIGINT" property="materielId"/>
<result column="status" jdbcType="VARCHAR" property="status"/>
<result column="create_by" jdbcType="VARCHAR" property="createBy" />
<result column="create_by_name" jdbcType="VARCHAR" property="createByName" />
<result column="create_time" jdbcType="TIMESTAMP" property="createTime" />
<result column="update_by" jdbcType="VARCHAR" property="updateBy" />
<result column="update_by_name" jdbcType="VARCHAR" property="updateByName" />
<result column="update_time" jdbcType="TIMESTAMP" property="updateTime" />
<collection property="sysRoleIdList" javaType="java.util.ArrayList" ofType="java.lang.String" resultMap="itemResultId"/>
</resultMap>
<resultMap id="itemResult" type="java.lang.String">
<id column="role_name" javaType="java.lang.String" jdbcType="VARCHAR" property="role_name"/>
</resultMap>
<sql id="Base_Column_List">
tran_main_plan_id, organization_id, tran_order_id, tran_main_plan_no, plan_sort,
tran_type, tran_type_desc, tran_method, tran_method_desc, start_station_id, end_station_id,
audit_status, audit_status_desc, audit_time, audit_user, allot_status, allot_status_desc,
delivery_status, delivery_status_desc, remark, create_by, create_by_name, create_time,
update_by, update_by_name, update_time, version
</sql>
<select id="querySeaPlan" parameterType="com.xy.tms.tran.entity.vo.TranSeaPlanQueryVo"
resultMap="ExtListBaseResultMap">
SELECT
<include refid="Base_Column_List" />
tsp.sea_plan_id sea_plan_id,
tsp.status_desc status_desc, -- 状态,
tsp.sea_plan_no sea_plan_no, -- 海运计划号,
tsp.ship_company_order_no ship_company_order_no, -- 船公司订舱单号
tsp.book_space_success_flag_desc book_space_success_flag_desc, -- 是否订舱成功,
tsp.plan_date plan_date, -- 计划日期,
tspd.materiel_code materiel_code, -- 物料编码,
tspd.materiel_name materiel_name, -- 物料名称,
CONCAT(ifnull(mm.materiel_spec,'')
,ifnull(mm.packing_weight_unit_desc,''),'/',ifnull(mm.packing_pieces_unit_desc,'')) as packing_spec_full_desc,
-- 规格,
pg.product_grade_name product_grade_name, -- 等级,
mm.base_unit_desc base_unit_desc, -- 单位
tspd.product_grade_id
FROM tran_sea_plan tsp
LEFT JOIN tran_sea_plan_detail tspd ON tsp.sea_plan_id = tspd.sea_plan_id
LEFT JOIN mst_warehouse start_mw ON start_ml.location_id = start_mw.location_id
AND start_mw.organization_id = tsp.organization_id
LEFT JOIN mst_carrier mc ON tsp.ship_company_id = mc.carrier_id
<where>
<trim prefixOverrides="and">
<!-- <trim prefix="WHERE" prefixOverrides="AND"> 与上面等价 -->
<if test="queryVo.seaPlanNo != null and queryVo.seaPlanNo != ''">
AND tsp.sea_plan_no LIKE concat('%',#{queryVo.seaPlanNo}, '%')
</if>
<if test="queryVo.organizationId != null and queryVo.organizationId != ''">
AND tsp.organization_id = #{queryVo.organizationId}
</if>
<if test="queryVo.status != null and queryVo.status.size() >0">
AND tsp.status IN
<foreach collection="queryVo.status" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</if>
<if test="queryVo.createTimeList != null and queryVo.createTimeList.size() == 2">
AND tsp.create_time
BETWEEN #{queryVo.createTimeList[0] } AND #{queryVo.createTimeList[1] }
</if>
<choose>
<when test="isUpdate !=null ">
AND tsp.create_time = #{isUpdate, jdbcType=INTEGER}
</when>
<when test="isDelete != null">
AND tsp.create_time = #{isDelete, jdbcType=INTEGER}
</when>
<otherwise>
AND tsp.create_time NOT NULL
</otherwise>
</choose>
<if test=" userName != null and userName !="" ">
<bind name= " userNameLike " value = "'%'+ userName + '%'"/>
and username like #{userNameLike}
</if>
</trim>
</where>
ORDER BY
tsp.sea_plan_no DESC
</select>
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
<update id="updateAuthorIfNecessary2">
update Author
<trim prefix="SET" suffixOverrides=",">
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</trim>
where id=#{id}
</update>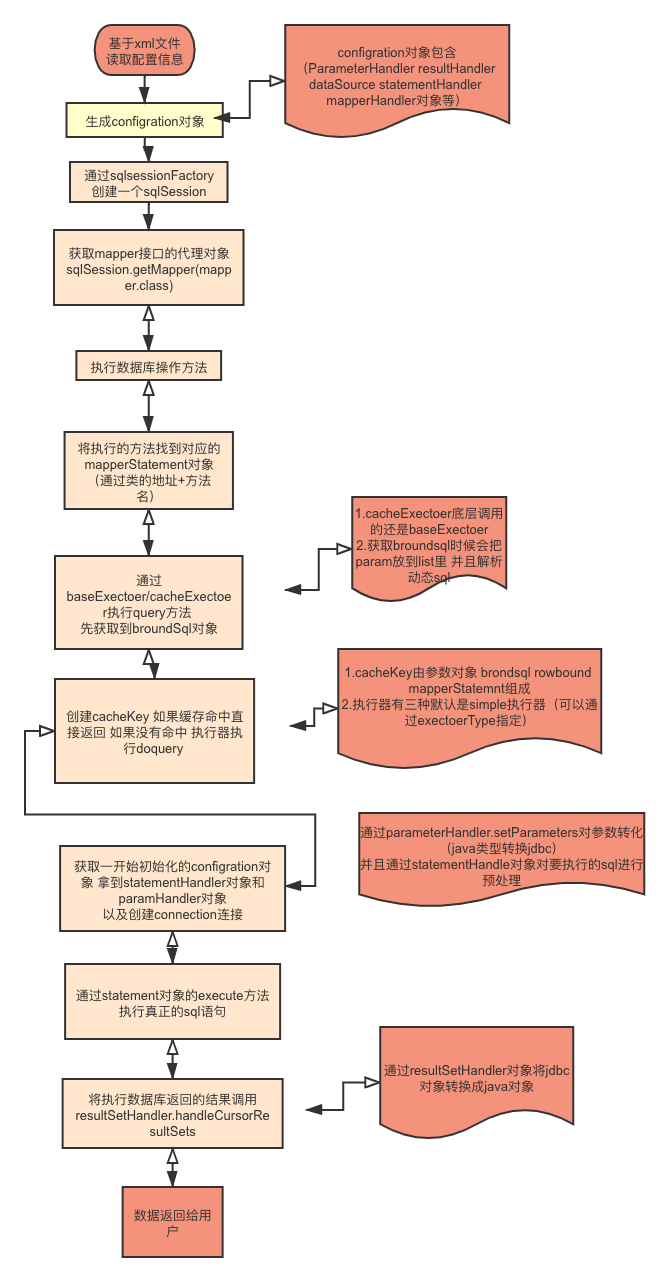
- mapper.xml中的配置⽂件⾥的每条sql语句,每一个
<select>、<insert>、<update>、<delete>标签,都会被解析为带有Id信息的一个个MappedStatement对象,再通过⼀个HashMap集合保存起来。 - Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个MappedStatement。
- 执⾏getMapper()⽅法,判断是否注册过mapper接⼝,注册了就会使⽤mapperProxyFactory去⽣成代理类MapperProxy执⾏⽬标⽅法时,会调⽤MapperProxy代理类的invoke()⽅法
- 此时会使用boundSql和对应的mapperStatement构造cacheKey,先进行缓存查询,命中直接返回。缓存
Map<Method, MapperMethodInvoker> methodCache = - 缓存无命中,则创建connect连接,通过statement对象执行execute方法。
- 执⾏execute()⽅法返回结果使用resultSetHandler进行结果集的封装,添加到缓存中,最后返回结果。
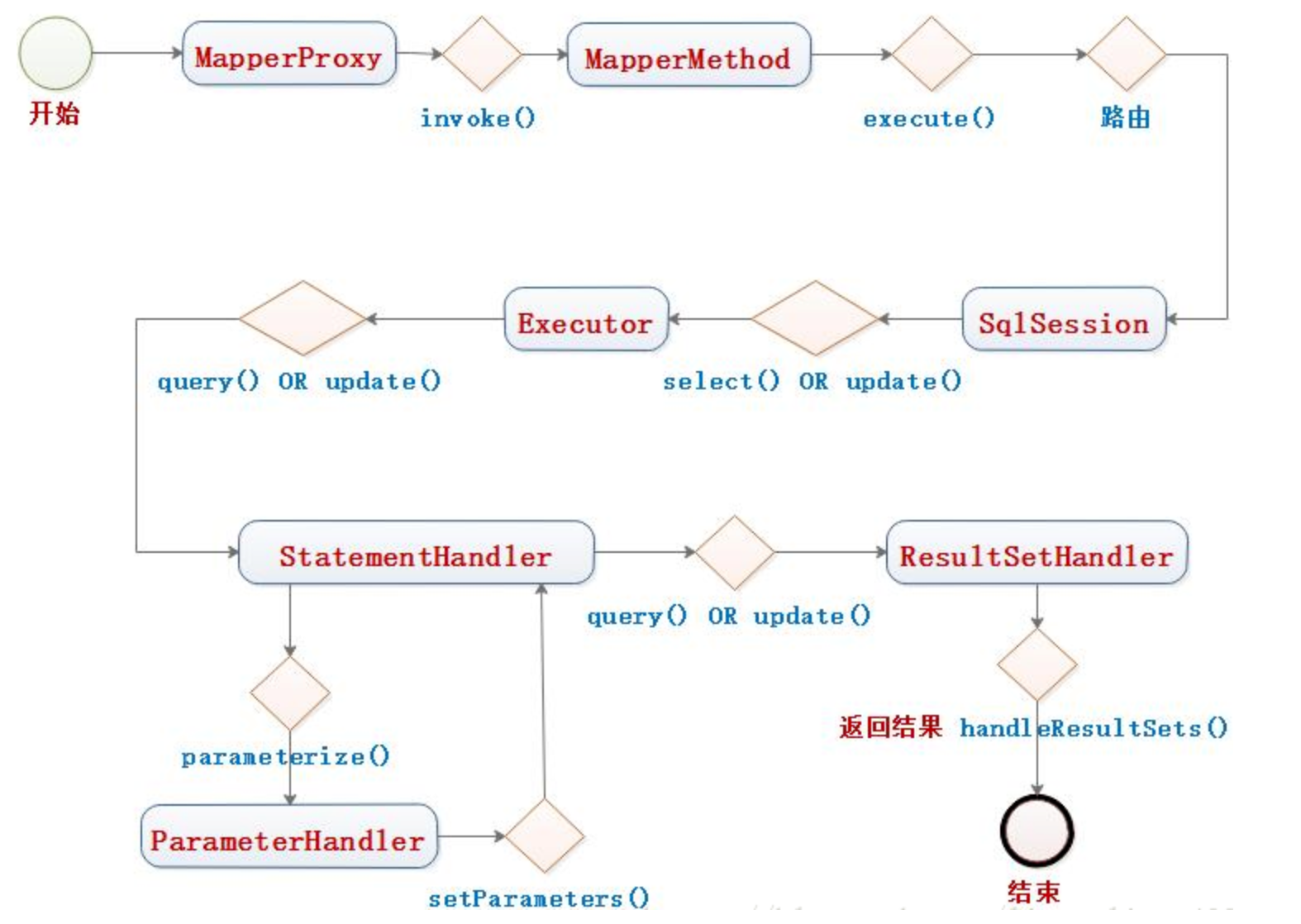
- 四大组件:StatementHandler、Executor、ParameterHandler、ResultSetHandler
下面的执行流程简要描述,只是为了辅助理解,相关初始化方法:
- Configuration中保存了,解析完xml的MapperStatement的HashMap
- Mybatis将Mapper接口注册到Spring的时候,将Mapper接口生成的BeanDefinition的beanClass设置为MapperFactoryBean
- Mapper接口初始化的时候通过MapperFactoryBean,进而调用MapperProxyFactory方法初始化及调用。
- MapperProxy代理调用时,通过匹配权限名+ID 获取MapperStatement对象
- MapperProxy进而MapperMethod的execute方法。
- SqlSession 执行的时候会获取Configuration中的四大组件进行sql执行。
- Configuration返回的四大组件是经过Interceptor代理封装过返回的代理对象。
Executor、ResultSetHandler、StatementHandler、ParameterHandler,这是Mybatis中的四大对象,也是拦截器的切入点。我们可以基于这四大对象的方法进行增强。因为这四个都是接口,我们可以利用动态代理进行方法的增强。
org.apache.ibatis.session.Configuration类,在新建接口对象的时候,通过调用interceptorChain:拦截器执行链的plugin方法,返回被拦截器包装后的代理对象。 因此对象调用的时候,会判断方法是否拦截进而进入拦截器的方法。
public class Plugin implements InvocationHandler {
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
}- ${}是 Properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。
- #{}是 sql 的参数占位符,MyBatis 会将 sql 中的#{}替换为?号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的?号占位符设置参数值,比如 ps.setInt(0, parameterValue).
- 不转义字符串,有风险,同时存在sql注入.
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态 sql 的 9 个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为 sql 片段标签,通过标签引入 sql 片段
- 在 MyBatis 中,每一个
<select>、<insert>、<update>、<delete>标签,都会被解析为带有Id信息的一个个MappedStatement对象。 - Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个MappedStatement。举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到 namespace 为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。
- Dao 接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
- Dao 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行MappedStatement所代表的 sql,然后将 sql 执行结果返回。
MyBatis的分页有两种,一种是使用 RowBounds 对象进行分页,另一种是使用PageHelper进行分页
- 使用 RowBounds 对象分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页,对于数据量大的情况,使用这种分页方式会浪费内存
- 使用PageHelper 进行分页,它是在StatementHandler之前进行拦截,对MappedStatement进行分页sql的拼接操作,PageHelper只对紧跟着的第一个SQL语句起作用.
- 另外可以使用mybatis插件,声明拦截器进行sql的处理
@Intercepts({
@Signature(type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class,
CacheKey.class, BoundSql.class}),
@Signature(type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class DataPermissionInterceptor implements Interceptor {} 答:第一种是使用标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用 sql 列的别名功能,将列别名书写为对象属性名,比如 T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写
关联对象查询,有两种实现方式:
- 一种是使用嵌套查询,在resultMap中使用association标签关联嵌套查询的sql语句。
<association property="way" column="wayId" javaType="com.whx.bus.entity.Way" select="selectWayById">
- 另一种是使用 标签指定resultMapId,将关联查询的记录映射到集合List中 - 去重复的原理是标签内的子标签,指定了唯一确定一条记录的 id 列,MyBatis 根据列值来完成 100 条记录的去重复功能,可以有多个,代表了联合主键的语意。
- 答:不同的 Xml 映射文件,如果配置了 namespace,那么 id 可以重复;如果没有配置 namespace,那么 id 不能重复
MyBatis 有三种基本的 Executor 执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。
- ReuseExecutor:执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。
- BatchExecutor:执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
- 作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
- Mybatis的默认执行器是SimpleExecutor,需要配置在创建SqlSession对象的时候指定执行器的类型即可。
<resultMap>标签会被解析为 ResultMap 对象,其每个子元素会被解析为 ResultMapping 对象。
每一个<select>、<insert>、<update>、<delete>标签均会被解析为 MappedStatement 对象。
标签内的 sql 会被解析为 BoundSql 对象。
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取
而 MyBatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
- 编写sql方面:hibernate不需要自己写sql语句,只需要写hql语句。而mybatis需要自己在配置文件中写sql语句,对开发人员的sql要求较高。
- sql优化方面:由于hibernate自动生成sql语句,生成的语句开发人员不易优化。而mybatis的sql完全体现在配置文件中,就便于优化。
- 数据库迁移方面:由于hibernate的sql是自动生成的,会根据不同的数据库生成对应的语法,迁移性较高。而mybatis的因为都是写在配置文件,迁移数据库,就可能造成语法不支持的情况。
- 日志方面:hibernate拥有完整的日志系统,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等。而mybatis仅有基本的记录功能。
- 缓存方面:hibernate有更好的二级缓存机制,可以使用第三方缓存。而mybatis支持两级缓存,实际应用中应用性不高。
- mybatis一级缓存sqlSession级的缓存。二级缓存Mapper级别的缓存。
- hibernate一级缓存session级别的。Hibernate二级缓存是SessionFactory级的缓存。 SessionFactory的缓存分为内置缓存和外置缓存
一级缓存的作用域是SQlSession, Mabits默认开启一级缓存。 在同一个SqlSession中,执行相同的SQL查询时;第一次会去查询数据库,并写在缓存中,第二次会直接从缓存中取。 当执行SQL时候两次查询中间发生了增删改的操作,则SQLSession的缓存会被清空。
- Mybatis的内部缓存使用一个HashMap,key为Statement Id + Offset + Limit + Sql + Params语句。Value为查询出来的结果集映射成的java对象。 SqlSession执行insert、update、delete等操作commit后会清空该SQLSession缓存。
- ① select * from table limit 2,1; //含义是跳过2条取出1条数据
- ② select * from table limit 2 offset 1; //含义是从第1条数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条。
- 一级缓存脏读:对于不同的sqlsession A与B, A做update操作,只能刷新A自己的一级缓存,无法刷新B的一级缓存。所以,如果A与B操作同一条记录,就会有脏读。
- 一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
二级缓存作用域是Mapper级别的,默认是没有开启。MyBatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别。
- 二级缓存脏读:在两个不同的mapper中都涉及到同一个表的增删改查操作,当其中一个mapper对这张表进行查询操作,此时另一个mapper进行了更新操作刷新缓存,然后第一个mapper又查询了一次,那么这次查询出的数据是脏数据。
- MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- mybatis:查询时,先进行二级缓存执行流程后,就会进入一级缓存的执行流程。(mapper级别的缓存可能是其他旧的sqlsession更新的,自己的sqlsession若存在缓存,则为较新的缓存。)
总结:在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据
- 美团技术团队mybatis缓存分析:https://tech.meituan.com/2018/01/19/mybatis-cache.html
- 流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。
- 流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架(mybatis)就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
// Cursor 还提供了三个方法:
// 1. isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;
// 2. isConsumed():用于判断查询结果是否全部取完。
// 3. getCurrentIndex():返回已经获取了多少条数据
// 正常使用方案1 , 使用sql session
try (
SqlSession sqlSession = sqlSessionFactory.openSession(); // 1
Cursor<Foo> cursor =
sqlSession.getMapper(FooMapper.class).scan(limit) // 2
) {
cursor.forEach(foo -> { });
}
}
// 方案2,使用编程式事务 TransactionTemplate
// 方案3,使用声明式事务 @Transaction
- Builder模式,例如SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder、CacheBuilder;
-
SqlSessionFactoryBuilder会调用XMLConfigBuilder读取所有的MybatisMapConfig.xml和所有的*Mapper.xml文件,构建Mybatis运行的核心对象Configuration对象,然后将该Configuration对象作为参数构建一个SqlSessionFactory对象。
-
- 模板方法模式,例如BaseExecutor和SimpleExecutor,还有BaseTypeHandler和所有的子类例如IntegerTypeHandler;
- 工厂模式,例如SqlSessionFactory、ObjectFactory、MapperProxyFactory;
- 单例模式,例如ErrorContext和LogFactory;
- 代理模式,Mybatis实现的核心,比如MapperProxy、ConnectionLogger,用的jdk的动态代理;还有executor.loader包使用了cglib或者javassist达到延迟加载的效果;
- 组合模式,例如SqlNode和各个子类ChooseSqlNode等;
- 适配器模式,例如Log的Mybatis接口和它对jdbc、log4j等各种日志框架的适配实现;
- 装饰者模式,例如Cache包中的cache.decorators子包中等各个装饰者的实现;
- 迭代器模式,例如迭代器模式PropertyTokenizer;
用来指定xml中#{} 指定的参数名。
-
对于常规的参数映射,参数解析直接按照名称解析对应的K-V对应关系。
-
对于对象类型传递,对于单个对象参数传递,则直接解析成class,xml文件需要直接指定class中的字段
demoId,不能用参数前缀名demo.demoId -
对于多对象参数的传递,参数可以使用别名代替。
-
参数解析方法:
class MapperMethod{
public Object convertArgsToSqlCommandParam(Object[] args) {
return paramNameResolver.getNamedParams(args);
}
}- 参数获取方法
class MetaObject{
public Object getValue(String name) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
return null;
} else {
return metaValue.getValue(prop.getChildren());
}
} else {
return objectWrapper.get(prop);
}
}
}