Enhance the reasoning of multimodal models with pipelines to synthesize VQA datasets.
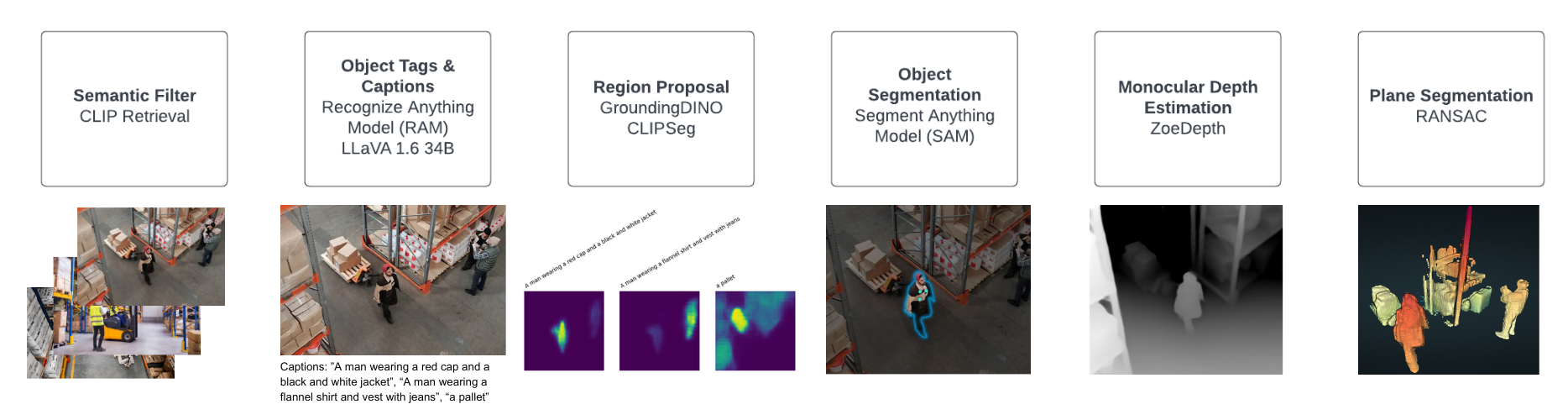
Inspired by SpatialVLM, this repo uses ZoeDepth to adapt Vision Langauge Models for spatial reasoning. The demos feature pipelines using LLaVA for object captioning and SAM for segmentation. One uses CLIPSeg for region proposal, while the other uses GroundingDINO.
Before running the demo scripts, ensure you have the following installed:
- Python 3.9 or later
- Docker, Docker Compose V2
- NVIDIA Container Toolkit
CLIPSeg-based SpatialVLM data processing (recommended):
cd tests/data_processing/
docker build -f clipseg_data_processing.dockerfile -t vqasynth:clipseg-dataproc-test .
docker run --gpus all -v /path/to/output/:/path/to/output vqasynth:clipseg-dataproc-test --input_image="warehouse_rgb.jpg" --output_dir "/path/to/output" GroundingDINO-based SpatialVLM data processing:
cd tests/data_processing/
docker build -f groundingDino_data_processing.dockerfile -t vqasynth:dino-dataproc-test .
docker run --gpus all -v /path/to/output/:/path/to/output vqasynth:dino-dataproc-test --input_image="warehouse_rgb.jpg" --output_dir "/path/to/output" The scripts will produce 3D point clouds, segmented images, labels, and prompt examples for a test image.
The main pipeline uses Docker Compose to process a directory of images into a VQA dataset including spatial relations between objects. The dataset follows conventions for training models like LLaVA. We recommend using an A10 GPU or larger for processing.
Make sure to update .env with the full path to your image directory and output directory. Then launch the pipeline with:
cd /path/to/VQASynth
docker compose -f pipelines/spatialvqa.yaml up --buildIn your designated output directory, you'll find a json file processed_dataset.json containing the formatted dataset.
Here are some examples:
 |
 |
 |
|---|---|---|
| Does the red forklift in warehouse appear on the left side of the brown cardboard boxes stacked? | How close is the man in red hat walking from the wooden pallet with boxes? | Does the man in blue shirt working have a greater height compared to the wooden pallet with boxes on floor? |
| Incorrect, the red forklift in warehouse is not on the left side of the brown cardboard boxes stacked. | The man in red hat walking is 60.13 centimeters from the wooden pallet with boxes. | Indeed, the man in blue shirt working is taller compared to the wooden pallet with boxes on floor. |
Here's a sample of warehouse images captioned with spatial relationships similar to the table above.
wget https://remyx.ai/assets/vqasynth/vqasynth_warehouse_spaces.zip
# Data is formatted for LLaVA fine-tuning
unzip vqasynth_warehouse_spaces.zip Once completed, you can follow this resource on fine-tuning LLaVa.
Check out our LLaVA 1.5 LoRA SpaceLLaVA and MobileVLM-based SpaceLLaVA-lite
Try SpaceLLaVA in Discord

We've hosted some notebooks visualizing and experimenting with the techniques included in this repo.
| Notebook | Description | Launch |
|---|---|---|
| Spatial Reasoning with Point Clouds | Visualize point clouds and evaluate spatial relationships |
This project was inspired by or utilizes concepts discussed in the following research paper(s):
@article{chen2024spatialvlm,
title = {SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities},
author = {Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brian and Driess, Danny and Florence, Pete and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei},
journal = {arXiv preprint arXiv:2401.12168},
year = {2024},
url = {https://arxiv.org/abs/2401.12168},
}