Speed up YUV->RGBA conversion by utilizing iterators, and processing 2x2 group of pixels at once #9
Conversation
03cd1ce
to
603b674
Compare
|
I have fixed the indexing, removed all the TODOs and added a bunch more comments. |
|
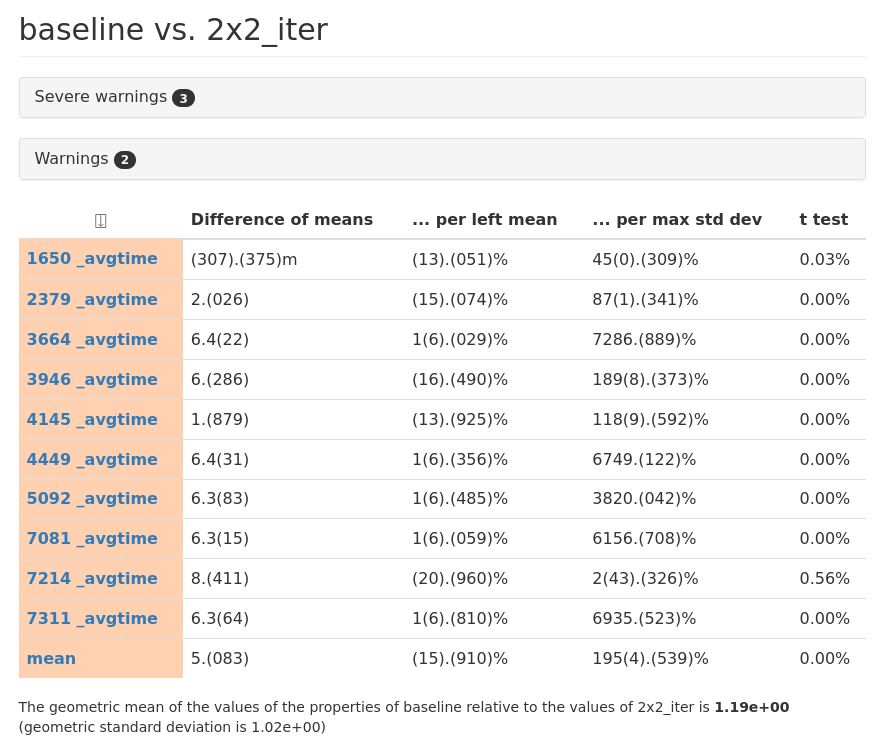
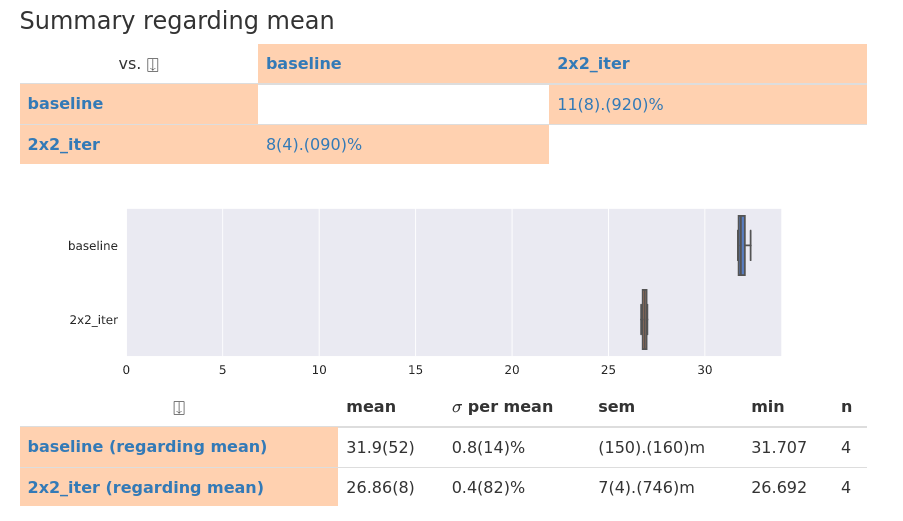
And the benchmarks says:
An almost 16% overall improvement! As measured by the time it takes for |
603b674
to
f838448
Compare
|
While adding tests, I also discovered some off-by-one errors in the results. These were caused by rounding more than necessary. So I switched to a more precise formula to precompute the linear functions, with coefficients taken exactly from the BT.601 standard. (I'm much happier with these, instead of those 5 float literals just copied from a random piece of code somewhere.) Now that all of this goes into a lookup table anyway, the cost of all of these additional computations shouldn't matter that much. (They are only done once, and only on the 256 values of a |
f838448
to
10c62ce
Compare
|
Okay, with even more tests added, I think this is ready for review now! |
10c62ce
to
c99d6d3
Compare
c99d6d3
to
ae7462b
Compare
|
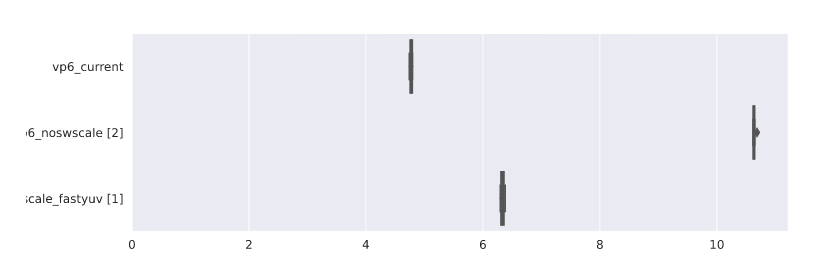
Another point about the performance impact of this PR, this time tested with a VP6 video, with the same methodology as above:
I think the difference is fairly significant: just +32% overall runtime instead of +122% when compared to libswscale |
|
More work needed, see: ruffle-rs/ruffle#3004 (comment) |
|
Replaced by #13, in accordance with the discoveries discussed therein. |
Instead of iterating on plain numbers and computing array indices manually (hence forcing continuous bounds checks everywhere), a parallel iteration scheme is set up on two consecutive lines of all three input, and the output array, at once. Each of these iterators yields two neighboring samples/pixels to work with (in a nice, symmetric, square arrangement), so with each iteration we have 4 of every operand.
There is no clipping of coordinates anywhere, as they are not needed - the pixels are split into 3 different "classes" (bulk, edge, corner; with bilinear, linear, and no interpolation; in this order), and indexing for them is always handled appropriately. There is also not a single
unsafein sight, yay!The two-stage bilinear interpolation (with wider intermediates) results in only one division per pixel, instead of two, which is nice.
Please don't look at the commit history just yet, I'll squash it neatly once everything works well.Benchmark numbers and fancy explainer diagrams will follow. I expect around an overall 15% speedup yet again, as measured on three hand-picked z0r loops.
EDIT: Commit history cleaned up, benchmarks and explainers added.
Note that the indexing inprocess_edge_colis simply WRONG right now, so the left and right (one or two) columns of pixels are incorrect in the output.EDIT: This is fixed.
The processing of 4 pixels at a time in an identical manner (just in different "directions") also lends itself nicely to SIMD in the future (perhaps even to autovectorization right now, but I haven't checked that), although 16 bit operands on 4 parallel lanes is still only 64 bits total, which is half of the 128 bits available in WASM SIMD.
This supersedes #6.