Second Channel For RDB #11678
Comments
|
Thanks for your report, it's a good idea and I have thought about doing this too to solve the replication stream problem on fullsync stage. But I didn't finish it since there are two questions I can't figure it out.
|
|
few quick comments:
|
|
Just to add some small point to the discussion: |
|
@oranagra to you questions:
|
|
To @soloestoy question:
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The issue that is being addressed
During bgsave, the primary child process, sends an rdb snapshot to the replica. During this time any write command that the primary has to process is kept in the COB in order to be sent to the replica once bgsave is done.
If the save is taking for too long or write commands are coming in high frequency, the COB may reach its limits, causing full sync to fail.
By implementing a more efficient way to stream RDB data from primary to replica, the feature intends to not only reduce COB overrun, but also simplify the bgsave process.
Description
The primary will simultaneously send RDB and command stream during the full sync. The replica on the other hand will store the command stream in a local buffer to be streamed locally once new snapshot is loaded.
By doing so we will gain the following:
With this feature the commands streaming will be much faster at the replica side, making the time between the replica start responding to client to the time when the replica is completely up to data considerably shorter.
Alternatives we've considered
One connection for both data types
During fsync primary will use the connection to its replica to write both rdb and command stream. This will be done by adding a header as a prefix to each message indicating the message type.
Pros:
Cons:
Additional information
Preliminary results
We checked the memory influence of the feature, with 3gb size DB, and high write on primary we where able to move 80% of the used memory by the COB to the replica side.
Graph explanation:

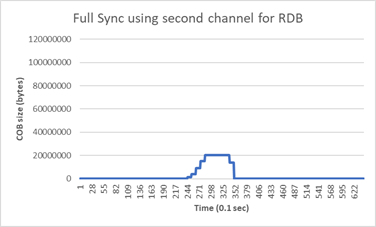
client_recent_max_output_bufferto measure the cob size, it shows the recent max so it only updates once every ~1 second.recent_max, also there is a continues write burst to the primary during this time, so although replica started reading from the primary COB, there are clients filling it.This is the impact on the replica buffer size. Same memory usage distributed between the primary and the replica (mostly the replica).

Design
Once we know full sync is needed:
Setup:
new-command <master_host> <master_port> --rdb <path_to_replica_disk> +send-end-offsetasking for snapshot with new--rdb sub command (similar to rdb command but diskless on primary side), so primary child process will send the end offset of the new RDB before the RDB itself.
Full Sync:
PSYNC <master_repl_id> <rdb_end_offset>+1Recovery
The text was updated successfully, but these errors were encountered: