cluster can't failover when multiple nodes fail. #6871
Comments
|
It's pretty bad if a cluster can't survive a machine crash hosting a fraction of the nodes. Too bad we don't have a test case simulating this. I'm guessing:
@madolson Have you seen this problem? Any idea why this happens? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I have 3 machine. Each machine has 20 Master and 20 Slave. So the cluster has 60 Master and 60 Slave.
cluster can't failover when i just shutdown a machine.(20 Master and 20 slave down) More than half of the nodes is alive.
And cluster can't failover when i stop 15 master and 15 slave.
Cluster failover successfully when i reduce number of down instances to 8 master and 8 slave.
Case of 15 master and 15 slave down:

The 3 ip such as 10.129.104.6 10.129.104.7 10.129.104.8. 15 master and 15 slave in 10.129.104.6 will be stoped.
It's strange that instances of other machines will be unavailable.
cluster info:
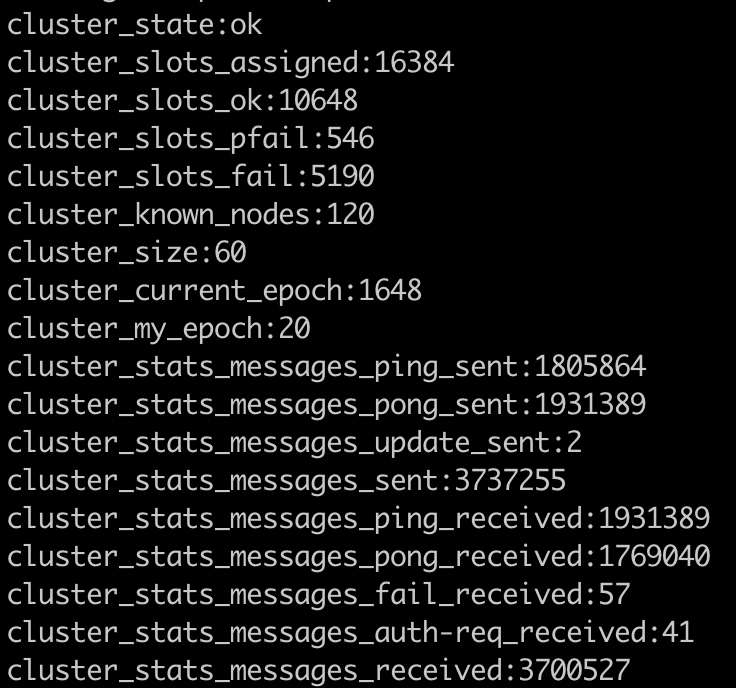
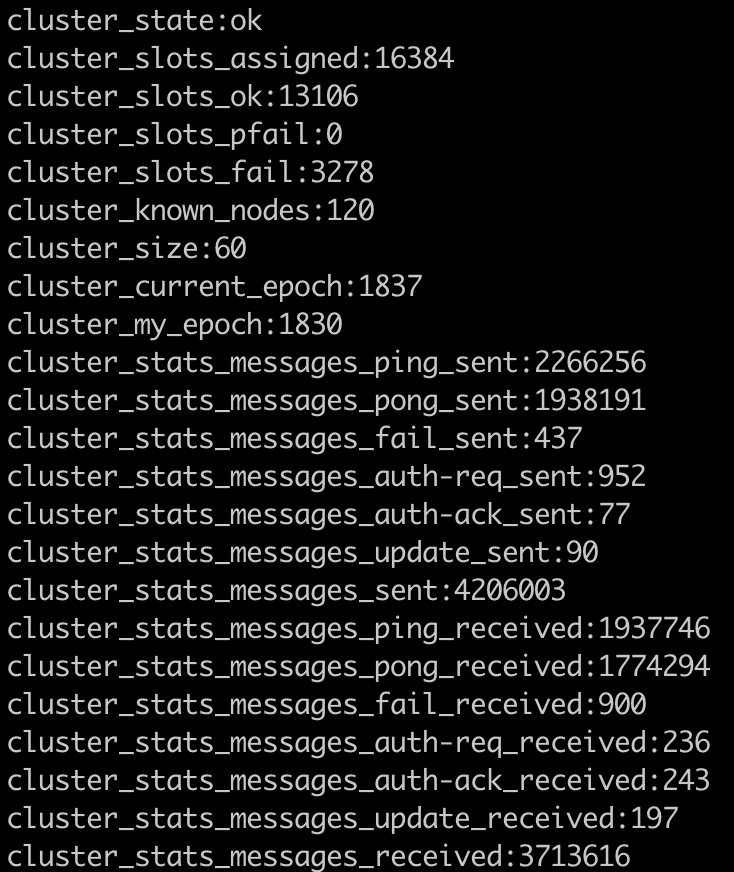
redis.log:

�There are some slots is not ok after 30 minutes.
redis.conf
daemonize no
protected-mode no
bind 10.129.104.6
dir /usr/local/redis-cluster5.0.3/data/redis-6379
pidfile /var/run/redis-cluster5.0.3/redis-6379.pid
logfile /usr/local/redis-cluster5.0.3/log/redis-6379.log
port 6379
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster5.0.3/conf/node-6379.conf
cluster-node-timeout 30000
cluster-require-full-coverage no
appendonly yes
maxmemory 8gb
maxmemory-policy volatile-lru
cluster-slave-validity-factor 0
The text was updated successfully, but these errors were encountered: