Replace Ragel tokenizer with String Scanner #4369
Conversation
ad3f08f
to
773cc72
Compare
|
By the way, I made the block quote string work the way the tests want it to work, but the way GraphQL-Ruby tokenizes block quotes doesn't match the way the reference implementation for JS tokenizes them. I was specifically checking the 10 quote test. In that case the JS tokenizer sees one triple quote block (the first 6 quotes), then an unterminated triple quote block (the following 3, then 1 quote, for a total of 4 quotes). I also looked at the |
|
Sorry, I didn't realize there were benchmarks in the repo. Here is master: This branch: Just to make comparison easier, I made a bar graph that compares them. The graph is
|
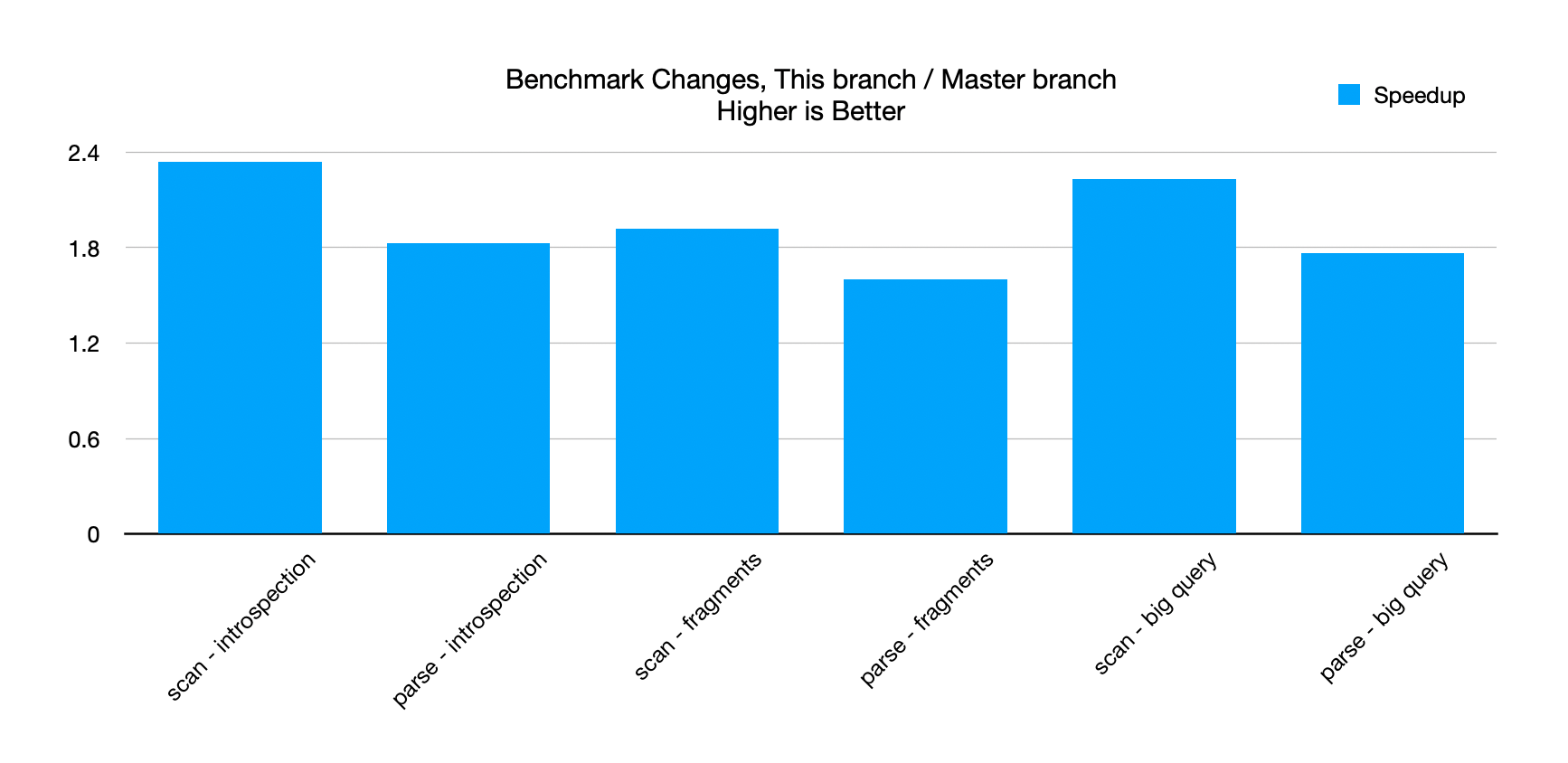
|
Just for fun I decided to try with YJIT too. Here are the results with YJIT:
|
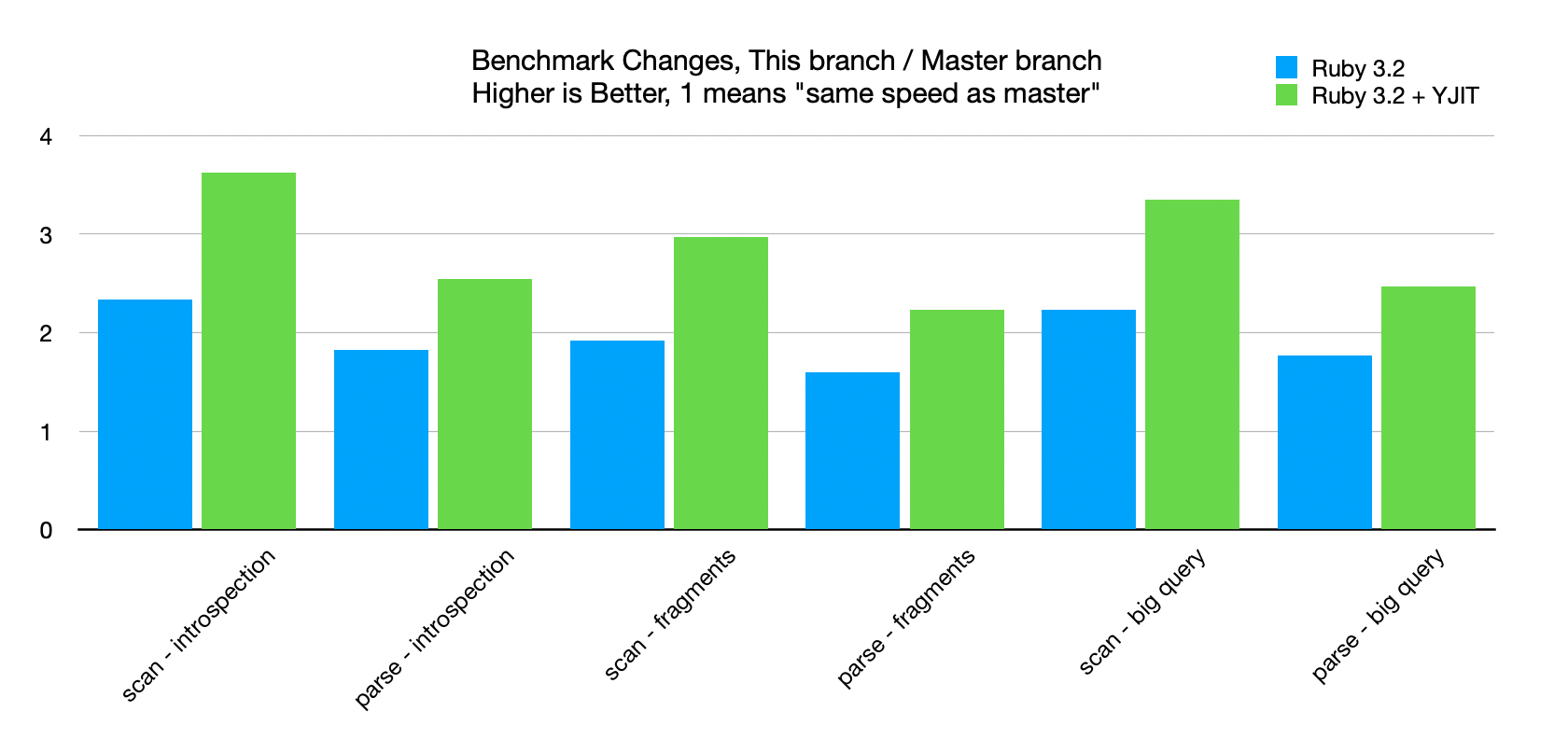
This commit replaces the Ragel tokenizer with a "hand written" string scanner based tokenizer. This tokenizer is about ~2x faster than the previous tokenizer. To test, I used this benchmark: https://gist.github.com/tenderlove/fdce1610a3eecd8426f5845391a6c373 On this branch: ``` $ ruby -I.:lib:spec bench.rb Warming up -------------------------------------- graphql 506.000 i/100ms Calculating ------------------------------------- graphql 5.090k (± 0.4%) i/s - 25.806k in 5.070096s ``` On master: ``` $ ruby -I.:lib:spec bench.rb Warming up -------------------------------------- graphql 284.000 i/100ms Calculating ------------------------------------- graphql 2.880k (± 0.4%) i/s - 14.484k in 5.029007s ``` To ensure compatibility I ran this tokenizer in parallel with the existing tokenizer and compared the results. There is one difference that I think is acceptable and that is when the tokenizer encounters unknown input. For example: ```ruby require "graphql/language/lexer" require "graphql/language/token" str = "😘" p GraphQL::Language::Lexer.tokenize(str) ``` Output on master is this: ``` $ ruby -I.:lib:spec test.rb [(UNKNOWN_CHAR "\xF0" [1:1]), (UNKNOWN_CHAR "\x9F" [1:2]), (UNKNOWN_CHAR "\x98" [1:3]), (UNKNOWN_CHAR "\x98" [1:4])] ``` Output on my branch is this: ``` $ ruby -I.:lib:spec test.rb [(UNKNOWN_CHAR "😘" [1:1])] ``` This is because Ragel only understands byte streams where Ruby knows we have a UTF-8 string. I didn't make many changes to the helper functions that were originally included in the Ragel parser. Now that we're not working with byte arrays, I think could probably improve the code in those helper functions too.
|
Thanks for sharing this work! Simpler and faster, sounds great to me. That's interesting about the divergence between this project and the reference implementation. Too bad 😖 If it becomes a problem, I'm definitely open to making this project match graphql-js. I plan to continue with #4366 since it's still an order of magnitude faster, but I see an advantage to maintaining both a plain-Ruby and a C implementation. |
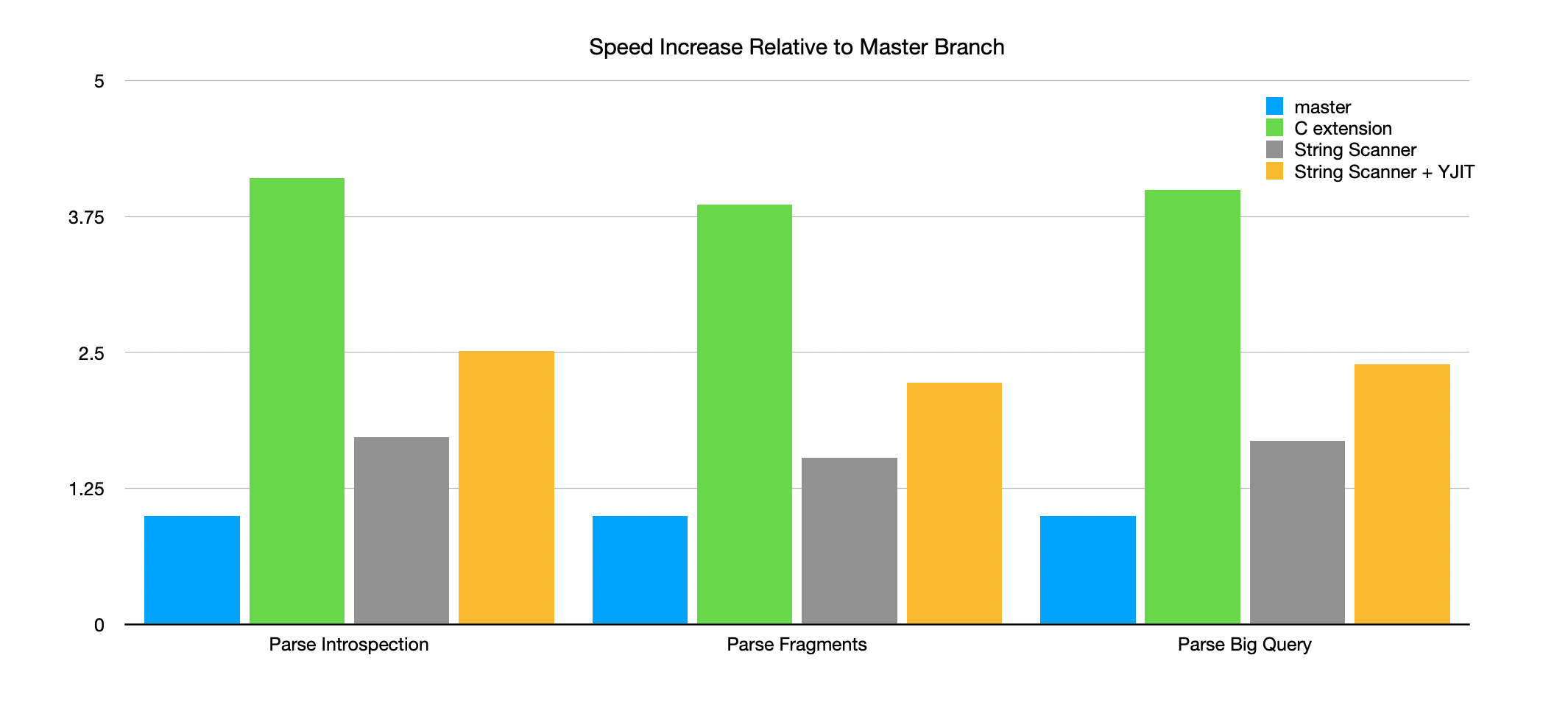
Makes sense. I have a vested interest in a good Ruby implementation because YJIT can speed up Ruby code. I ran the benchmarks on the the C branch too, but I'm only seeing 4x increase as compared to master?
I could be running the benchmarks wrong though. In general, I think it will be possible for YJIT to beat a C extension someday, so I'd be glad if a pure Ruby version sticks around. |
|
I'd also suggest making the c ext purely optional. As someone who maintain a bunch of C exts, you commonly get error report from users with weird compilation issues of all sorts. So having the possibility to just tell them to not use the c-ext is gold as a maintainer. It can be in the same repo, but shipped as a separate gem (e.g. like |
Ah yeah -- I should have clarified, it's just the scan-only benchmarks that show such a big speedup. But I added those in #4366. For the whole parse step, yes, I saw ~3x faster as well. (I'm investigating C for parsing, too: #4368)
Thanks for the suggestion, @byroot, I'll take a look at those Redis clients and try to set up something similar 👍 |
|
Thanks for this improvement! |
The rewritten lexer in #4369 removed UTF8 forced encoding. It's possible for applications to force encoding document strings themselves before passing it to the GraphQL gem, but it should be done at this layer to ensure that invalid encoding is properly handled.
The rewritten lexer in #4369 removed UTF8 forced encoding. It's possible for applications to force encoding document strings themselves before passing it to the GraphQL gem, but it should be done at this layer to ensure that invalid encoding is properly handled.
This commit replaces the Ragel tokenizer with a "hand written" string scanner based tokenizer. This tokenizer is about ~2x faster than the previous tokenizer.
To test, I used this benchmark:
https://gist.github.com/tenderlove/fdce1610a3eecd8426f5845391a6c373
On this branch:
On master:
To ensure compatibility I ran this tokenizer in parallel with the existing tokenizer and compared the results. There is one difference that I think is acceptable and that is when the tokenizer encounters unknown input.
For example:
Output on master is this:
Output on my branch is this:
This is because Ragel only understands byte streams where Ruby knows we have a UTF-8 string.
I didn't make many changes to the helper functions that were originally included in the Ragel parser. Now that we're not working with byte arrays, I think could probably improve the code in those helper functions too.