Spark
1. spark-shell
2. 手工提交任务
2.1. 启动
2.2. scala demo
3. spark 简介
3.1. 组件
3.2. 与Hadoop 对比
4. RDDs(Resilient distributed datasets, 弹性分布式数据集)
4.1. TransFormation
4.2. Action
4.3. 创建RDD
4.4. 缓存RDD的方法
4.5. shuffle操作
4.6. 相关资料
5. 集群架构
6. Spark SQL
6.1. 基础数据结构
6.2. 执行流程
6.3. 多数据源支持
6.3.1. SQL Databases、
7. 相关资料
8. CCAR项目架构
8.1. spark任务监控
[root@VM-0-16-centos local]# head tmp.log
hello spark
sprak 1
spark 3
scala> var lines = sc.textFile("/usr/local/tmp.log")
lines: org.apache.spark.rdd.RDD[String] = /usr/local/tmp.log MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count()
res0: Long = 3
scala> lines.first
res1: String = "hello spark "
scala>
./sbin/start-master.sh
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://xxx:7077
./bin/spark-submit --master spark://xxx:7077 --class WordCount /root/spark-demo.jar
-
master
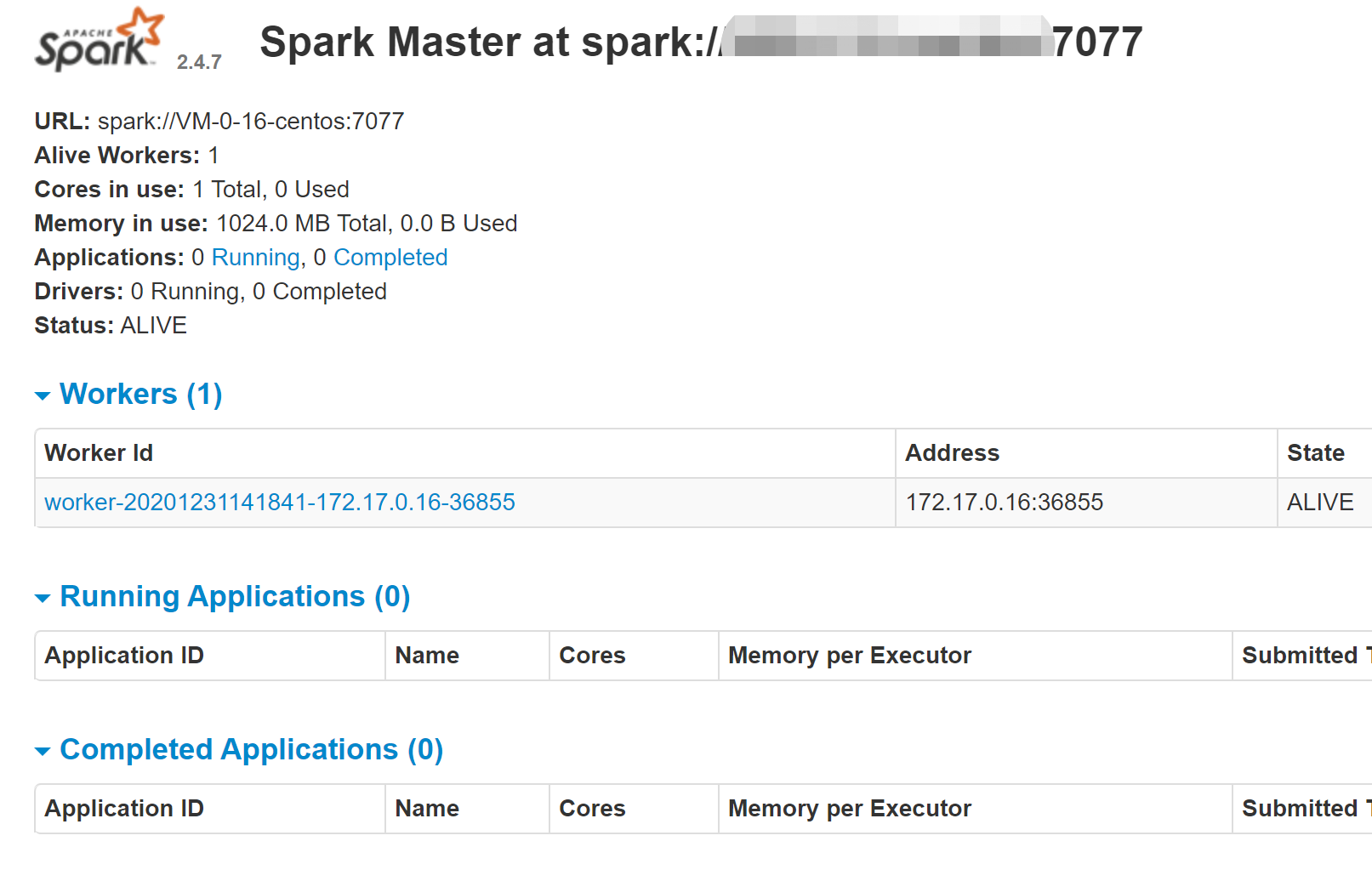
-
submit job
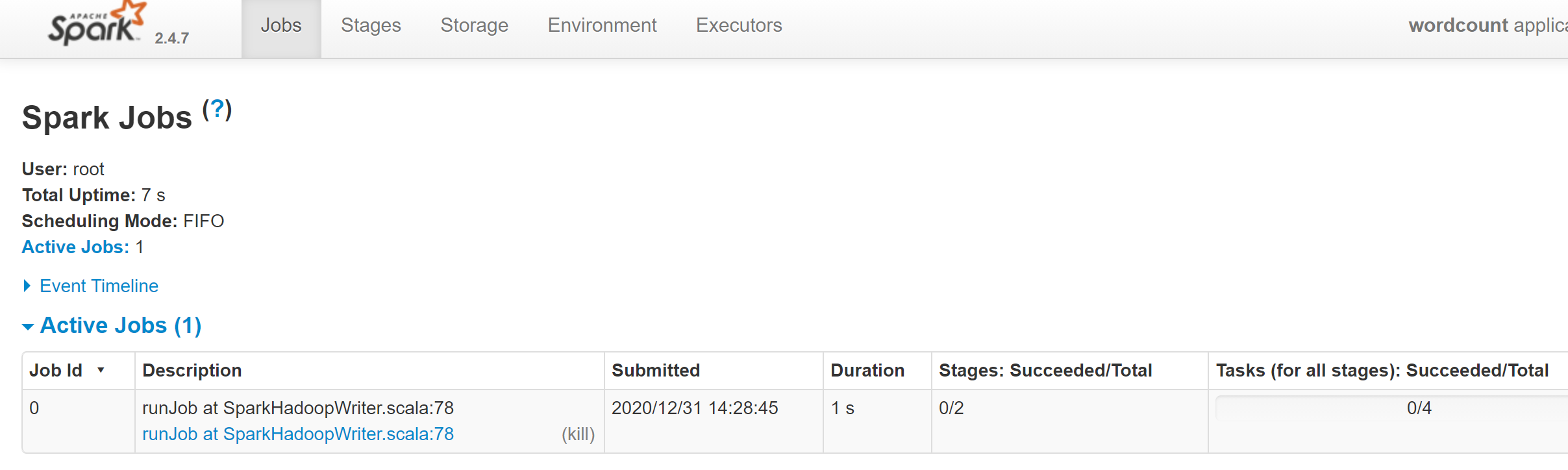
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount")
val sc = new SparkContext(conf)
val input = sc.textFile("/usr/local/tmp.log")
val lines = input.flatMap(line => line.split(" "))
val count = lines.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
val output =count.saveAsTextFile("/usr/local/tmpResult")
}
}
打成jar包,使用scale 手工提交任务。
Spark 是一个快速、通用且高度开发的数据处理平台
快速:
- 扩充了MapReduce的计算模型,相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升。
- 基于内存存储计算
处理几T或几P的数据量的时候,处理时间是秒级或者分钟级别。
MapReduce原理(分治思想):MapReduce 会对输入先进行切分,这一步其实就是分治中分的过程。切分后不同部分就会让不同的机器去执行 Map 操作。而后便是 Shuffle,这一阶段会将不相同的单词加到一起,最后再进行 Reduce 。
通用:
- 提供多语言的API
- 提供了批处理,迭代式计算,交互式查询和流处理
- 降低了集群的维护成本
高度开放:多语言支持,目前支持的有 Java,Scala,Python 和 R;
Spark Core:
- spark基本功能,包括任务调度、内存管理、容错机制
- 内部定义了RDDS(弹性分布式数据集)
- 提供了很多APIs来创建及修改这些RDDs
- Spark Streaming、Spark SQL、Graphx 继承了RDDs的API
Spark SQL:是处理Spark 处理结构式数据的库,就想Hive SQL及MySQL一样,应用场景,企业中做报表统计
Spark Steaming:
- 是实时数据流处理组件,类似Storm
- Spark Streaming 提供了API来操作实时流数据
- 应用场景,企业中用来从Kafka接受数据做实时统计
Mlib: 包含机器学习功能的包,Machine leaning lib 包含分类、聚类、回归等,还包括模型评估和数据导入。
Graphx: 是处理图的库,并进行图的并行计算。
Cluster Managers: 集群管理,Spark 自带一个集群管理是单独调度器。常见的其他集群管理包括Hadoop YARN,Apache Mesos
Spark 的组件之间都是紧密集成的,基于Spark底层优化了,其紧密继承的组件也会得到相应优化。紧密集成,节省了各个组件组合使用时的部署、测试时间、
Hadoop 数据落硬盘,比较适合离线处理和对时效性要求不高的场景
Spark 基于内存适合时效性要求高的场景,计算时间为几秒~几分。也可以应用于机器学习领域。
RDD 是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性:
- 一个 RDD 由一个或者多个分片(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- 血统关系图:Spark 维护这RDDs之间的依赖关系和创建关系,叫血统关系图。如 rdd1 -> filter -> rdd2,若rdd2丢失可以快速恢复。
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
- 延迟计算:第一次进行action操作的,或者必要的时候才会加载进去。
- RDD 可以把读取的数据,比如读取到500G,可以分发到不同节点上计算
- RDD 拥有一个用于计算分区的函数 compute;
- Spark中,所有的计算都是通过RDDs的创建、转换、操作完成。
SparkContext对象代表和一个集群的连接
分片:每个分片包括一部分的数据,partitions可在集群上的不同节点上计算。分片是Spark并行处理的单元,Spark顺序的,并行的处理分片
- map() 接受函数,把函数应用到RDD的每个元素,返回新的RDD
- filter() 进行数据过滤
- flatMap() 对每个输入元素,通过函数将每行的多个输出元素压扁后输出一个新的RDD。
- distinct() 去重
- union()并集
- intersections():交集
- subtract()
- reduceByKey():把相同的key结合
- groupByKey(): 使用key进行分组
- mapValues(): 函数处理值
- flatMapValue()
- keys()
- values()
combineByKey(createCombiner, mergeValue, mergeCombiners, partitioner): 返回类型与可以输入类型不一致,遍历partition中的元素,元素的key要么见过 要么没见过
- createCombiner:作用于新元素
- mergeValue: 已存在的元素值处理函数
- mergeCombiners:合计每个分区结果的时候使用。
在RDD上计算返回结果
reduce():接收一个函数,作用在RDD两个类型相同的元素上,返回新元素。 collect(): 返回RDD内存,需要单机内存能够容纳下。大数据的场景下,可以使用saveAsTextFile() action等
- take(n) : 返回n个元素,无序返回
- top(n): 返回最大的元素
- foreach:遍历
- 现有集合创建
- 引用外部存储系统中的数据集
引用外部存储系统中的数据集,例如本地文件系统,HDFS,HBase 或支持 Hadoop InputFormat 的任何数据源。
val fileRDD = sc.textFile("/usr/file/emp.txt")
Spark 支持多种缓存级别 :
| Storage Level (存储级别) |
Meaning(含义) |
|---|---|
MEMORY_ONLY |
默认的缓存级别,将 RDD 以反序列化的 Java 对象的形式存储在 JVM 中。如果内存空间不够,则部分分区数据将不再缓存。 |
MEMORY_AND_DISK |
将 RDD 以反序列化的 Java 对象的形式存储 JVM 中。如果内存空间不够,将未缓存的分区数据存储到磁盘,在需要使用这些分区时从磁盘读取。 |
MEMORY_ONLY_SER |
将 RDD 以序列化的 Java 对象的形式进行存储(每个分区为一个 byte 数组)。这种方式比反序列化对象节省存储空间,但在读取时会增加 CPU 的计算负担。仅支持 Java 和 Scala 。 |
MEMORY_AND_DISK_SER |
类似于 MEMORY_ONLY_SER,但是溢出的分区数据会存储到磁盘,而不是在用到它们时重新计算。仅支持 Java 和 Scala。 |
DISK_ONLY |
只在磁盘上缓存 RDD |
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc |
与上面的对应级别功能相同,但是会为每个分区在集群中的两个节点上建立副本。 |
OFF_HEAP |
与 MEMORY_ONLY_SER 类似,但将数据存储在堆外内存中。这需要启用堆外内存。 |
缓存数据的方法有两个:persist 和 cache 。cache 内部调用的也是 persist,它是 persist 的特殊化形式,等价于 persist(StorageLevel.MEMORY_ONLY)。示例如下:
在 Spark 中,一个任务对应一个分区,通常不会跨分区操作数据。但如果遇到 reduceByKey 等操作,Spark 必须从所有分区读取数据,并查找所有键的所有值,然后汇总在一起以计算每个键的最终结果 ,这称为 Shuffle。

RDD 的引用,则垃圾回收可能在很长一段时间后才会发生,这意味着长时间运行的 Spark 作业可能会占用大量磁盘空间,通常可以使用 spark.local.dir 参数来指定这些临时文件的存储目录。
####导致Shuffle的操作
由于 Shuffle 操作对性能的影响比较大,所以需要特别注意使用,以下操作都会导致 Shuffle:
- 涉及到重新分区操作: 如
repartition和coalesce; - 所有涉及到 ByKey 的操作:如
groupByKey和reduceByKey,但countByKey除外; - 联结操作:如
cogroup和join。
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |

执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
DataFrame:为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点,具备强类型的特点,同时支持 Lambda 函数,但只能在 Scala 和 Java 语言中使用。
对三者做一下简单的总结:
- RDDs 适合非结构化数据的处理,而 DataFrame & DataSet 更适合结构化数据和半结构化的处理;
- DataFrame & DataSet 可以通过统一的 Structured API 进行访问,而 RDDs 则更适合函数式编程的场景;
- 相比于 DataFrame 而言,DataSet 是强类型的 (Typed),有着更为严格的静态类型检查;
- DataSets、DataFrames、SQL 的底层都依赖了 RDDs API,并对外提供结构化的访问接口。

DataFrame、DataSet 和 Spark SQL 的实际执行流程都是相同的:
- 进行 DataFrame/Dataset/SQL 编程;
- 如果是有效的代码,即代码没有编译错误,Spark 会将其转换为一个逻辑计划(解析验证);
- Spark 将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark 然后在集群上执行这个物理计划 (基于 RDD 操作) 。
Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。
- CSV
- JSON
- Parquet
- ORC
- JDBC/ODBC connections
- Plain-text files
读取全表数据示例如下,这里的 help_keyword 是 mysql 内置的字典表,只有 help_keyword_id 和 name 两个字段。
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver") //驱动
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql") //数据库地址
.option("dbtable", "help_keyword") //表名
.option("user", "root").option("password","root").load().show(10)
val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords"""
spark.read.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root").option("password", "root")
.option("dbtable", pushDownQuery)
.load().show()
//输出
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 10| ALTER|
| 11| ANALYSE|
| 12| ANALYZE|
| 13| AND|
| 14| ARCHIVE|
| 15| AREA|
| 16| AS|
| 17| ASBINARY|
| 18| ASC|
| 19| ASTEXT|
+---------------+-----------+
java in spark spark 中文文档 MapReduce 思想
敏感资产相关数据,是结构化的数据,数据之间以树形节点形成依赖关系。
- 使用spark sql, 通过sparkSession 连接CSV的本地文件数据源
- 使用模板模式,定义AbstractSparkPlaner 的抽象类,用于加载CSV文件,返回DataSet数据对象。
- 对于需要依赖的数据节点,首先会触发依赖节点的加载,然后使用ConcurrentHashMap存储依赖的数据节点。
- 使用AOP切面基于注解,对spark任务进行监控。
- 在sparkSession中注册监听类SparkListener
- 切面配合Spring 的事务驱动模型applicationEventPublisher,发布监控相关的事件
- 服务类使用@EventListener注解,监听对应的事件,比如相关的mango日志记录操作等