敏感词过滤设计
1. 数据量预估
2. DFA算法 (Deterministic Finite Automaton)
2.1. 数据更新
2.2. 相关资料:
3. Elasticsearch 方案 (未实践)
4. 监控
5. 进阶的设计点
- 直接将敏感词组织成String后,利用indexOf方法来查询。
- 传统的敏感词入库后SQL查询。
- 利用Lucene或者Elasticsearch建立分词索引来查询。
- 利用DFA算法来进行
方法1和方法2在性能上基本无法满足系统高效处理消息的需求,放弃。
方法3,采用Lucene建立本地分词索引,将消息内容分词后,在索引库里搜索。这个方法较复杂,且分词效率也不会很高,放弃。
java中只要是字符,不管是数字还是英文还是汉字,都占两个字节,都是一个char。
假如存在10w条的词汇: 10w 数据量的敏感词汇,假设敏感词的平均长度为10个中文字符
- 数据量:
10w*10*2/1024/1024 = 1.9M
完全可以使用内存的方案来解决,即直接将所有词汇load到内存中。
假如存在上千万条的词汇,那么在上述数据量 1.9M1000n 会需要几个G的内存资源就要考虑非内存的其他的方案。
基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测。
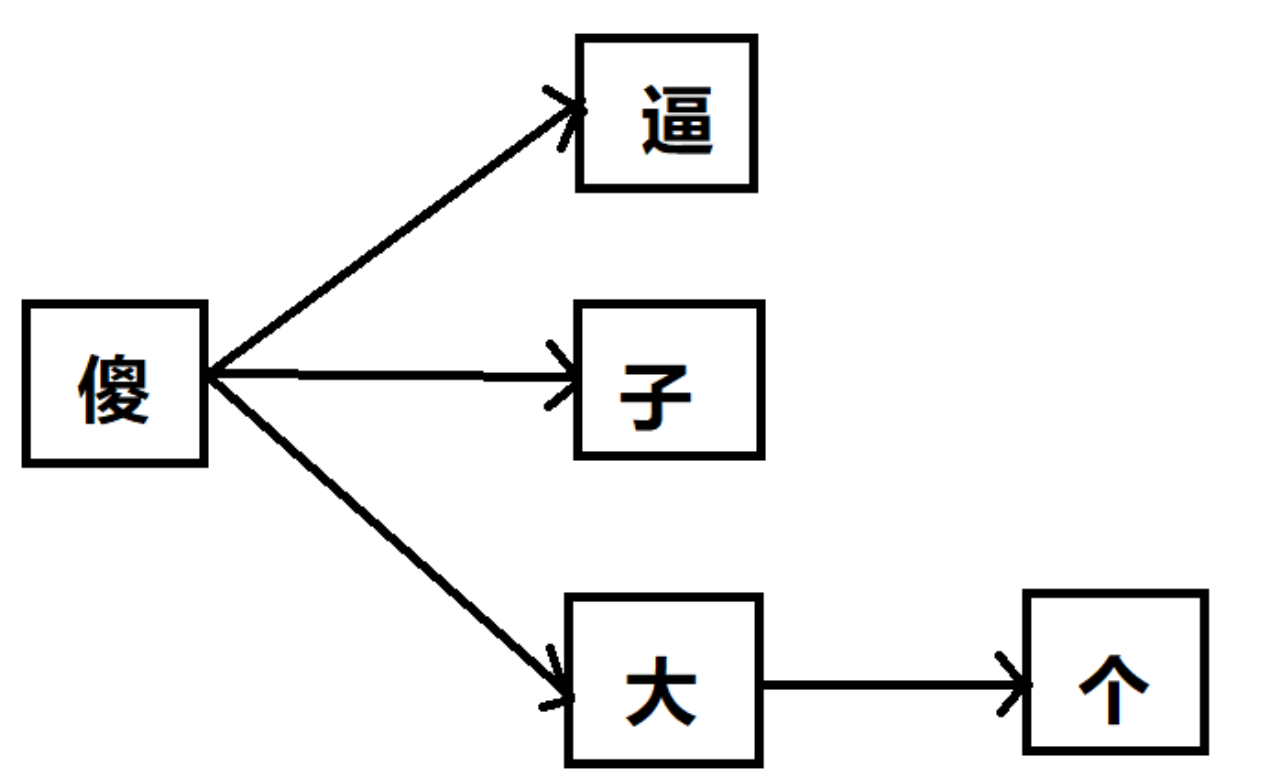 将敏感词库中相同前缀的词构建成了一个树形结构
将敏感词库中相同前缀的词构建成了一个树形结构
在java 中以HashMap结构进行存储
{
"x": {
"逼": {
"isEnd": "Y"
},
"子": {
"isEnd": "Y"
},
"大": {
"isEnd": "N",
"个": {
"isEnd": "Y"
}
}
}
}
- https://yq.aliyun.com/articles/622759
- https://www.cnblogs.com/twoheads/p/11349541.html
- http://www.yunliaoim.com/im/1149.html
- 采用ES作为禁词库 千万级数据检索时间在毫秒级满足需求
- 不适用分词器需要完整匹配 分词后很多词都是合法的 组合之后才是敏感词
- 被过滤文本内容分词不完整 利用IK分词器分词结果不适合现在的业务场景
- 只能采用字符串分割的方式来匹配ES库
- 带来的问题就是效率低下同步多线程下千字也需要将近4秒
- 考虑采用异步模式来解决大数据量需要审核状态
IK分词器 : IK做为中文分词
监控敏感词命中率。如命中率很高则查看具体的内容是否有问题。
- 汉字拆分(*): 把汉字拆分后, 逃避检查, 比如“*教” ==》” x孝文“。
- 跳字处理(引入编辑距离的概念): 中间插入特殊的字符==》"x-产——当"。
- 严格 HTML 过滤(*) : 通过 HTML 的标签, 实现逃避检查
<font color="red">x</font> <font color="red">民</font> <font color="red">当</font> (显示成: x民当) - 简体/繁体转换: 通过写入繁体字逃避检查。
- 组合判断(*): 对于特殊的人物名字, 需要通过组合方式判定, xzedong|x越进|独 x裁 这样的文本同时出现才能判断违禁。
- 过滤评分体系(Bayers): 建立一个违禁评分题体系。
- 故意逃避检查的惩罚系统:包括插字,插入 tag,汉字拆分,繁简体混合等种种伪装系统。
- 高亮方法:能够高亮“x车仑功”“x —轮—功”“
<font color="red">x</font> <font color="red">民</font> <font color="red">当</font> (显示成: x民当)”等种种特殊伪装关键字。