Can't get sparklyr to connect with Shiny #1100
Comments
|
@asodemann If Spark is already installed in the cluster, using |
|
Thanks for responding! How do I change the permissions? I also tried this method: |
|
@asodemann by permissions I mean using You can also reach me out under http://gitter.im/rstudio/sparklyr for a more responsive answer. |
|
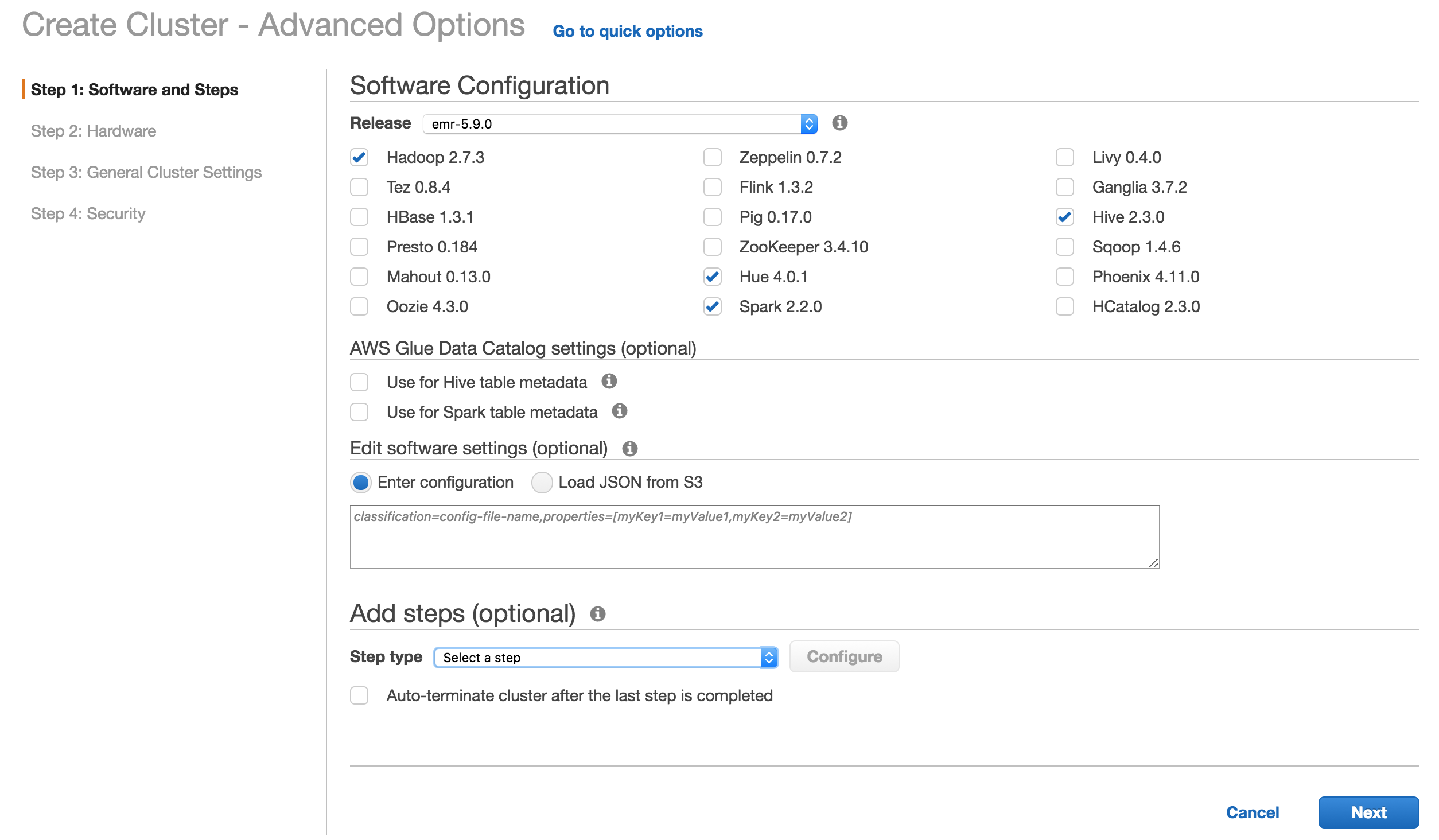
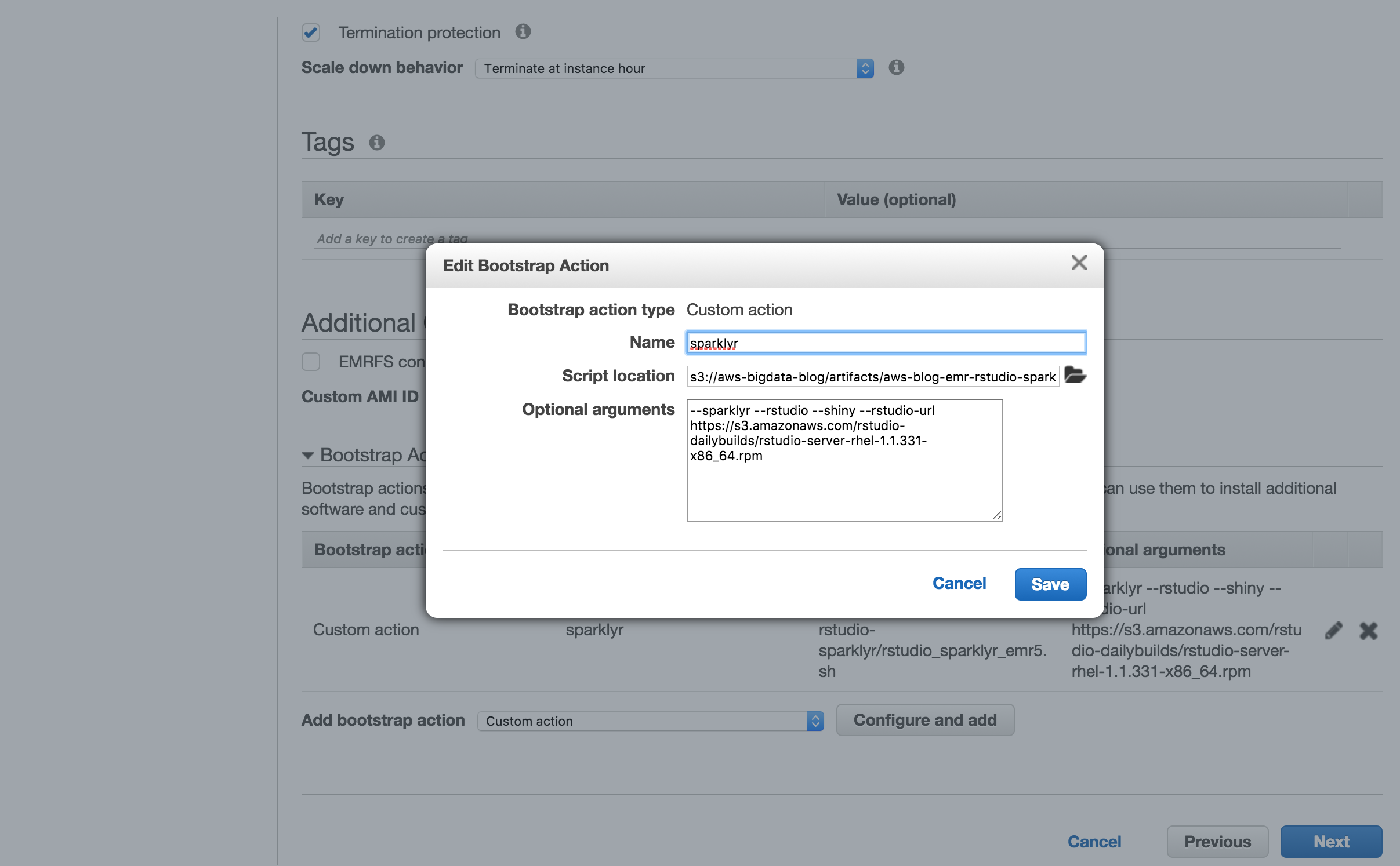
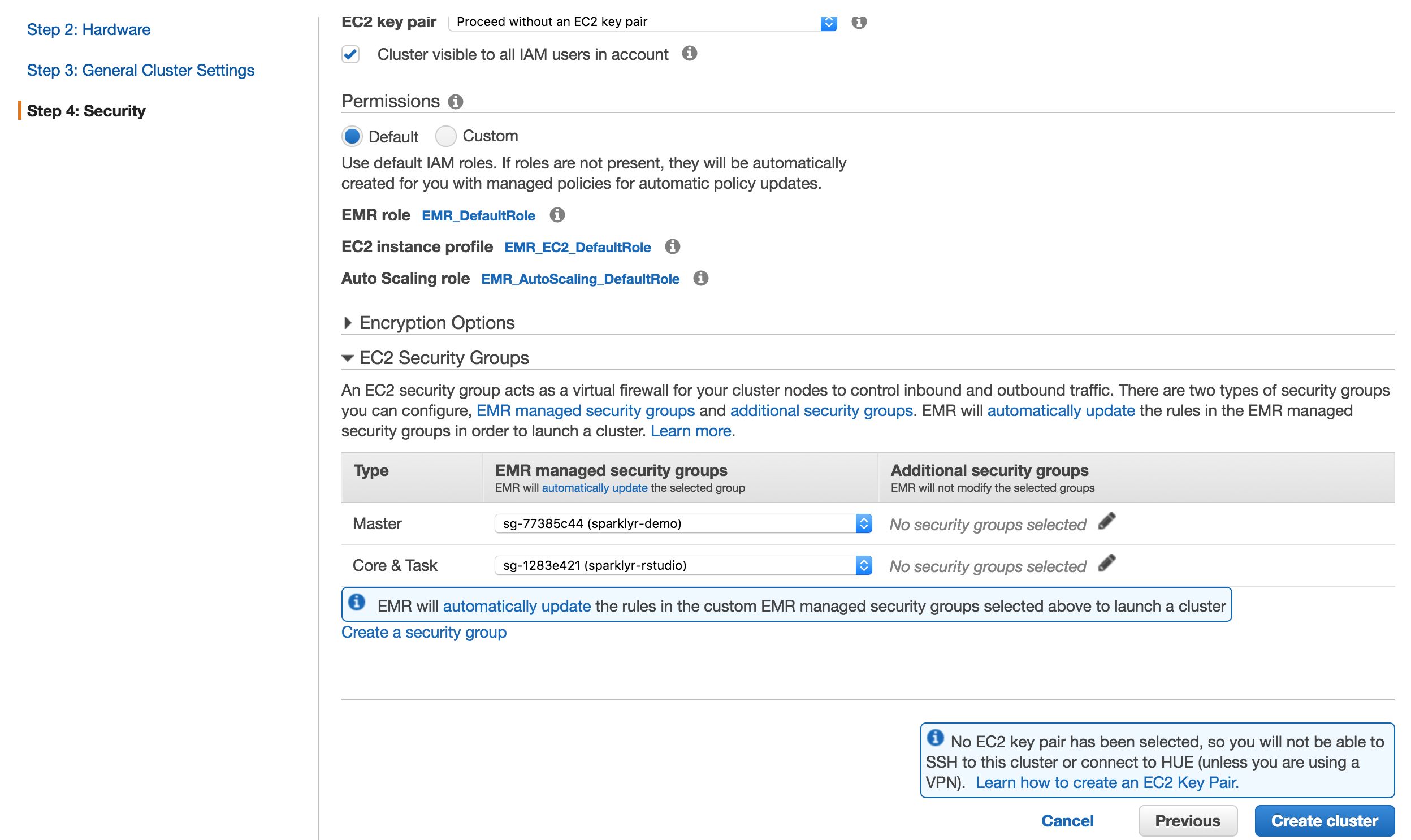
@asodemann here is a step-by-step guide... could you try getting this running and then modify the this base shiny app to match your current one? Reference: hadoop dfs -mkdir /user/hadoop2 Step 1 - Create EMR Cluster
For convenience, here is the bootstrap action: and
Notice that I created a security group with access to all ports, as a test. Step 2 - Validate RStudio and Shiny Server workNavigate to RStudio: http://ec2-54-184-5-###.us-west-2.compute.amazonaws.com:8787/ Navigate to Shiny: http://ec2-54-184-5-###.us-west-2.compute.amazonaws.com:3838/ Both apps should load fine. Step 3 - Create Shiny App that uses sparklyr from RStudioLog in to RStudio, create a new shiny app. Then modify this to: Notice that I've only changed these lines from the sample RStudio creates: and Step 4 - Give access to shiny user in HadoopUsing the RStudio terminal panel, run: Step 5 - Deploy Shiny appIn my case I ran from the RStudio terminal: Navigate to: http://ec2-54-184-5-###.us-west-2.compute.amazonaws.com:3838/sample-apps/sparklyr
|


|
I was able to get it to work with these steps. Thank you!!! @javierluraschi |
|
@asodemann No problem, glad we could help! Closing. |
|
@javierluraschi We have published a shiny app, but as we are dealing with big data; we need to execute copy_to command of sparklyr only once. Is there a way that we can save 'sc' and make app.r read from it instead of repeatedly making copy_to(sc, filename) command get executed each time the shiny app opens on the browser. |
|
@JasmaB is the "big data" being created by the shiny app user or is it being read from disk locally? If the data is on disk, it makes more sense for Spark to read it directly rather than R-> cc @edgararuiz |
|
Dear Kevin Kuo,
Thank you for response.
The data is being read from a remote server. We need to read the daily data
from 2012 to 2018 and store locally, do a copy_to once and then make app.r
analyze it. In this way, the waiting time on copy_to can be eliminated
every time app.r is run online.
We have used shiny server & nginx on Ubuntu to publish the shiny app.
Kindly let us know how to proceed.
Regards,
Jasma Balasangameshwara
On Sat, 21 Apr 2018 at 19:29 Kevin Kuo ***@***.***> wrote:
@JasmaB <https://github.com/JasmaB> is the "big data" being created by
the shiny app user or is it being read from disk locally? If the data is on
disk, it makes more sense for Spark to read it directly rather than R->
copy_to().
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#1100 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/APM0DpLsRF5aD0l9FGawD6B2OKJS9ud5ks5tqzs6gaJpZM4QM3gR>
.
--
Best,
Jasma Balasangameshwara
A good educator has an unpretentious desire to impart values believed to be
of significance.
- By Jasma
|
I'm pretty new to Shiny and Spark.
I want to deploy a ShinyApp with a spark connection. Everything works how it should when I just hit RunApp, but whenever I try to publish it, I get the error: "Error in value[3L] :
SPARK_HOME directory '/usr/lib/spark' not found
Calls: local ... tryCatch -> tryCatchList -> tryCatchOne ->
Execution halted"
This directory exists on my cluster, so I'm not sure why it's not finding it.
Here's the code I'm trying to publish.
The text was updated successfully, but these errors were encountered: