Short text compression algorithm for utf-8 (optimized for Chinese , developed based on rust programming language).
面向utf-8的短文本压缩算法(为中文优化,基于rust编程语言开发)。
注意:rmw-utf8 只能压缩utf-8文本,不是通用的二进制压缩算法
use rmw_utf8::{decode, encode};
fn main() {
let txt = "测试一下";
let compressed = encode(&txt.as_bytes());
let decompressed = decode(&compressed[..]);
assert!(txt == decompressed);
}#include compress_test/test.txt测试机器为 MacBook Pro 2015 ( 2.2 GHz Intel Core i7 )
测试代码见 compress_test
压缩会把文本中的\r\n和\r都替换为\n,也就是说,压缩和解压的文本未必完全等同。
\r是回车,\n是换行,前者使光标到行首,后者使光标下移一格。
很久很久以前,在计算机还没诞生,有一种机器叫做电传打字机(Teletype Model),每秒钟可以打10个字符。
它有个问题,就是换行要0.2秒。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。
于是,研发人员想了个办法,就是在每行后面加两个表示结束的字符。
一个叫做“回车”,告诉打字机把打印头定位在左边界;另一个叫做“换行”,告诉打字机把纸向下移一行。
这就是“换行”和“回车”的来历。
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。
于是,世界裂开了。
Unix/Linux系统,每行结尾只有“<换行>”,即\n;Windows系统,默认是“<回车><换行>”,即\r\n;Mac系统,默认是“<回车>”也就是\r。
时过境迁,现代的文本编辑器都支持\n作为结尾字符了,所以\r也就没什么存在的必要了。
针对不同语言、不同类型的文本,可以训练一套自己的压缩字典以增强压缩效果。
git clone --depth=1 https://github.com/rmw-link/rmw-utf8.git
cd rmw-utf8
# 在txt目录下放你的准备训练语料,格式为utf8编码的txt文件
cd train
./train.sh没做流式压缩(毕竟我的场景主要是短文本)。
有需要的人可以自己再封装一个流式压缩。
比如每1MB压缩下,压缩后每段开头再记录下压缩后的内容的字节数。
互联网犹如末期的封建王朝,寡头们完成了土地兼并,垄断了人民创造的数据,坐收地租。
我不喜欢这样的世界。我想寻求改变。
我想重新构建一个全新的互联网 :让每个人拥有自己的数据。让人民的数据归属于人民。
于是,我开始了新的个人项目 —— 人民网络。
因为打算从底层重构整个互联网架构,所以,我计划一切都自己从底层搭建。
首先,我封装了sanakirja数据库 —— sdb (这个数据库会崩溃问题还有点多,不推荐现在使用)。
根据sanakirja作者所说,sanakirja比sled要快10倍。
Sanakirja is at least 10 times faster than Sled in my (sequential) benchmarks, and even 20%-50% faster than LMDB (the fastest C equivalent) in the same benchmarks. Also, I started it when there was no real alternative (Sled didn't exist at the time).
我没有实测性能,选sanakirja的原因主要是因为他原生支持rust的数据类型,用起来方便。
而sled或者lmdb,都只支持不定长字符串作为键值,这其中就多了额外的空间开销以及序列化和反序列化的成本。
sanakirja用mmap把存储的文件都映射到了内存,并且每个条目的最大大小为1020字节。
所以比较适合做索引数据库,大段内容可以考虑另开日志存储(比如使用commitlog),然后在sanakirja中记录对应日志存储编号即可。
用来存些短文本,问题也不大(比如140字以内的微博、日常聊天、文件名等等)。
是的,我就打算如此使用。
因为所有内容都被mmap映射到内存(类似lmdb的方案),虽说可以用虚拟内存并不受到物理内存的限制,但普通用户电脑上虚拟内存设置也不大,所以还是节省着用比较好。
所以我希望可以能对以中文为主体的短文本内容做些压缩。
通用压缩算法并不适合短文本的场景,比如我测试了当世最强的压缩算法zstd,经常是把42个字节压缩成为62个字节(是的,没压缩反而放大了),即使训练了字典也不太行(我没搞明白怎么让zstd以3个字节为单位来建立字典,我cat了下zstd的字典,里面都是短句子)。
有一些面向短文本压缩算法,比如shoco、smaz。但这都只对类英文的语言有压缩效果,对短中文依然是放大(他们字典都只有几百个字符,不够用,所以即使重新训练字典也不可行)。
另一种压缩方案就是改文字的编码。
如果有unicode编码有所了解,那么就自然明白utf-8编码方案中一个中文字符需要三个字节的存储空间(其实挺浪费的)。
gb18030中一个中文两个字节,一下子就省了33%的空间。但是gb18030并不涵盖所有的unicode字符(只是utf8的子集),没法用。
有些标准化的unicode压缩编码,比如scsu(SqlServer用的就是这个)、utf-c。
我测试了一下,差不多一个中文两个字节,再外加一个额外字节(比如4个中文大概是2*4+1=9个字节)。
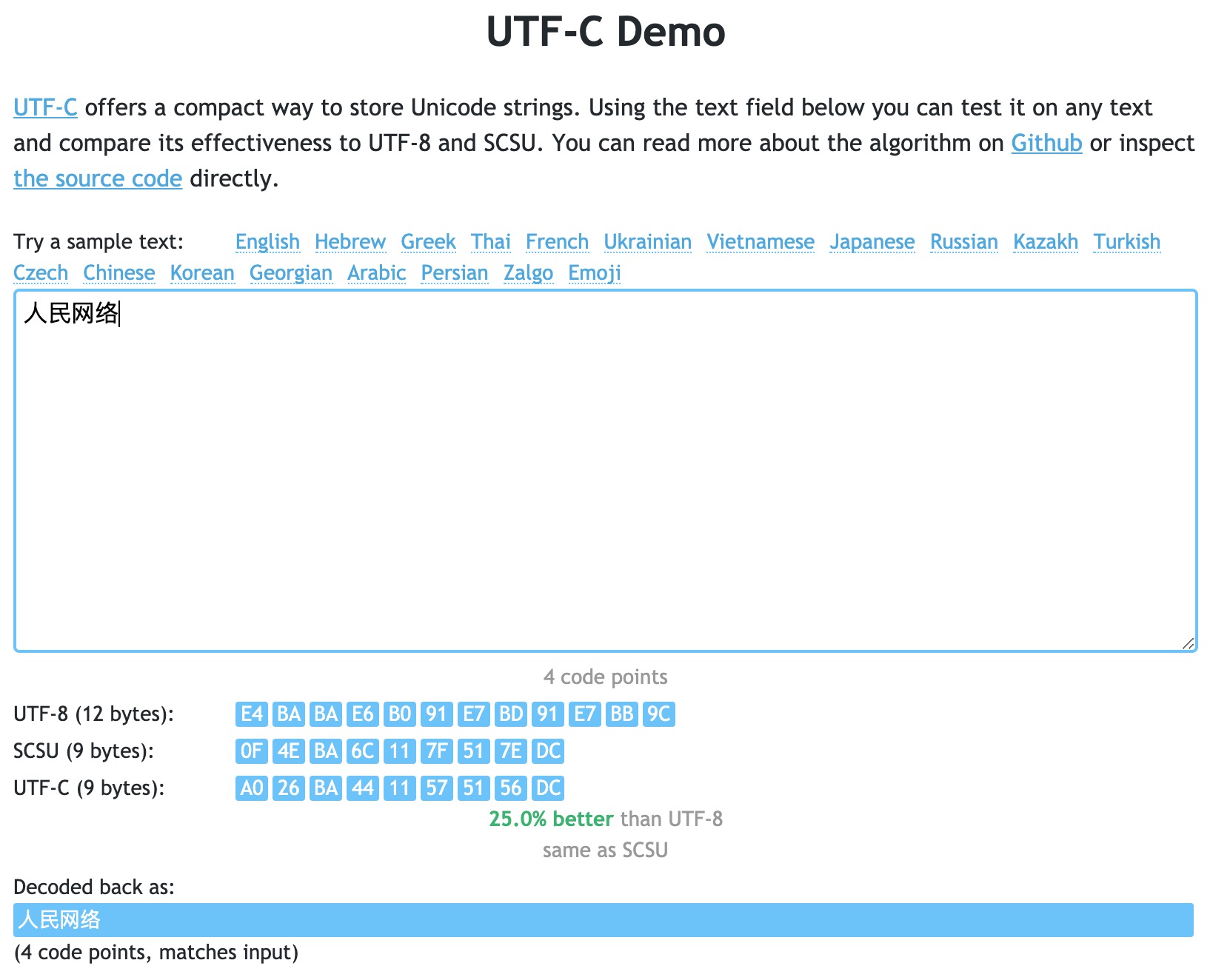
最关键的是,我搜索了全网,没有找到这两种编码的rust实现。
自己写这些编码的rust实现也不是不可以,但是这都需要对unicode各种语言的码表区间有比较深入的理解,学习成本高,躺平、不想学、搞不定。
于是我想,能不能做个更通用更优的编码压缩方案。
unicode字符数是固定已知的,unicode-13.0.0方案有143859个字符(参见这里)。
完全可以统计下每个字的出现频率,然后用霍夫曼编码来压缩。
于是,用了一些中文语料,开始统计字频率。
语料如下:
- 维基百科中文语料
- FictionDown网络小说爬虫(release版本会重复不断抓取失效的章节,所以需要用master版本
go get github.com/ma6254/FictionDown@master) - 微博爬虫
- BT网络的DHT爬虫
- 几个随手写的爬虫,见代码spider目录
小试牛刀,效果不错,三个中文可以压到5个字节,已经超出gb18030的压缩效果了。
我进一步遐想,是不是可以把常用的词也加到霍夫曼的字典中去,进一步优化压缩效果。
于是,就用分词+ngram参见train目录下的训练算法做了一个带常用的词的字典(压缩后500多KB)。
试了试效果,碾压市面上一切压缩算法。
酷。
编码问题到此为止。
继续写人民网络去。